다음과 같은 개발자인 경우 Couchbase를 처음 사용하는 경우 이 문서가 시작하는 데 도움이 됩니다.
이 주간 연습 시리즈는 CouchBase 연결의 기본 사항을 이해하는 데 도움이 되며, CouchBase Server에서 데이터를 검색하고 수정하는 방법, 다음을 사용하는 방법을 보여 줍니다. SQL++ 쿼리 언어 (이전의 N1QL) 등을 살펴봅니다. 이번 주에는 예제 코드에 Java가 등장하며, Couchbase Java SDK를 사용할 예정입니다.
카우치베이스 는 분산형입니다, JSON 문서 데이터베이스. 밀리초 미만의 데이터 작업을 위한 관리형 캐시를 갖춘 스케일아웃 키-값 저장소, 효율적인 쿼리를 위한 특수 제작된 인덱서, SQL과 유사한 쿼리를 실행하기 위한 강력한 쿼리 엔진을 제공합니다.
이 개발자 워크스루에서는 비관계형 JSON 인터페이스와 관계형 SQL 인터페이스를 통해 Couchbase의 기본 기능에 대해 살펴봅니다. Couchbase는 샘플 데이터베이스와 함께 제공됩니다, 여행 샘플이 샘플 데이터 세트를 사용하여 Java SDK를 사용하여 Couchbase의 기본 사항을 배우겠습니다.
여행 샘플 데이터 세트 이해
더 나은 이해를 위해 여행 샘플 데이터 집합이 어떻게 생겼는지, 자유롭게 Java SDK 문서에서 이에 대해 읽어보세요: 여행 앱 데이터 모델.
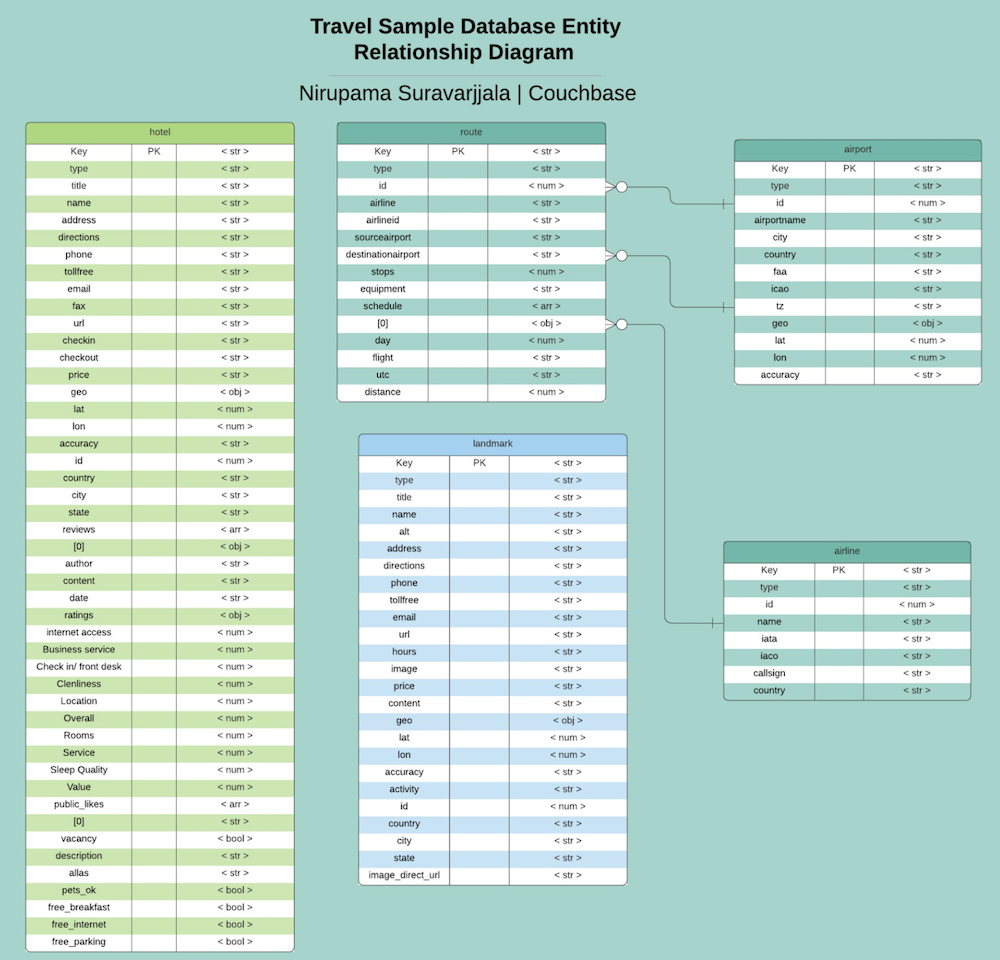
아래는 엔티티 관계 다이어그램입니다. 여행 샘플 데이터 집합과 함께 제공되는 데이터 모델입니다:

키-값 가져오기 함수를 사용하여 데이터를 검색하는 방법
키-값(카우치베이스 데이터 서비스라고도 함)은 키를 알고 있는 데이터를 검색하거나 변경하는 가장 간단한 방법을 제공합니다. 키-값 저장소는 일종의 NoSQL 데이터베이스 키가 고유 식별자 역할을 하는 키-값 쌍의 모음으로 데이터를 저장하는 간단한 방법을 사용합니다.
카우치베이스 서버 는 저장되는 내용에 구애받지 않는 키-값 저장소입니다. 아래 예시는 키-값 저장소를 사용하는 방법을 보여줍니다. get 함수를 사용하여 백엔드에서 데이터를 검색할 수 있습니다.
계속 진행하기 전에 인증 및 Couchbase 클러스터 연결에 대한 기본 사항을 숙지하고 있는지 확인하세요. Couchbase 설명서의 "Java SDK 사용 시작" 섹션을 읽어보세요. 를 클릭하세요.
다음은 필요한 세 가지 가져오기입니다:
|
1 2 3 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; |
다음으로 검색하려는 데이터를 저장하는 클러스터에 연결합니다. Java를 사용하고 있으므로 먼저 클래스와 메인 메서드를 선언해야 합니다. 그런 다음 클러스터에 대한 변수를 만듭니다.
아래 예시에서는 클러스터 유형의 변수 이름입니다. var. 연결 문자열을 사용하여 프로그램이 백엔드의 데이터에 연결하도록 합니다. 카우치베이스 연결 문자열은 쉼표로 구분된 IP 주소 및/또는 호스트 이름의 목록으로, 선택적으로 매개변수 목록이 뒤에옵니다. 아래를 참조하세요, couchbase://127.0.0.1 는 하나의 시드 노드 뒤에 사용자 아이디와 비밀번호가 포함된 간단한 연결 문자열입니다. 이 모든 정보를 프로그램과 관련된 정보로 대체해야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
Couchbase Server 클러스터에 대한 연결은 클러스터 개체로 표시됩니다. 클러스터는 버킷에 대한 액세스를 제공합니다, 범위 및 컬렉션뿐만 아니라 다양한 Couchbase 서비스 및 관리 인터페이스를 지원합니다.
위에 연결 문자열, 사용자 이름, 비밀번호를 입력하면 Couchbase 클러스터에 연결되고 이제 Couchbase 버킷 및 컬렉션에 연결할 수 있습니다:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
Java get 메서드를 사용하면 특정 데이터를 검색할 수 있습니다. 문서의 키가 주어지면 문서에서 collection.get() 메서드를 사용하여 컬렉션에서 문서를 검색할 수 있습니다.
이 예제에서는 다음과 같은 컬렉션에서 콘텐츠를 검색하고 있습니다. "airline_10" 를 입력합니다. 그런 다음 결과를 확인하기 위해 인쇄 문을 사용하여 데이터 검색을 완료할 수 있습니다.
|
1 2 3 4 |
try { var result = collection.get("airline_10"); System.out.println(result.toString()); } |
마지막으로, 사용자가 존재하지 않거나 문서 범위 내에 있지 않은 정보를 검색하려고 할 경우를 대비하여 다음과 같은 기능이 있습니다. catch 예외를 사용하여 코드에 오류가 없는지 확인합니다.
|
1 2 3 4 5 |
catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
쿼리 메서드를 사용하여 데이터 검색하기
쿼리는 항상 클러스터 수준에서 수행되며, 특히 쿼리 메서드입니다. 이 메서드는 문을 필수 인수로 받은 다음 필요한 경우 추가 옵션을 제공할 수 있습니다.
결과가 반환되면 반환된 행을 반복하거나 반환된 행에 액세스할 수 있습니다. 쿼리 메타데이터 를 반환합니다. 쿼리를 실행하는 동안 문제가 발생하면 쿼리에서 파생된 카우치베이스 예외 가 던져져 작업에 대한 추가 컨텍스트를 제공합니다.
다음은 필요한 5가지 가져오기 기능입니다:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
다음은 쿼리를 수행하고 결과를 처리하는 예제입니다. 인쇄되는 결과는 다음과 같습니다. "호텔: " 뒤에 호텔 이름, 도시, 주 및 기타 호텔 관련 정보를 입력합니다. 코드에 표시된 행 수 제한 때문에 최대 5행까지만 인쇄됩니다. 다른 쿼리를 테스트하려면 6번째 줄의 도시 이름을 다른 도시로 변경해 보세요.
|
1 2 3 4 5 6 7 8 9 10 11 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = 'hotel' " + "AND h.city = 'Malibu' LIMIT 5;"; QueryResult result = cluster.query(query); for (JsonObject row : result.rowsAsObject()) { System.out.println("Hotel: " + row); } |
이전과 마찬가지로 catch 예외를 사용하면 코드에 오류가 없는지 확인할 수 있습니다. 예를 들어 데이터베이스에 없는 도시를 선택한 경우 이 문서 찾을 수 없음 예외 예외가 인쇄됩니다. "문서를 찾을 수 없습니다!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
명명된 매개변수로 쿼리하는 방법
앞서 언급했듯이 쿼리 메서드를 사용하면 특정 기준에 따라 데이터베이스에서 특정 정보를 검색할 수 있습니다. 쿼리 메서드에는 이름 또는 위치 매개변수가 있을 수 있습니다.
이 섹션에서는 명명된 매개변수가 무엇이며 매개변수가 많은 메서드를 호출할 때 어떻게 유용한지 살펴봅니다. 명명된 매개변수는 메서드를 호출할 때 매개변수의 이름을 명확하게 명시합니다. 명명된 매개변수를 사용하면 사용자가 임의의 하위 집합을 사용하여 메서드를 호출할 수 있으며 나머지 매개변수는 기본값을 사용할 수 있습니다.
다음은 필요한 7가지 가져오기 기능입니다:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
이 코드는 여행 샘플 데이터베이스, 특히 이름, 도시 및 주 버킷에 대해 설명합니다. 그리고 쿼리 옵션() 메서드를 사용하면 다양한 SQL++ 쿼리 옵션을 사용자 지정할 수 있습니다.
아래 코드에서 결과는 유형의 데이터를 다시 가져옵니다: 호텔 그리고 도시: 말리부. 제한이 5개이므로 최대 5행까지만 인쇄됩니다. 인쇄되는 결과는 다음과 같습니다. "호텔: " 를 입력한 후 이름과 도시를 포함한 정보를 입력합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $type " + "AND h.city = $city LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters( JsonObject.create() .put("type", "hotel") .put("city", "Malibu") )); |
결과는 여행 샘플 데이터베이스, 특히 행에서. 특히 .stream 메서드는 JSON 객체의 원래 값을 변경하지 않고 기본 메서드에 따라 요소를 계산하는 데 사용됩니다.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
이전과 마찬가지로 catch 예외를 사용하면 코드에 오류가 없는지 확인할 수 있습니다. 예를 들어, 데이터베이스에 없는 도시나 장소 유형을 선택한 경우 이 카우치베이스 예외 예외가 인쇄됩니다. "예외: " 를 오류의 원인이 되는 객체의 문자열 표현과 함께 입력합니다.
|
1 2 3 4 5 |
} catch (CouchbaseException ex) { System.out.println("Exception: " + ex.toString()); } } } |
위치 매개변수로 쿼리하는 방법
앞서 언급했듯이 쿼리 메서드에는 명명된 매개변수 또는 위치 매개변수가 있을 수 있습니다. 명명된 매개변수는 위에서 다루었습니다.
이 섹션에서는 위치 매개변수와 방대한 수의 매개변수가 있는 메서드를 호출할 때 위치 매개변수가 어떻게 유용한지 살펴보겠습니다. 위치 매개변수를 사용하면 메서드 매개변수의 순서를 플레이스홀더로 대체할 수 있습니다.
예를 들어 첫 번째 자리 표시자는 첫 번째 메서드 매개변수로 대체되고, 두 번째 자리 표시자는 두 번째 메서드 매개변수로 대체되는 식입니다.
다음은 필요한 7가지 가져오기 기능입니다:
|
1 2 3 4 5 6 7 |
import com.couchbase.client.core.error.CouchbaseException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.json.JsonArray; import com.couchbase.client.java.query.QueryResult; import com.couchbase.client.java.query.QueryOptions; import static com.couchbase.client.java.query.QueryOptions.queryOptions; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 |
var bucket = cluster.bucket("travel-sample"); |
아래 쿼리는 다음에서 이름, 도시 및 주를 검색합니다. 여행 샘플 데이터베이스에 장소 유형과 도시를 구체적으로 고려하여 검색합니다. 나중에 말리부에 있는 호텔로 표시됩니다.
|
1 2 3 4 5 6 7 8 9 |
try { var query = "SELECT h.name, h.city, h.state " + "FROM `travel-sample` h " + "WHERE h.type = $1 " + "AND h.city = $2 LIMIT 5;"; QueryResult result = cluster.query(query, queryOptions().parameters(JsonArray.from("hotel", "Malibu")) ); |
위의 명명된 매개변수 예제와 마찬가지로 .stream 메서드는 JSON 객체의 원래 값을 변경하지 않고 기본 메서드에 따라 요소를 계산하는 데 사용됩니다.
|
1 2 3 4 |
result.rowsAsObject().stream().forEach( e-> System.out.println( "Hotel: " + e.getString("name") + ", " + e.getString("city")) ); |
하위 문서 조회 작업을 사용하는 방법
하위 문서 는 원자 단위로 효율적으로 업데이트하고 검색할 수 있는 JSON 문서의 일부입니다.
전체 문서 검색은 전체 문서를 검색하고 전체 문서 업데이트는 전체 문서를 전송해야 하는 반면, 하위 문서 검색은 문서의 관련 부분만 검색하고 하위 문서 업데이트는 문서의 업데이트된 부분만 전송하면 됩니다. 문서의 일부만 수정할 때는 하위 문서 작업을, 문서의 내용이 크게 변경될 때는 전체 문서 작업을 사용해야 합니다.
이 문서에서 설명하는 하위 문서 작업은 다음과 같습니다. 키-값 요청만하위 문서 SQL++ 쿼리와는 관련이 없습니다. 하위 문서 작업을 사용하려면 하위 문서의 위치를 나타내는 경로를 지정해야 합니다.
그리고 룩업인 연산은 문서에서 특정 경로를 쿼리하여 해당 경로를 반환합니다. 실제로 문서 경로를 검색하는 방법은 하위 문서 get 하위 문서 작업을 수행하거나 단순히 경로의 존재를 쿼리하기 위해 하위 문서가 존재합니다. 하위 문서 작업. 후자는 필요하지 않은 경우 경로의 내용을 검색하지 않음으로써 더 많은 대역폭을 절약할 수 있습니다.
다음은 필요한 5가지 가져오기 기능입니다:
|
1 2 3 4 5 |
import com.couchbase.client.core.error.DocumentNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import java.util.Collections; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
아래 코드에서 룩업인연산은 airport_1254 문서에 특정 경로에 대한 geo.alt 경로를 추가합니다. 이 코드를 사용하면 문서 경로를 검색할 수 있습니다. 하위 문서 가져오기 하위 문서 작업: (get("geo.alt")).
|
1 2 3 4 5 6 7 8 |
try { LookupInResult result = collection.lookupIn( "airport_1254", Collections.singletonList(get("geo.alt")) ); var str = result.contentAs(0, String.class); System.out.println("Altitude = " + str); |
이전과 마찬가지로 catch 예외를 사용하면 코드에 오류가 없는지 확인할 수 있습니다. 예를 들어, 데이터베이스에 없는 도시를 선택한 경우 문서 찾을 수 없음 예외 예외가 인쇄됩니다. "문서를 찾을 수 없습니다!".
|
1 2 3 4 5 |
} catch (DocumentNotFoundException ex) { System.out.println("Document not found!"); } } } |
하위 문서 변경 작업 사용 방법
하위 문서 변경 작업은 문서에서 하나 이상의 경로를 수정합니다.
이러한 작업 중 가장 간단한 작업은 서브닥 업서트. 풀독 수준의 업서트와 마찬가지로 서브닥 업서트 연산은 기존 경로의 값을 수정하거나 경로가 존재하지 않는 경우 경로를 생성합니다. 마찬가지로 하위 문서 삽입 연산은 경로에 새 값이 없는 경우에만 경로에 새 값을 추가합니다.
다음은 필요한 8가지 가져오기 기능입니다:
|
1 2 3 4 5 6 7 8 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.core.error.subdoc.PathExistsException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; import java.util.Arrays; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
아래 코드에서 mutateIn 연산은 "airline_10" 매개 변수가 있는 기존 경로의 값을 생성하는 풀독 수준의 업서트를 사용하여 ("국가", "캐나다").
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc before: "); System.out.println(str); } catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } try { collection.mutateIn("airline_10", Arrays.asList( upsert("country", "Canada") )); } catch (PathExistsException e) { System.out.println("Sub-doc path exists!"); } try { LookupInResult result = collection.lookupIn( "airline_10", Collections.singletonList(get("country")) ); var str = result.contentAs(0, String.class); System.out.println("Sub-doc after: "); System.out.println(str); |
이전과 마찬가지로 catch 예외를 사용하면 코드에 오류가 없는지 확인할 수 있습니다. 예를 들어 로컬 컴퓨터에 경로가 없는 문서를 선택한 경우 이 PathNotFoundException 예외가 인쇄됩니다. "하위 문서 경로를 찾을 수 없습니다!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException e) { System.out.println("Sub-doc path not found!"); } } } |
업서트 기능 사용 방법
업서트 기능 은 새 레코드를 삽입하거나 기존 레코드를 업데이트하는 데 사용됩니다. 문서가 존재하지 않으면 문서가 생성됩니다. 업서트는 삽입 그리고 업데이트.
실행하는 사용자 업서트 문에는 대상 키 공간에 대한 쿼리 업데이트 및 쿼리 삽입 권한이 있어야 합니다. 문에 반환 절이 있는 경우 각 절에 참조된 키 스페이스에 대한 쿼리 선택 권한도 필요합니다. 사용자 역할에 대한 자세한 내용은 사용자 역할을 참조하세요, 카우치베이스의 역할 기반 액세스 제어(RBAC)에 대한 권한 부여 설명서를 참조하세요..
다음은 모든 업서트 연산에 대한 기본 구문을 보여주는 다이어그램입니다:

다음은 필요한 9가지 가져오기 기능입니다:
|
1 2 3 4 5 6 7 8 9 |
import com.couchbase.client.core.error.subdoc.PathNotFoundException; import com.couchbase.client.java.*; import com.couchbase.client.java.kv.*; import com.couchbase.client.java.kv.MutationResult; import com.couchbase.client.java.json.JsonObject; import com.couchbase.client.java.kv.LookupInResult; import static com.couchbase.client.java.kv.LookupInSpec.get; import static com.couchbase.client.java.kv.MutateInSpec.upsert; import java.util.Collections; |
그런 다음 이전과 비슷한 단계에 따라 검색하려는 데이터를 저장하는 클러스터에 연결합니다. 이 모든 정보를 프로그램과 관련된 정보로 바꾸어야 합니다.
|
1 2 3 4 5 |
class Program { public static void main(String[] args) { var cluster = Cluster.connect( "couchbase://127.0.0.1", "username", "password" ); |
이전과 마찬가지로 Couchbase 클러스터에 연결되어 있으며 이제 Couchbase 버킷에 연결할 수 있습니다:
|
1 2 |
var bucket = cluster.bucket("travel-sample"); var collection = bucket.defaultCollection(); |
그리고 .put 메서드를 사용하면 사용자가 맵에 매핑을 삽입할 수 있습니다. 즉, 특정 키(및 매핑되는 값)를 특정 맵에 삽입할 수 있습니다. 기존 키가 전달되면 이전 값이 새 값으로 대체됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
JsonObject content = JsonObject.create() .put("country", "Iceland") .put("callsign", "ICEAIR") .put("iata", "FI") .put("icao", "ICE") .put("id", 123) .put("name", "Icelandair") .put("type", "airline"); collection.upsert("airline_123", content); try { LookupInResult lookupResult = collection.lookupIn( "airline_123", Collections.singletonList(get("name")) ); var str = lookupResult.contentAs(0, String.class); System.out.println("New Document name = " + str); |
이전과 마찬가지로 catch 예외를 사용하면 코드에 오류가 없는지 확인할 수 있습니다. 예를 들어 로컬 컴퓨터에 경로가 없는 문서를 선택한 경우 이 PathNotFoundException 예외가 인쇄됩니다. "문서를 찾을 수 없습니다!".
|
1 2 3 4 5 6 |
} catch (PathNotFoundException ex) { System.out.println("Document not found!"); } } } |
결론
이 입문 단계의 안내를 통해 Couchbase 및 Java SDK로 작업할 때 가장 일반적인 기능 중 일부를 이해하고 실행하는 데 도움이 되었기를 바랍니다. 중급 및 고급 단계로 들어가려면 다음과 같이 하세요, 여기에서 Java SDK 설명서를 확인하세요..
도움이 필요하거나 영감이 필요한 경우, 카우치베이스 포럼을 확인하세요. 커뮤니티에서 같은 생각을 가진 개발자들과 소통하세요.
다음 단계로 무료로 제공되는 온라인 카우치베이스 준회원 자바 개발자 자격증 과정 제공처 카우치베이스 아카데미.
지금 Couchbase 7 시작하기
