Introducción
Desde hace un par de semanas, tengo Spark en la cabeza. Es comprensible, en realidad, ya que he estado preparando un webinar de O'Reilly "Cómo aprovechar Spark y NoSQL para aplicaciones basadas en datos" con Michael Nitschinger y otra charla, "Spark y Couchbase: Augmenting the Operational Database with Spark" para Cumbre Spark 2016 con Matt Ingenthron. En otro lugar puede informarse sobre la Conector Spark de Couchbasequé contiene nuestra nueva versión y cómo utilizarla. En este blog, quiero hablar de por qué la mejor combinación de base de datos es Apache Spark y un Base de datos NoSQL hacen una buena combinación.
Chispa 101
Si no está familiarizado con él, Chispa es un marco de procesamiento de big data que realiza análisis, aprendizaje automático, procesamiento de gráficos y mucho más sobre grandes volúmenes de datos. Es similar a Map Reduce, Hive, Impala, Mahout y las demás capas de procesamiento de datos construidas sobre HDFS en Hadoop. Al igual que Hadoop, se centra en la optimización a través de, pero mejor en muchos aspectos: es en general más rápido, mucho más agradable de programar, y tiene buenos conectores a casi todo. A diferencia de Hadoop, es fácil empezar a escribir y ejecutar Spark desde la línea de comandos de tu portátil y luego desplegarlo en un clúster para ejecutarlo en un conjunto de datos completo.
Lo que he dicho hasta ahora puede hacer que parezca que Spark es una base de datos, pero es rotundamente no una base de datos. En realidad es un motor de procesamiento de datos. Spark lee datos en masa que se almacena en algún lugar como HDFS, Amazon S3 o Couchbase Server, realiza algún tipo de procesamiento en esos datos, y luego escribe sus resultados para que puedan ser utilizados más adelante. Es un sistema basado en trabajos, como Hadoop, en lugar de un sistema en línea, como Couchbase u Oracle. Esto significa que Spark siempre tiene un coste inicial que lo descarta para cargas de trabajo rápidas de tipo lectura/escritura aleatoria. Al igual que Hadoop, Spark es genial en lo que respecta al rendimiento general del sistema, pero a costa de la latencia.
En resumen, Couchbase Server y Spark resuelven problemas diferentes pero ambos son buenos problemas para resolver. Hablemos de por qué la gente los usa juntos.
Caso de uso #1 de NoSQL y Spark: Operacionalización de la Analítica / Aprendizaje Automático
No hay duda: los datos son un gran material. Las grandes aplicaciones en línea que se ejecutan en Couchbase tienden a tener un montón de ellos. La gente crea más datos cada día cuando compra por Internet, reserva viajes o se envía mensajes. Cuando navego por un catálogo de productos y pongo una nueva lente de cámara en mi carrito, alguna información tiene que ser almacenada en Couchbase para que pueda completar mi compra y recibir mis nuevas golosinas por correo.
Se pueden hacer muchas más cosas con los datos de mi viaje de compras que son invisibles para mí: se analizan para ver qué productos se compran juntos habitualmente, de modo que la siguiente persona que ponga ese objetivo en su cesta de la compra reciba mejores recomendaciones de productos para que tenga más probabilidades de comprar. Puede que se compruebe si hay indicios de fraude para ayudar a protegerme a mí y al minorista de los malos. Puede que se rastree para averiguar si necesito un cupón o algún otro incentivo para completar una compra sobre la que, de otro modo, estoy indeciso. Todos estos son ejemplos de aprendizaje automático y minería de datos que las empresas pueden realizar con Spark.
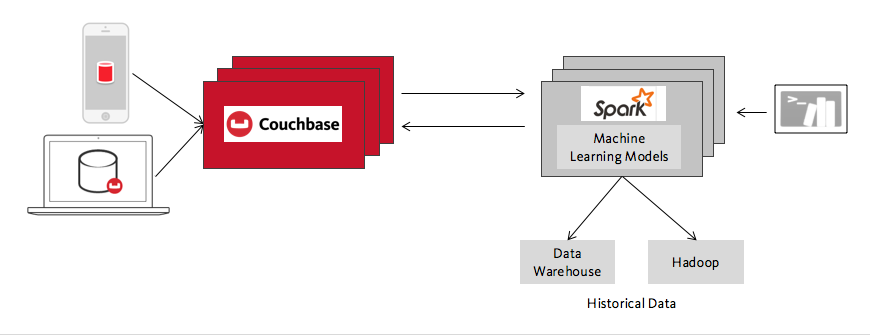
En esta amplia familia de casos de uso, Spark proporciona modelos de aprendizaje automático, predicciones, los resultados de grandes trabajos de análisis, etc., y Couchbase los hace interactivos y los escala a un gran número de usuarios. Otros ejemplos, además de las recomendaciones de compra online, son los clasificadores de spam para aplicaciones de comunicación en tiempo real, los análisis predictivos que personalizan las listas de reproducción para los usuarios de una aplicación de música online y los modelos de detección de fraudes para aplicaciones móviles que necesitan tomar decisiones instantáneas para aceptar o rechazar un pago. También incluiría en esta categoría un amplio grupo de aplicaciones que son realmente almacenamiento de datos de "nueva generación", donde grandes cantidades de datos necesitan ser procesados a bajo coste y luego servidos de forma interactiva a muchos, muchos usuarios. Por último, los escenarios del Internet de las cosas también encajan aquí, con la diferencia obvia de que los datos representan las acciones de máquinas en lugar de personas.
Lo que todos estos casos de uso tienen en común técnicamente es la división en una base de datos operativa y un clúster de procesamiento analítico, cada uno optimizado para su carga de trabajo. Esta división es como la división entre sistemas OLTP y OLAP, actualizada para la era del big data. Ya hemos hablado de la parte analítica Spark, ahora hablemos de Couchbase y la parte operativa.
Couchbase: Acceso rápido a datos operativos a escala
Couchbase Server se creó para ejecutar aplicaciones que son rápidas, escalables, fáciles de gestionar y lo suficientemente ágiles como para evolucionar junto con los requisitos de tu negocio. Los tipos de aplicaciones que tienden a utilizar Spark machine learning y analytics también tienden a necesitar las capacidades que ofrece Couchbase:
- Modelo de datos flexible, esquemas dinámicos
- Potente lenguaje de consulta (N1QL)
- SDK nativos
- Latencias inferiores a un milisegundo para operaciones con valores clave a escala
- Escalado elástico
- Facilidad de administración
- XDCR (Replicación entre centros de datos)
- Alta disponibilidad y distribución geográfica
La capa de procesamiento de datos operativos debe distribuirse por motivos de resistencia, alta disponibilidad y rendimiento, ya que la proximidad a la ubicación geográfica del usuario es importante. El mecanismo de distribución debe ser transparente para los desarrolladores y sencillo de utilizar. Todas estas propiedades, que son válidas tanto si se utiliza Spark como si no, han sido tratado ampliamente en otro lugar.
El conector Spark de Couchbase proporciona una integración de código abierto entre las dos tecnologías, y tiene algunas ventajas propias:
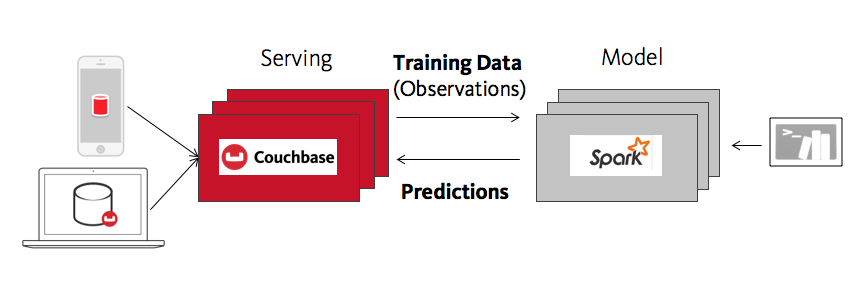
- Centrado en la memoria. Tanto Spark como Couchbase se centran en la memoria. Esto puede reducir significativamente el tiempo de procesamiento de los datos en el primer viaje de ida y vuelta, o reducir también el tiempo de perspicacia / tiempo de acción de extremo a extremo. El tiempo de obtención de información se refiere al viaje de ida y vuelta desde "hacer una observación" (almacenar algunos datos sobre lo que hace un usuario o una máquina) hasta analizar esos datos, a menudo en el contexto de la creación o actualización de un modelo de aprendizaje automático, y luego devolverlos al usuario de forma que puedan utilizarlos, como una predicción nueva y mejorada.
- Rápido. Además del hecho de que tanto Spark como Couchbase se centran en la memoria, el conector Spark de Couchbase incluye una serie de mejoras de rendimiento, como el push down de predicados, la localización de datos y el conocimiento de la topología, subdocumento API y dosificación implícita.
- Funcionalidad. Couchbase Spark Connector te permite utilizar toda la gama de métodos de acceso a datos para trabajar con datos en Spark y Couchbase Server: RDDs, DataFrames, Datasets, DStreams, operaciones KV, consultas N1QL, Map Reduce y Spatial Views, e incluso DCP son soportados desde Scala y Java.
Caso de uso NoSQL y Spark #2: Conjunto de herramientas de integración de datos
La amplia gama de funcionalidades soportadas por Couchbase Spark Connector nos lleva al otro gran caso de uso para Spark y Couchbase: Integración de datos.
El interés en Spark se ha disparado en los últimos años, con el resultado de que Spark se conecta a casi todo, desde bases de datos a Elasticsearch a Kafka a HDFS a Amazon S3 y mucho más. También puede leer datos en casi cualquier formato, como Parquet, Avro, CSV, Apache Arrow, etc. Toda esta conectividad convierte a Spark en un gran conjunto de herramientas para resolver retos de integración de datos.
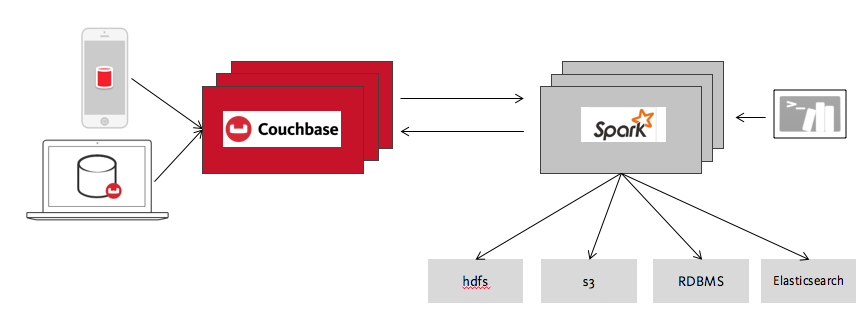
Por ejemplo, imagine que es ingeniero de datos. Necesitas cargar información sobre los intereses de tus usuarios en sus perfiles de usuario para dar soporte a una nueva característica premium que estás añadiendo a tu aplicación móvil. Digamos que tus perfiles de usuario están en Couchbase Server, tus intereses de usuario vendrán de HDFS y tu lista de usuarios premium se basa en la información de pago en tu almacén de datos.
Esto parece una tarea relativamente sencilla pero tediosa, en la que hay que ir a cada sistema por turno para volcar la información que se necesita y luego importarla al sistema siguiente. Spark ofrece una práctica alternativa. Una vez que conozcas el sistema, puedes realizar esta tarea utilizando unas cuantas consultas sencillas desde tu línea de comandos. Usando las capacidades nativas de cada uno de los sistemas, puedes JOIN las tablas en Spark y escribir los resultados a Couchbase en un solo paso. No puede ser más cómodo. Los mismos pasos se pueden escalar para crear pipelines de datos que combinan datos de múltiples fuentes y los alimentan a aplicaciones u otros consumidores.
Pruébalo
Tanto si estás desarrollando una gran aplicación con aprendizaje automático sofisticado como parte de un gran equipo de ingeniería como si eres un desarrollador lobo solitario, Spark y Couchbase tienen algo que ofrecerte. Pruébalo y danos tu opinión. Como siempre, nos gusta saber de ti. ¡Feliz codificación!
[...] ¿Todavía te preguntas por qué Spark y NoSQL? [...]