Este artículo se basa en la sesión "When Couchbase meets Splunk, the real-time, AI-driven data analytics platform" presentada en Couchbase Connect Online 2020 por James Powenski y Andrea Vasco.
El muro de la confusión
Desde que era estudiante universitario, siempre me había fascinado la ciencia de datos. Por aquel entonces, aún no era algo de lo que uno presumiera, pero aún recuerdo cómo me sentí la primera vez que me topé con la teoría de la estimación.
Ahora vivimos en la Edad de Oro de los Datos, una era en la que los conjuntos de datos crecieron exponencialmente, poniéndose a disposición del público; hoy en día, muchas grandes plataformas ofrecen formas racionalizadas de aprovechar el aprendizaje automático y las técnicas de aprendizaje profundo para llevar el proceso de toma de decisiones a un nivel sobrehumano.
Escala multidimensional (MDS) es una de mis características preferidas de Couchbase, con un punto débil para el aislamiento de cargas de trabajo de indexación, consulta y análisis: Pasé varios años extrayendo datos en bases de datos relacionales en busca de patrones y correlaciones en grandes conjuntos de datos, y muchas veces me encontré - no hace falta decirlo - ejecutando consultas complejas que generaban fricciones con los DBAs sobre bloqueos, degradación del rendimiento, etc.
Golpeé fuerte en el llamado Muro de la confusiónSupongo. Este problema era (y es) también tan querido para mí que en 2013 nos escribió un artículo sobre la desmitificación de la caracterización de las cargas de trabajo de Oracle.
Preparar el terreno: introducir la Inteligencia Continua en ACME
En 2019, Gartner identificó Inteligencia continua como Top-10 Tendencia analíticaestimando que para 2022 "más del 50% de todas las iniciativas empresariales requerirán inteligencia continua, aprovechando los datos en flujo para mejorar la toma de decisiones en tiempo real".
En este artículo -y serie- te guiaremos a través de una forma práctica de iniciarte en la Inteligencia Continua con Couchbase, con el objetivo de disrumpir tu negocio hacia la transformación digital sin impactar significativamente en tu operativa diaria; simularemos ser un Ingeniero de fiabilidad del sitio (SRE) en ACME Inc., encargada de la misión de implantar la Inteligencia Continua para la tienda en línea de ACME.
Partimos de la base de que tiene conocimientos básicos de Análisis de Couchbase. Como se muestra en la siguiente imagen, Couchbase Analytics permite crear, en tiempo real, copias en la sombra de los datos almacenados en el motor KV dentro de una arquitectura de Procesamiento Paralelo Masivo (MPP), que se puede utilizar para consultar los datos en la sombra utilizando un lenguaje similar a SQL (SQL++) y exponer grandes conjuntos de datos pre-agregados a soluciones de terceros para su posterior procesamiento.
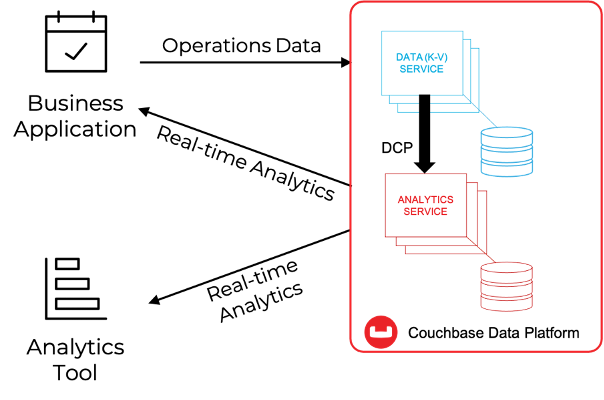
Couchbase proporciona la tecnología básica necesaria para poner en marcha el viaje de ACME hacia la Inteligencia Continua: la flexibilidad de NoSQL integrada en una plataforma capaz de realizar operaciones por debajo del milisegundo, aislamiento de cargas de trabajo, escalabilidad lineal multidimensional e integración con soluciones de terceros, todo ello combinado en una elegante plataforma que abarca desde la Nube Múltiple hasta el Edge.
Como SRE en ACME, podemos entender fácilmente cómo Couchbase puede proporcionar un plano de datos empresarial de clase mundial para la tienda en línea de próxima generación. Pero, ¿qué pasa con la lógica de negocio?
Bueno, depende del tipo de lógica de negocio que necesitemos: Couchbase proporciona, por defecto, un conjunto completo de capacidades necesarias para recuperar mediante programación documentos individuales o ejecutar consultas ad-hoc/a priori (consultar o analizar). Pero para la tienda en línea de próxima generación de ACME, es posible que queramos elevar nuestro juego y buscar sinergias con las muchas soluciones empresariales en el mercado actual que ofrecen todo el arsenal de análisis: exploración de datos, observabilidad, navegación de datos, cuadros de mando en tiempo real, aprendizaje automático e IA.
Ni que decir tiene que Couchbase está diseñado para integrarse con ellos, y en el ejemplo de hoy, utilizaremos API REST de Couchbase Analytics para integrarse con Splunk.
¿Por qué Splunk? He aquí algunas razones de peso, sin entrar demasiado en detalles:
- Nivel de adopción y madurez: Splunk es un líder del mercado de ITOMAsí que lo más probable es que su organización ya disponga de competencias y entornos para que usted experimente con ellos.
- Versión de prueba localSi tiene un presupuesto ajustado, puede instalar Splunk localmente y utilizarlo de forma gratuita durante un periodo de prueba de 60 días.
- Facilidad de uso: Splunk Lenguaje de procesamiento de búsquedas (SPL) es bastante fácil de aprender y, a la vez, muy potente, y hay montones de recursos disponibles para empezar.
- Aplicaciones Splunk: Splunk viene con un vibrante ecosistema de aplicaciones de un solo clic de instalación, incluyendo un Herramientas de aprendizaje automático capaz de desbloquear modelos ML sin necesidad de codificar - y herramienta ideal para principiantes y aquellos que no están del todo familiarizados con librerías como Pytorch, Pandas, TensorFlow.
Como ACME SRE, podríamos preguntarnos: ¿será capaz una aplicación sencilla de ofrecer resultados significativos? Es de esperar que los científicos de datos estén dispuestos a confirmar, en el estado actual de la industria, la necesidad de IA del mercado no requiere necesariamente los últimos algoritmos de vanguardia; resulta que las técnicas tradicionales como la regresión, la detección de valores atípicos, la agrupación, el análisis de sentimientos son las herramientas más eficaces que una organización puede implementar hoy para impulsar la transformación digital.
Naturalmente, es una buena práctica tener un conocimiento básico de la teoría que subyace a estas técnicas. En cambio, no necesitará saber nada sobre redes convolucionales, aprendizaje por refuerzo, redes generativas adversariales, Blenders, etc.
Bueno, parece que ya tenemos el plan: ¡es hora de ponerse manos a la obra! En los próximos párrafos, vamos a:
- Generar e importar en Couchbase una serie de documentos JSON representativos de las transacciones realizadas en la tienda online;
- Replicar esta información en un conjunto de datos de Analytics
- Utilice SQL ++ para ejecutar consultas en este conjunto de datos, y recoger los resultados en Splunk a través de las API REST Analytics.
- Utilice Splunk para crear cuadros de mando que muestren los datos operativos y las predicciones de Machine Learning en tiempo real.[1]
Coge una taza de té y prepárate: estamos a punto de despegar. ¡Vámonos!
6 pasos hacia la inteligencia continua
Paso #1: Generación de datos
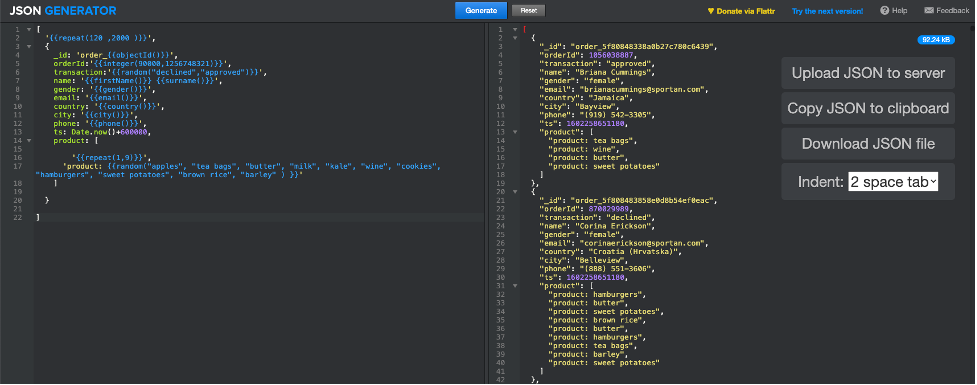
Para garantizar el cumplimiento de la normativa sobre datos, utilizaremos una herramienta en línea denominada Generador JSON[2] para generar documentos JSON representativos de transacciones en la tienda online de ACME; a continuación se muestra cómo hemos configurado los parámetros de generación[3]:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[ '{{repeat(120 ,2000 )}}', { _id: 'order_{{objectId()}}', orderId:'{{integer(90000,1256748321)}}', transaction:'{{random("declined","approved")}}', name: '{{firstName()}} {{surname()}}', gender: '{{gender()}}', email: '{{email()}}', country: '{{country()}}', city: '{{city()}}', phone: '{{phone()}}', ts: Date.now()+600000, product: [ '{{repeat(1,9)}}', 'product: {{random("apples", "tea bags", "butter", "milk", "kale", "wine", "cookies", "hamburgers", "sweet potatoes", "brown rice", "barley" ) }}' ] } ] |
Una vez que haga clic en "Generar", la herramienta responderá con un conjunto variable de documentos JSON (entre 120 y 2000), como se muestra en la siguiente captura de pantalla.
Ya tenemos nuestra línea de base, ¡es hora de pasar a Couchbase!
Paso #2: Importar datos en Couchbase
Supondremos que ya se dispone de un clúster Couchbase, que ejecuta al menos los datos y el servicio de análisis.
Como primer paso, vamos a crear un cubo llamado couchmart (siéntete libre de ponerle el nombre que quieras) en el que se cargarán los documentos JSON.
A continuación cargar los archivos JSON en el clúster Couchbase; elija un nodo que ejecute el servicio de datose importar los archivos en el /tmp (puede utilizar la carpeta que desee). Si dispone de SCP, ejecute este comando desde el terminal de su máquina local:
|
1 |
Scp <jsonfile> <couchbaseuser>@<couchbaseserver>:/tmp |
Sólo asegúrese de establecer , y de acuerdo a su entorno.
Por último importar los archivos JSON al bucket couchmartutilizando el cbimport (más información aquí); en primer lugar, inicie sesión en el nodo de datos en el que cargó previamente los archivos a través de SSH:
|
1 |
ssh <couchbaseuser>@<couchbaseserver> |
Una vez iniciada la sesión, ejecute el programa cbimport como se describe a continuación, asegurándose de configurar los campos entre según su entorno:
|
1 2 |
$CBHOME/bin/cbimport json -c couchbase://localhost -b <bucketname> -u <user> - p <password> -f list -d file:///tmp/<jsonfile> -g %_id% -t 4 |
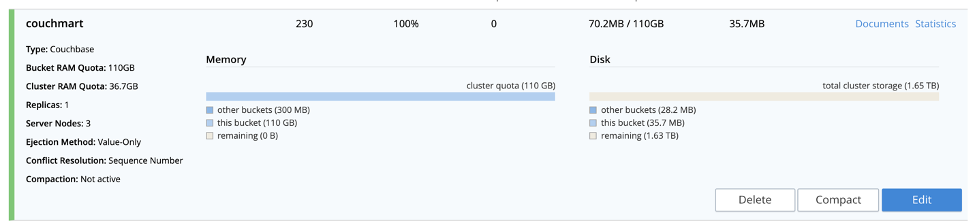
La importación debería completarse en un abrir y cerrar de ojos, ya que Couchbase puede manejar órdenes de magnitud superiores. Deberías confirmar que nuestro bucket ahora tiene algunos documentos desde el Admin UI de Couchbase en la sección buckets - ver captura de pantalla abajo.
Tenemos datos; ¡es hora de analizar!
Paso #3: Crear y probar conjuntos de datos analíticos
Como primer paso, vamos a crear un conjunto de datos llamado acmeorders (¿adivina qué? ¡Puedes ponerle el nombre que quieras!) como una réplica en la sombra del cubo de couchmarteste conjunto de datos contendrá toda la información expuesta a Splunk.
Si no está familiarizado con la creación de conjuntos de datos, le recomendamos que consulte la documentación y este tutorial. Bastan dos comandos SQL++ para crear una réplica completa de los buckets couchmart:
|
1 |
CREATE DATASET acmeorders ON couchmart; |
seguido por:
|
1 |
CONNECT LINK Local; |
Más fácil imposible.
Dado que vamos a utilizar las API de descanso, ahora es un buen momento para probarlas utilizando el práctico comando curl que aparece a continuación; como siempre, comprueba dos veces los valores dentro de y el puerto configurado para el servicio de análisis:
|
1 |
curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders;" https://<couchbaseserver>:8095/analytics/service |
Si este comando funciona, Couchbase está listo para rodar. Antes de pasar a Splunk, por favor recuerda que:
- El servicio Couchbase Analytics se basa en un arquitectura de procesamiento paralelo masivo (MPP) que se escala linealmente; eso significa que si necesitas duplicar las prestaciones, basta con duplicar los nodos.
- En la versión 6.6, hemos introducido muchas funciones importantes en el servicio Analytics. no deje de visitarlos!
Muy bien, Couchbase nos cubre las espaldas, ¡es hora de algo de inteligencia procesable!
Paso #4: Instalación y configuración de Splunk
Para el resto de este documento, vamos a suponer que Splunk se ejecuta en Linux, por lo que las rutas pueden cambiar si usted está en Mac o Windows.
Si no dispone de una instancia de Splunk, puede instalar una instancia local aprovechando una prueba gratuita de 60 días. Una nueva instalación local no debería llevarle más de 10 minutos.
Asegúrese de instale el Kit de herramientas de aprendizaje automático de Splunksi necesita saber más sobre cómo instalar una aplicación Splunk, pulse aquí - ¡es super sencillo!
Para configurar eficazmente la integración con Couchbase (o cualquier otra fuente), es fundamental configurar Splunk para interpretar correctamente la salida de la llamada REST desde Couchbase y almacenar la información en un formato eficaz para SPL. Para ello, crearemos un nuevo tipo de fuenteEn resumen, un tipo de fuente define cómo Splunk analiza los datos de entrada; no vamos a profundizar en cómo crear un tipo de fuente, sino que proporcionaremos una solución viable.
Conéctese a través de SSH a su servidor Splunk y, a continuación, vaya a:
|
1 |
Cd $SPLUNKBASE/etc/system/local |
Cree un nuevo archivo llamado props.conf como sigue:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[couchbase] SEDCMD-remove_header = s/(.+\"results\":\s\[\s)//g SEDCMD-remove_trailing_commas = s/\},/}/g SEDCMD-remove_footer = s/(\],\s\"plans\".+)//g TIME_PREFIX = \" ts\":\s+ category = Structure disabled = false pulldown_type = 1 BREAK_ONLY_BEFORE_DATE = DATETIME_CONFIG = LINE_BREAKER = (,)\s\{ NO_BINARY_CHECK = true SHOULD_LINEMERGE = false |
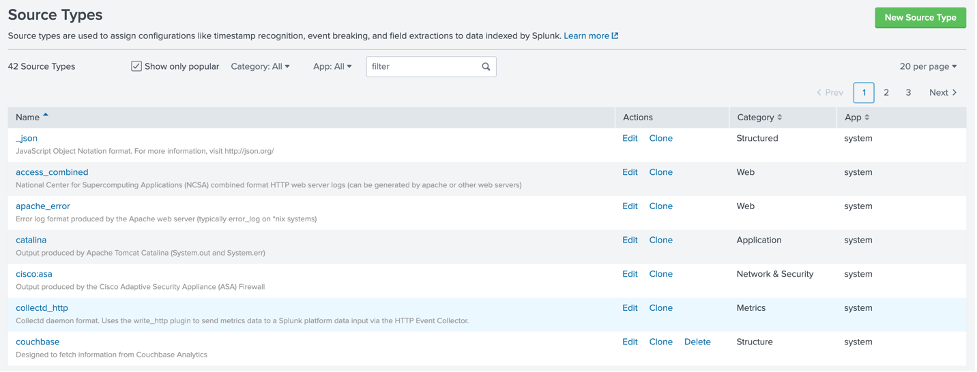
Una vez guardado, reiniciar Splunk. Ahora debería poder utilizar un nuevo tipo de fuente llamado couchbaseBasta con navegar por Configuración > Tipos de fuente para comprobar que todo está bien:
Ha llegado el momento de crear un nuevo Índice de Eventos Splunk que usaremos para capturar las transacciones del almacén ACME consultadas desde Couchbase; en Splunk, ve a Configuración > Índices y haz clic en Nuevo, luego configura un nuevo Índice como sigue:
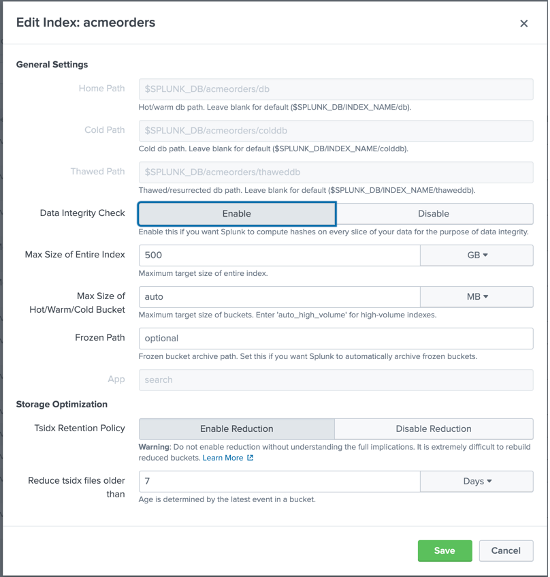
Tenga en cuenta que hemos llamado al índice acmeordersy aunque puedes ponerle el nombre que quieras, le recomendamos encarecidamente que mantenga el mismo nombre - para que puedas utilizar los archivos que compartiremos contigo sin modificar el código SPL subyacente.
Splunk está listo; ¡abramos las puertas y dejemos que Couchbase alimente algunos datos!
Paso #5: Importar datos a Splunk
La importación de datos en Splunk se reduce a la definición de un introducción de nuevos datos. Tenga en cuenta que hay muchas extensiones de Splunk disponibles para manejar entradas REST; sin embargo, por simplicidad, configuraremos una entrada entrada local basada en secuencias de comandos[4].
Primero, necesitamos crear un scriptConéctese a través de SSH a su servidor Splunk y, a continuación, vaya a:
|
1 |
Cd $SPLUNKBASE/bin/scripts |
Cree un nuevo archivo llamado acmeorders.sh como sigue; asegúrese de otorgar permisos de ejecución al usuario splunk:
|
1 2 |
#!/bin/bash curl -v -u <user>:<password> --data-urlencode "statement=select * from acmeorders where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000;" https:// <couchbasenode>:8095/analytics/service |
Como habrás notado, el script utiliza el mismo comando curl que utilizamos anteriormente al probar el conjunto de datos acmeorders, con una pega: una condición where. Es importante limitar la cantidad de datos que se importan en cada ejecución para evitar la duplicación masiva de datos, ya que estaremos sondeando Couchbase cada 30 segundos.
La condición where de SQL++:
|
1 |
Where ts>unix_time_from_datetime_in_ms(current_datetime()) - 90000 |
recuperará sólo aquellos documentos cuya marca de tiempo sea como mínimo 90 segundos; en otras palabras, podremos sobrevivir a 2 sondeos fallidos sin perder ningún dato.
Antes de seguir adelante, es importante subrayar que este enfoque puede funcionar bien para ejecutar una prueba de concepto, mientras que para la producción, usted debe considerar formas más eficientes de utilizar marcadores de posición y marcadores para asegurarse de que sólo los nuevos datos se leen en un momento dado, o considerar un concurso-estrategia basada en si procede.
Pruebe el script preguntando en el terminal:
|
1 |
$SPLUNKBASE/bin/scripts/acmescript.sh |
Si esta prueba tiene éxito, es hora de configurar la nueva entrada de datos. En Splunk, vaya a Configuración > Entradas de datos y elija una nueva entrada local basada en un script.
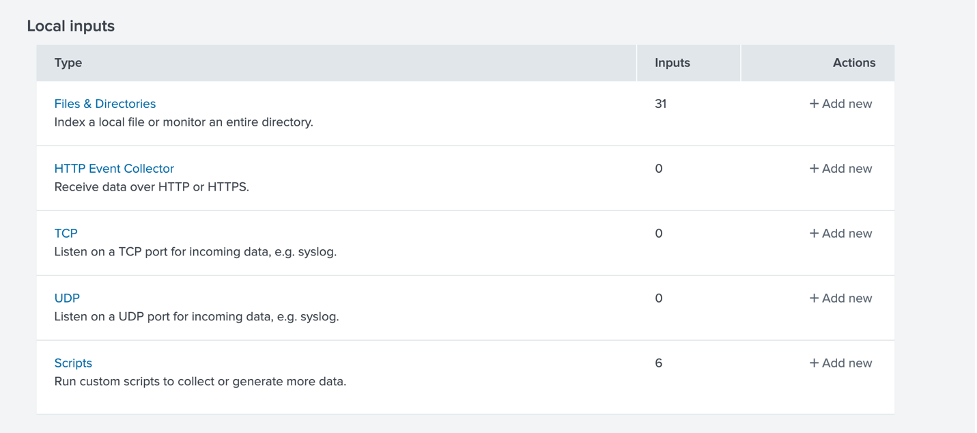
Haga clic en Scripts, luego en Nuevos Scripts Locales, y configure un nuevo script como sigue; primero, configure la ruta del script y la frecuencia de sondeo:
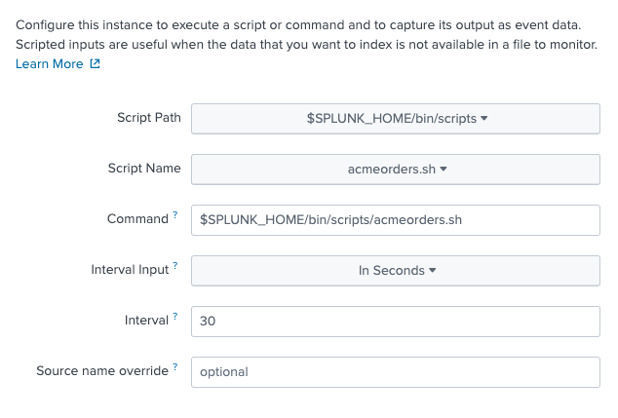
A continuación, configure los ajustes de entrada como se muestra a continuación - prestando atención a seleccionar couchbase como tipo de fuente, Búsqueda e informes como Contexto de la aplicacióny acmeorders como índice.
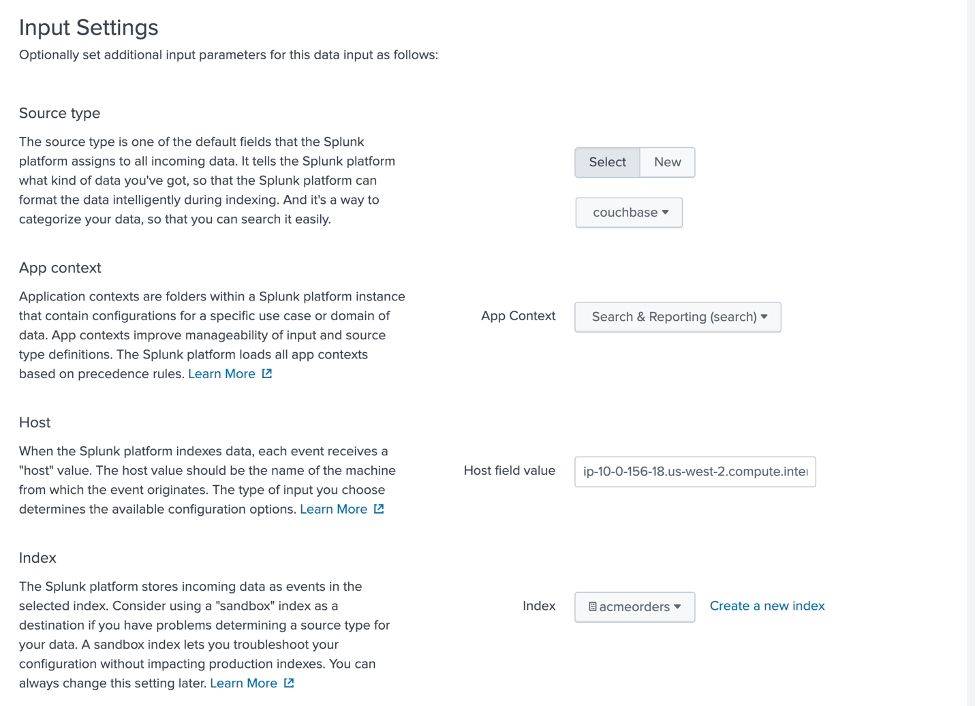
Revisar y enviar para guardar. Para asegurarse de que los datos fluyen correctamente hacia SplunkAcceda a la aplicación de búsqueda e informes:
e intente la siguiente consulta SPL - asegurándose de seleccionar Todos los tiempos en lugar de Últimas 24 horas del cuadro combinado del filtro de tiempo:
|
1 |
index="acmeorders" sourcetype="couchbase" | dedup acmeorders.orderId | search acmeorders.product{}=* | table _time, acmeorders.name, acmeorders.gender, acmeorders.country, acmeorders.gender, acmeorders.city, acmeorders.orderId, acmeorders.product{} , acmeorders.transaction | rename acmeorders.product{} as product | rename acmeorders.gender as gender | rename "acmeorders.transaction" as approval | rename acmeorders.orderId as orderId | rename acmeorders.name as name | rename acmeorders.country as country | rename acmeorders.city as city |
Debería ver algo similar a la imagen siguiente:
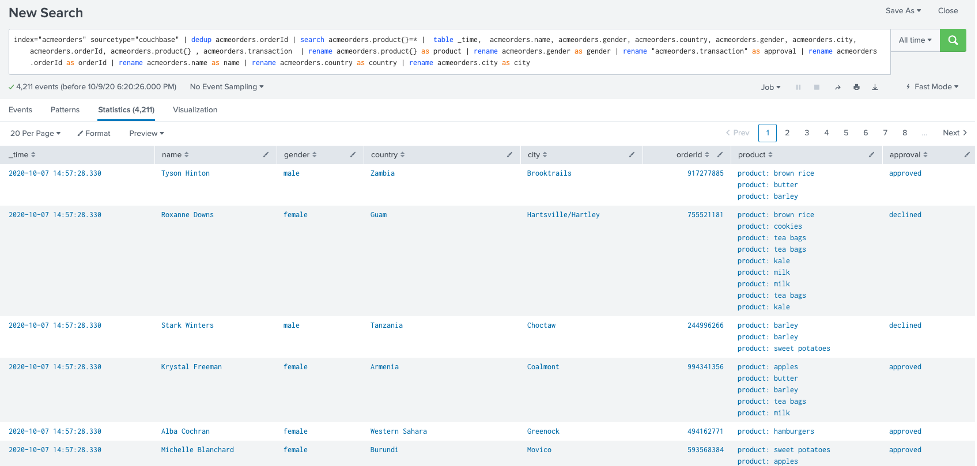
Si esta prueba tiene éxito... ¡Enhorabuena! ¡Has integrado Splunk con Couchbase!
Un último paso: liberar la Inteligencia Continua!
Paso #6: Implementación de un panel de Splunk con detección de anomalías basada en ML
Para ser considerados con el tiempo, no vamos a profundizar en cómo crear Dashboards y modelos de Machine Learning en Splunk; en su lugar, le proporcionaremos un dashboard completamente funcional configurado para refrescarse cada 30 segundos, aprovechando el Referencia XML simple en Splunk.
Para importar el cuadro de mandos de plantillasInicie sesión en Splunk y, en la aplicación de búsqueda e informes, haga clic en Cuadros de mando y, a continuación, en "Crear un nuevo cuadro de mando"; asígnele el nombre que desee y haga clic en "Crear cuadro de mando".
En la parte superior de la pantalla debería aparecer el botón "Fuente": haga clic en él:

Sólo tiene que pegar el código XML contenido en este archivo. Una vez hecho esto, haz clic en Guardar y relájate... ¡Hemos terminado!
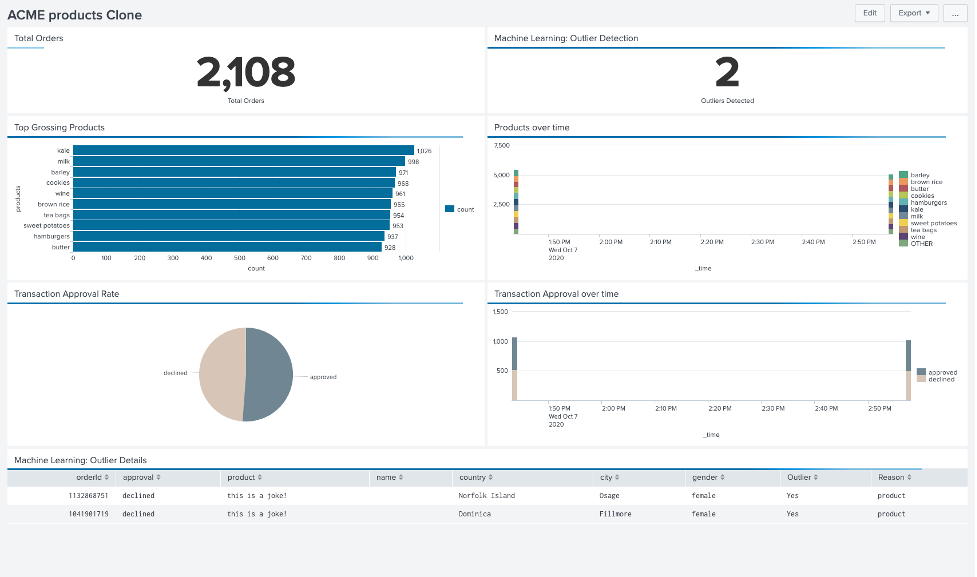
Como en la siguiente imagen, ahora debería tener acceso a un panel que muestra el total de pedidos recibidos, información sobre productos y aprobaciones de transacciones, y valores atípicos detectados mediante aprendizaje automático. actualizado en tiempo real!
Llamamiento a la acción: ¡saca al genio de la botella!
Antes de dejarte ir desata Inteligencia continua en su organización, he aquí nuestra llamada a la acción para usted:
- Repasar la sesión James Powesnki, y yo fuimos anfitriones en Couchbase Connect 2020, "Cuando Couchbase se encuentra con Splunk/ la plataforma de análisis de datos en tiempo real impulsada por IA".
- Ejecutar varias importaciones de datos nuevos utilizando Generador JSON y el mismo procedimiento que utilizábamos antes (o cualquier solución equivalente) para mejorar apreciar la rapidez con que los cambios se propagan aguas abajo
- Experimentar con valores atípicosen el ejemplo Generador JSON con la configuración que se muestra a continuación, que generará hasta dos documentos, con un null y un nombre de producto ficticio que debe activar la detección de valores atípicos:
123456789101112131415161718['{{repeat(1,2)}}',{_id: 'order_{{objectId()}}',orderId:'{{integer(90000,1256748321)}}',transaction:'{{random("declined","approved")}}',name: '',gender: '{{gender()}}',email: '{{email()}}',country: '{{country()}}',city: '{{city()}}',phone: '{{phone()}}',ts: Date.now()+600000,product: ['this is a joke']}] - Experimente con otros conocimientos basados en ML. A efectos de este artículo, nos hemos centrado en la detección de valores atípicos, ya que es el único análisis que se puede exportar fácilmente a XML; no obstante, hay muchas otras rutas de valor que merece la pena explorar:
- Agrupación: segmentar la clientela
- Previsiones: predecir la demanda de bienes, teniendo en cuenta la estacionalidad
- Predicciones de categoría: anticiparse a las necesidades del cliente e impulsar la retención
- Mejorar los conjuntos de datos analíticos aprovechando la nuevas funciones Enlaces remotos y Datos externos introducido en Couchbase 6.6
Gracias por leer el artículo completo; espero que le haya resultado útil. Si tiene alguna pregunta, no dude en acércate a mí o póngase en contacto con su representante de Couchbase más cercano.
Ahora, ¡sal ahí fuera y lleva tu negocio al siguiente nivel!
[1] Actualizar cada 30 segundos
[2] FakeIt también sería una buena opción, más potente pero algo más complicada.
[3] Ajustamos la marca de tiempo ts para que coincida con el reloj del clúster Couchbase; no dude en modificarlo según sus necesidades
[4] Dependiendo de sus necesidades, puede que no sea la solución más eficaz, pero es una forma fácil de empezar.