Couchbase Capella es una oferta de base de datos como servicio (DBaaS) de documentos JSON totalmente gestionada que elimina las tareas de gestión de bases de datos y reduce los costes generales. Capella ofrece rendimiento robusto, flexibilidad y escalabilidad en una moderna base de datos distribuida y nativa de la nube que fusiona los puntos fuertes de las características de las bases de datos relacionales, como SQL y las transacciones ACID, con la flexibilidad y escalabilidad de JSON que define NoSQL.
Pydantic es una biblioteca que permite a los desarrolladores definir y validar objetos JSON personalizados utilizando anotaciones de tipo Python. Pydantic acelera el tiempo de codificación mediante la aplicación de sugerencias de tipo en tiempo de ejecución y la generación de errores de validación fáciles de usar. Los documentos JSON generados mediante pydantic pueden utilizarse en la plataforma Capella sin tener que preocuparse por los documentos mal formados que pueden producirse cuando los documentos JSON se crean mediante la concatenación de cadenas estándar.
Configuración de pydantic
Para ejecutar el proyecto de inicio rápido, necesita los siguientes requisitos previos:
-
- URL del repositorio Git: https://github.com/brickj/capella_pydantic
- Python 3 instalado
- En pip herramienta de gestión de paquetes
- Instalado el SDK de Couchbase Capella™:
- La documentación completa se encuentra en aquí
- Ejemplo de comando Python: pip install couchbase
- Instalada la biblioteca python pydantic:
- La documentación completa se encuentra en aquí
- Ejemplo de comando Python: pip install pydantic
- Cuenta Couchbase Capella:
- Inscríbete en prueba gratuita de 30 días
- Clúster Couchbase Capella y bucket denominado pydantic
En este blog, recorreré rápidamente un ejemplo de uso de pydantic para crear documentos JSON válidos y almacenarlos en Couchbase Capella.
El SDK Python de Couchbase permite a los desarrolladores realizar operaciones CRUD en un bucket especificado en un cluster de Couchbase. Por ejemplo, el siguiente fragmento de código realiza un upsert (insertar si la clave del documento no está en el bucket o actualizar si el documento ya existe):
|
1 2 |
# Store a Document cb_coll.upsert('u:king_arthur', {'name': 'Arthur', 'email': 'kingarthur@couchbase.com', 'interests': ['Holy Grail', 'African Swallows']}) |
Los desarrolladores de Python suelen crear documentos JSON utilizando cadenas o enteros para rellenar un objeto diccionario que almacena pares clave-valor. A continuación, ese objeto diccionario se envía al bucket especificado en la base de datos de Capella para su inserción. El código de ejemplo para crear y rellenar el objeto diccionario es similar al siguiente fragmento:
|
1 2 |
# Dictionary object with keys and values sample_dict = {1: 'document 1', 2: 'document 2'} |
Con pydantic, los desarrolladores tienen la flexibilidad de especificar un esquema para los objetos JSON que se puede aplicar a medida que se crean los documentos. Por ejemplo, los siguientes pasos a través de la creación de un documento JSON para los mensajes de usuario. El modelo del documento tiene este aspecto:
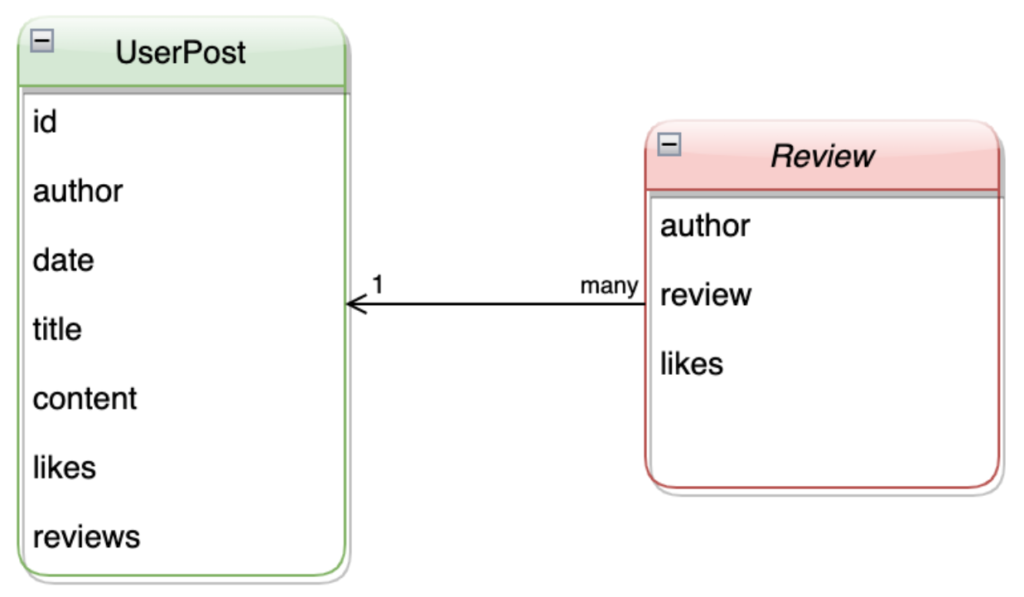
Cada UsuarioPost tiene los campos utilizados en la entrada, pero cada entrada puede tener varias revisiones que deben anidarse dentro de la entrada. Para habilitar esta funcionalidad, los desarrolladores pueden crear dos clases separadas para el objeto UsuarioPost y el Consulte. Por ejemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
class Review(BaseModel): author: str review: str likes: int class UserPost(BaseModel): author: str date: str title: Optional[str] = None content: str id: int likes: List[str] reviews: List[Review] |
Creación de documentos JSON en Python
Una vez creados los objetos, rellenar los documentos es fácil:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
review = [ Review(author="johndoe", review="This is a comment!", likes=3), Review(author="rickJ", review="This is a Rick J comment!", likes=1), Review(author="janedoe", review="This is a Jane Doe comment!", likes=2) ] user_post1 = UserPost(author="johndoe", date="1/1/1970", title="Cool post", content="Cool content", id=10101, likes=["johndoe", "janedoe"], reviews=review) |
Ahora puede utilizar el UsuarioPost como un diccionario y upsert a Couchbase Capella utilizando un código similar al upsert mostrado anteriormente pero utilizando el objeto dict() método:
|
1 2 |
# Upsert JSON dict with key 'u:pydantic_document' cb_coll.upsert('u:pydantic_document', user_post1.dict()) |
El proyecto completo ilustrado en este blog incluye lo siguiente:
-
- Léame con instrucciones
- Código que crea los objetos UserPost y Review
- Código que genera e imprime un documento a la salida
- Código que se conecta a Couchbase Capella usando Couchbase Python SDK
- Código que inserta el documento JSON generado
El proyecto público puede clonarse para Git en: https://github.com/brickj/capella_pydantic
Próximos pasos
Para saber más sobre Couchbase Capellanuestra oferta de base de datos como servicio:
-
- Inscríbete en prueba gratuita de 30 días si aún no lo ha hecho
- Conecte su grupo de prueba al Playground o conecte un proyecto para probarlo usted mismo
- Si ya estás usando Couchbase Capella, puedes interactuar con tu cluster usando el shell interactivo de Couchbase o a través del plano de control de Capella para:
- Consulte el visor de documentos
- Conectarse a un proyecto
- Eche un vistazo al Ruta de aprendizaje Capella
- Consulte nuestros tutoriales
- En Portal para desarrolladores de Couchbase tiene toneladas de tutoriales/guías de inicio rápido y vías de aprendizaje para ayudarle a empezar
- Consulte la documentación para obtener más información sobre los SDK de Couchbase
- Leer Validación de documentos JSON en Python con Pydantic
Llegados a este punto, deberías ser capaz de utilizar rápidamente la biblioteca pydantic para crear documentos JSON válidos para su uso con Couchbase Capella.
Si tiene alguna pregunta o comentario, póngase en contacto con nosotros en la dirección Foros de Couchbase!