Si estás familiarizado con Couchbase, seguro que sabes que XDCR. Si utilizas Couchbase para alguna de tus aplicaciones, es muy probable que estés utilizando XDCR. No me equivocaría si dijera que XDCR es uno de los productos más queridos por nuestros clientes. Si ahora estás interesado en aprender qué hace a XDCR tan impresionante, estás en el lugar correcto, por favor continúa leyendo. Por el contrario, si no tienes ni idea de lo que estoy diciendo, esta es tu oportunidad para aprenderlo.
La replicación es la clave de la eficacia de los sistemas distribuidos para proporcionar un mayor rendimiento, alta disponibilidad y tolerancia a fallos. XDCR es una tecnología de replicación de alto rendimiento utilizada para replicar datos entre dos clusters de Couchbase. Esto es complementario a la replicación intra-clúster. XDCR proporciona replicación asíncrona y mantiene la consistencia de los datos a través de la consistencia eventual, lo que implica que tan pronto como se ejecuta una única copia de mutación, se envían acuses de recibo a las aplicaciones y, finalmente, los datos se vuelven consistentes a través de diferentes clusters en la topología.
Principios básicos de esta tecnología
- Alto rendimiento : XDCR es un sistema de replicación de alto rendimiento que funciona a la velocidad de la red y la memoria con una latencia muy baja. La replicación es de memoria a memoria.
- Sistema escalable independiente : XDCR tiene una arquitectura de igual a igual en la que pueden añadirse o eliminarse clústeres y cada clúster de la topología puede ampliarse o reducirse sin afectar a otros clústeres.
- Infraestructura agnóstica : XDCR puede utilizarse para replicar datos entre dos clústeres couchbase cualquiera que sea su plataforma de despliegue: bare metal, máquinas virtuales, nube privada, nube pública, híbrida o contenedores.
- Conocimiento de la topología : XDCR es consciente de la topología, a medida que se añaden o eliminan nodos de los clústeres, el sistema ajusta y gestiona la replicación en consecuencia, sin ninguna intervención manual.
- Configuración y administración simplificadas: XDCR puede configurarse en <15 segundos, entre dos clusters Couchbase cualesquiera. Una vez configurado, los documentos se sincronizan continuamente entre el origen y el destino. Funciona sin ninguna intervención manual, incluso durante los cambios de topología, como la conmutación por error o el reequilibrio.
- Topología flexible : Unidireccional, bidireccional, hub & spoke, anillo, malla, etc., se puede configurar cualquier topología compleja.
- Resistente : En caso de cualquier fallo de red, XDCR puede reanudar la replicación desde donde se interrumpió. XDCR también reintenta continuamente hasta que la replicación tiene éxito.
XDCR bajo el capó
Para familiarizarse con la arquitectura del servidor Couchbase, escuche esto hable.
En este blog, nos centraremos en la arquitectura XDCR.
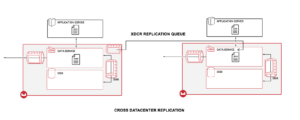 Para describir el flujo a alto nivel, los datos de la aplicación del servidor de aplicaciones se escriben en nuestra memoria integrada (caché) a través de los SDK de cliente. Una vez que estos datos están en la memoria, se canalizan en diferentes colas para su replicación y persistencia. La replicación entre clústeres se realiza de memoria a memoria, como se indica en la figura anterior, y es uno de los principales factores que permiten a XDCR ofrecer una latencia muy baja.
Para describir el flujo a alto nivel, los datos de la aplicación del servidor de aplicaciones se escriben en nuestra memoria integrada (caché) a través de los SDK de cliente. Una vez que estos datos están en la memoria, se canalizan en diferentes colas para su replicación y persistencia. La replicación entre clústeres se realiza de memoria a memoria, como se indica en la figura anterior, y es uno de los principales factores que permiten a XDCR ofrecer una latencia muy baja.
Además, la replicación es altamente paralela entre los nodos de origen y destino. Las colas de replicación pueden ajustarse entre 2 y 100 en función de la disponibilidad de ancho de banda y del rendimiento deseado.
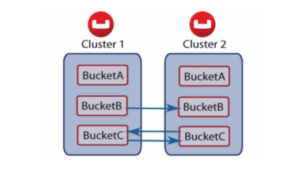
Los buckets en Couchbase son contenedores lógicos de documentos. XDCR puede configurarse a nivel de bucket. Cada bucket se divide en 1024 buckets virtuales llamados vbuckets. Estos vbuckets se reparten equitativamente entre los nodos de cada cluster. Cada uno de estos nodos termina con unos datos activos y otros replicados. XDCR descentraliza la replicación entre los nodos del clúster.
Couchbase mantiene un protocolo de streaming llamado como "Protocolo de cambio de base de datos (DCP)" a comunicar el estado de los datos mediante un registro de cambios ordenado. XDCR es un consumidor de este protocolo y depende de DCP para propagar los cambios.
Una cola de replicación XDCR mantiene los cambios específicos XDCR. Los hilos de trabajo XDCR recogen los cambios para el vbucket activo dado en el nodo y comunican los cambios al nodo remoto que mantiene el vbucket activo en el clúster de destino. La arquitectura no requiere ninguna coordinación centralizada para la replicación de cada vbucket, lo que contribuye a las características de baja latencia y alto rendimiento. El número de hilos de trabajo puede configurarse para maximizar el rendimiento en función del ancho de banda disponible.
XDCR mantiene puntos de control. Siempre que la replicación se interrumpe debido a fallos de red o fallos del cluster fuente, etc., XDCR reanuda la replicación desde el último punto de control. Si por alguna razón no tiene éxito, XDCR sigue intentándolo hasta que lo consigue. La replicación también se realiza en dos modos: replicación pesimista, en la que sólo se replican las claves, y replicación optimista, en la que se pueden replicar tanto las claves como los valores.
XDCR también está altamente optimizado para la conservación del ancho de banda a través de funciones como la compresión, el estrangulamiento de la red y la replicación optimista, donde puede comprimir los documentos para la replicación, restringir la utilización del ancho de banda y elegir replicar los documentos con replicación optimista hasta un cierto umbral para reducir la latencia.
Espero que esta primera parte de Comprender la serie XDCR te ha dado una buena visión general de qué es XDCR, cómo funciona y qué lo convierte en un sistema de replicación tan eficaz.
Permanezca atento a las siguientes partes, en las que aprenderemos más sobre sus características, ventajas, aplicaciones, ajuste del rendimiento y mucho más.
Si hay algún tema concreto sobre el que le interese saber más, añádalo en los comentarios.
Hola Chaitra,
En un modelo hub & spoke, si tenemos 2 hubs (con replicación bidireccional entre ambos), ¿deberían ambos hubs enviar los cambios a los spokes?
En caso afirmativo, se produce una replicación duplicada de centro a radio. Esto no es óptimo.
Si no, es decir, si sólo un concentrador replica a los radios, entonces el reto es que cuando ese concentrador esté fuera de servicio, será necesaria la intervención manual para configurar la replicación desde el otro concentrador a los radios.
¿Puede sugerir si hay una manera de informar/configurar XDCR de tal manera que si un hub recibe cambios de otro hub entonces estos no deben replicarse a los radios pero si recibe cambios de la aplicación entonces estos deben replicarse a los radios. En caso afirmativo, podemos configurar la replicación unidireccional de ambos concentradores a los radios y el concentrador que recibe los cambios de la aplicación los replicará a los radios, pero el otro concentrador no. Si el hub que recibe los cambios de la aplicación se cae, el otro hub empezará a recibir los cambios de la aplicación y empezará a replicarlos a los radios.
Gracias
> Entonces, ¿ambos centros deben enviar los cambios a los radios?
> En caso afirmativo, se produce una replicación duplicada de centro a radio. Esto no es óptimo.
Un concentrador no puede dar por sentado que, como otro ha enviado una réplica a un radio, éste la ha recibido. La replicación duplicada se evita con DCP.