Se você tem alguma familiaridade com o Couchbase, com certeza sabe XDCR. Se você usa o Couchbase em qualquer um dos seus aplicativos, é muito provável que esteja usando o XDCR. Eu não estaria errado se dissesse que o XDCR é, de fato, um dos produtos mais adorados pelos nossos clientes. Se agora você está interessado em saber o que torna o XDCR tão incrível, você está no lugar certo, continue lendo. Por outro lado, se não tiver ideia do que estou dizendo, esta é a sua oportunidade de aprender sobre o assunto.
A replicação é a chave para a eficácia dos sistemas distribuídos para fornecer desempenho aprimorado, alta disponibilidade e tolerância a falhas. O XDCR é uma tecnologia de replicação de alto desempenho usada para replicar dados entre dois clusters do Couchbase. Isso é complementar à replicação intracluster. O XDCR oferece replicação assíncrona e mantém a consistência dos dados entre os locais por meio da consistência eventual, o que significa que, assim que uma única cópia da mutação é executada, as confirmações são enviadas aos aplicativos e, por fim, os dados se tornam consistentes em diferentes clusters na topologia.
Princípios básicos por trás dessa tecnologia
- Alto desempenho : O XDCR é um sistema de replicação de alto desempenho que opera na velocidade da rede e da memória com latência muito baixa. A replicação é de memória para memória.
- Sistema dimensionável de forma independente: O XDCR tem uma arquitetura ponto a ponto em que os clusters podem ser adicionados ou removidos e cada cluster na topologia pode ser ampliado ou reduzido sem afetar os outros clusters.
- Infraestrutura agnóstica : O XDCR pode ser usado para replicar dados entre dois clusters do couchbase, independentemente da plataforma de implementação, como bare metal, VMs, nuvem privada, nuvem pública, híbrida ou contêineres.
- Reconhecimento de topologia : O XDCR reconhece a topologia, pois à medida que os nós são adicionados ou removidos dos clusters, o sistema ajusta e gerencia a replicação de acordo, sem nenhuma intervenção manual.
- Configuração e administração simplificadas: O XDCR pode ser configurado em menos de 15 segundos, entre quaisquer dois clusters do Couchbase. Uma vez configurado, os documentos são continuamente sincronizados entre a origem e o destino. Ele funciona sem nenhuma intervenção manual, mesmo durante alterações na topologia, como failover ou rebalanceamento.
- Topologia flexível : Unidirecional, bidirecional, hub & spoke, anel, malha etc., qualquer topologia complexa pode ser configurada.
- Resiliente : Em caso de falhas na rede, o XDCR pode retomar a replicação de onde ela foi interrompida. O XDCR também faz novas tentativas continuamente até que a replicação seja bem-sucedida.
XDCR sob o capô
Para se familiarizar com a arquitetura do servidor Couchbase, ouça o seguinte conversa.
Neste blog, vamos nos concentrar na arquitetura XDCR.
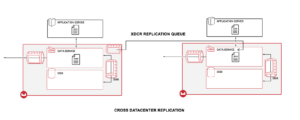 Para descrever o fluxo em um alto nível, os dados do aplicativo do servidor de aplicativos são gravados em nossa memória interna (cache) por meio dos SDKs do cliente. Quando esses dados estão na memória, eles são canalizados em diferentes filas para replicação e persistência. A replicação entre clusters ocorre de memória para memória, conforme indicado na figura acima, e esse é um dos principais fatores que permitem que o XDCR ofereça latência muito baixa.
Para descrever o fluxo em um alto nível, os dados do aplicativo do servidor de aplicativos são gravados em nossa memória interna (cache) por meio dos SDKs do cliente. Quando esses dados estão na memória, eles são canalizados em diferentes filas para replicação e persistência. A replicação entre clusters ocorre de memória para memória, conforme indicado na figura acima, e esse é um dos principais fatores que permitem que o XDCR ofereça latência muito baixa.
Além disso, a replicação é altamente paralela entre os nós na origem e no destino. As filas de replicação podem ser ajustadas entre 2 e 100, dependendo da disponibilidade de largura de banda e do desempenho desejado.
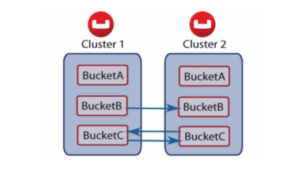
Os buckets no Couchbase são contêineres lógicos para documentos. O XDCR pode ser configurado no nível do bucket. Cada bucket é dividido em 1024 buckets virtuais chamados de vbuckets. Esses vbuckets são divididos igualmente entre os nós de cada cluster. Cada um desses nós acaba com alguns dados ativos e alguns dados de réplica. O XDCR descentraliza a replicação entre esses nós no cluster.
O Couchbase mantém um protocolo de streaming chamado "Protocolo de alteração de banco de dados (DCP)" para comunicar o estado dos dados usando um changelog ordenado. O XDCR é um consumidor desse protocolo e depende do DCP para propagar as alterações.
Uma fila de replicação do XDCR mantém as alterações específicas do XDCR. Os threads de trabalho do XDCR coletam as alterações de um determinado vbucket ativo no nó e comunicam as alterações ao nó remoto que mantém o vbucket ativo no cluster de destino. A arquitetura não exige nenhuma coordenação centralizada para a replicação de cada vbucket, o que leva em conta as características de baixa latência e alta taxa de transferência. O número de threads de trabalho pode ser configurado para maximizar a taxa de transferência, dependendo da largura de banda disponível.
O XDCR mantém pontos de verificação. Sempre que a replicação é interrompida devido a falhas de rede ou failover do cluster de origem etc., o XDCR retoma a replicação a partir do último ponto de verificação. Se, por algum motivo, ela não for bem-sucedida, o XDCR continuará tentando novamente até obter êxito. A replicação também ocorre em dois modos: replicação pessimista, em que somente as chaves são replicadas, e replicação otimista, em que tanto as chaves quanto os valores podem ser replicados.
O XDCR também é altamente otimizado para a conservação da largura de banda por meio de recursos como compactação, limitação de rede e replicação otimista, em que você pode compactar os documentos para replicação, restringir a utilização da largura de banda e optar por replicar os documentos com replicação otimista até um determinado limite para reduzir a latência.
Espero que esta primeira parte de Entendendo a série XDCR deu a você uma boa visão geral do que é o XDCR, como ele funciona e o que o torna um sistema de replicação tão eficiente.
Fique atento às próximas partes, nas quais aprenderemos mais sobre seus recursos, benefícios, aplicativos, ajuste de desempenho e muito mais!
Se houver um tópico específico sobre o qual você tenha interesse em saber mais, adicione-o nos comentários.
Oi Chaitra,
Em um modelo de hub e spoke, se tivermos dois hubs (com replicação bidirecional entre ambos), os dois hubs deverão enviar alterações para os spokes?
Se sim, há uma replicação duplicada do hub para o spoke. Isso não é o ideal.
Se não, ou seja, apenas um hub replica para os raios, o desafio é que, quando esse hub estiver inativo, será necessária uma intervenção manual para configurar a replicação do outro hub para os raios.
Você pode sugerir se há uma maneira de informar/configurar o XDCR de modo que, se um hub receber alterações de outro hub, elas não sejam replicadas para os raios, mas se ele receber alterações do aplicativo, elas serão replicadas para os raios. Em caso afirmativo, podemos configurar a replicação unidirecional de ambos os hubs para os raios, e o hub que receber as alterações do aplicativo as replicará para os raios, mas o outro hub não. Se o hub que recebe as alterações do aplicativo ficar inativo, o outro hub começará a receber as alterações do aplicativo e a replicá-las para os raios.
Agradecimentos
> Então, os dois hubs devem enviar alterações para os raios?
> Se sim, então há uma replicação duplicada do hub para o spoke. Isso não é o ideal.
Um hub não pode presumir que, pelo fato de outro hub ter enviado uma replicação a um spoke, o spoke a tenha recebido. A replicação duplicada é evitada pelo DCP.