Rebalance es un componente crítico de la arquitectura de Couchbase que permite operaciones de gestión de clúster en línea, incluyendo la adición / eliminación de nodos, actualizaciones en línea de hardware o software, y la recuperación después de un fallo de nodo.
Couchbase Server 6.5 hace el rebalanceo más robusto, más manejable y más rápido. Sigue leyendo para saber más sobre todas estas mejoras.
Reinicio automático del reequilibrio en caso de fallo
Couchbase, como cualquier sistema distribuido, puede experimentar fallos temporales como lentitud en la red, caída de procesos, etc. que pueden auto-repararse. Cuando estos fallos ocurren pueden causar que un rebalanceo en curso falle. Reintentar el rebalanceo fallido es a menudo la primera acción a la que recurren los usuarios, pero esto requiere que alguien esté monitorizando activamente el rebalanceo.
Ahora hemos incorporado reintentos para un reequilibrio fallido para que no tenga que supervisarlo y reiniciarlo manualmente. Puede configurar el número de veces que desea reintentarlo, así como el intervalo de reintento para saber cuánto tiempo desea esperar antes de reiniciar el reequilibrio fallido.
Nota: La función Reintentar reequilibrio está desactivada por defecto, por lo que debe activarla explícitamente (véase la captura de pantalla siguiente).
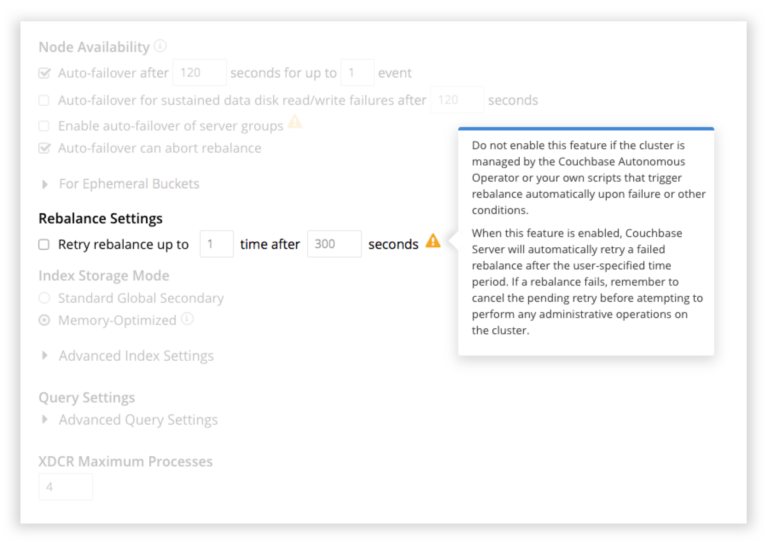
Cuando un reintento de reequilibrio está pendiente, la interfaz de usuario mostrará un banner indicándolo. Si lo deseas, te dará la opción de cancelar el reintento. El reequilibrio no se reintentará automáticamente para algunas condiciones, como si se ha abortado por auto-failover o explícitamente abortado por el usuario.
Auto-failover durante el reequilibrio
A menudo, el reequilibrio puede llevar cierto tiempo y es posible que falle un nodo del clúster (tanto si participa en el reequilibrio como si no). En tal situación, el nodo necesita ser reemplazado para promover sus réplicas y mantener la disponibilidad de acceso a los datos. El gestor de cluster de Couchbase ahora abortará un rebalanceo en curso para proceder con este auto-failover. Esto asegura que la disponibilidad se restaura rápidamente de acuerdo con los estrictos SLA de tiempo de actividad que las aplicaciones han llegado a esperar de Couchbase.
Este comportamiento está activado por defecto, como se puede ver en la captura de pantalla anterior. Si por alguna razón desea desactivarlo, puede hacerlo.
También queremos reiniciar automáticamente el reequilibrio después del auto-failover... pero eso es una mejora a buscar en una futura versión.
Reequilibrar el seguimiento de los progresos
Cuando se inicia el reequilibrio en un clúster Couchbase, se reequilibran todos los servicios, incluidos los servicios de datos, índices, consultas, búsqueda, eventos y análisis. Reequilibrio de cada El servicio de datos es el más complejo y suele ser la parte más larga del reequilibrio. El reequilibrio del servicio de datos procesa un bucket cada vez y, para cada bucket, procesa varios vbuckets simultáneamente.
Cuando un reequilibrio se desarrolla sin problemas, el administrador no debería necesitar supervisar y observar lo que ocurre (a menos que realmente quiera hacerlo). Sin embargo, si las cosas parecen atascadas o lentas, tener visibilidad de las etapas anteriores del reequilibrio es muy útil para averiguar qué trabajo se completó, qué trabajo está en curso y qué trabajo queda.
La nueva interfaz de control del reequilibrio imita la jerarquía anterior de servicios, cubos y etapas, y muestra el grado de reequilibrio de cada cubo (véase la captura de pantalla siguiente).
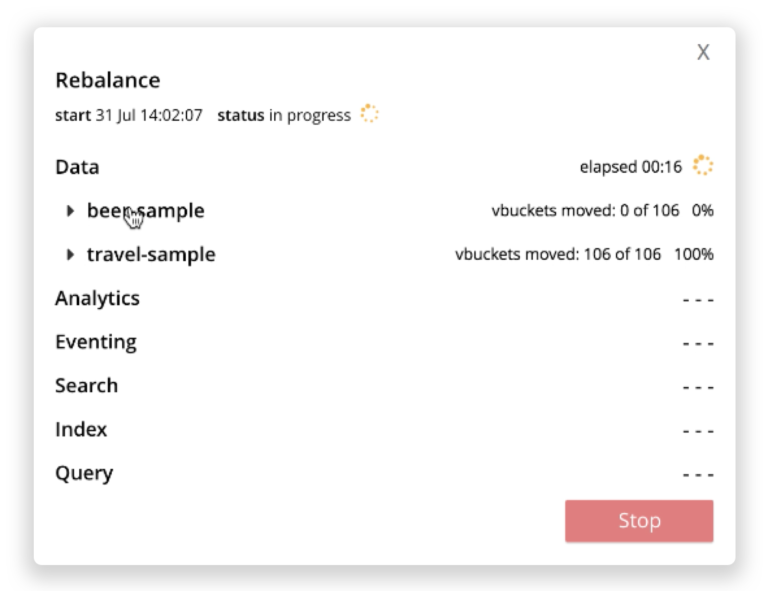
Informe de reequilibrio
Ahora puede obtener un informe del último reequilibrio a través de la API REST, por ejemplo
curl -X GET -u Administrador:contraseña https://localhost:8091/logs/rebalanceReport
Además de la información mostrada en la interfaz de usuario, el informe muestra la hora de inicio y fin de cada una de las 4 etapas (backfill, move, persistence y takeover) para cada vbucket.

Reequilibrio más rápido
Rebalance procesa múltiples vbuckets concurrentemente y cada vbucket tiene muchas fases internas durante el rebalance - una de las fases principales es relleno donde se produce la mayor parte de la copia de datos. El relleno suele ser la fase más larga del reequilibrio. La fase de relleno del reequilibrio cuenta ahora con un mecanismo de control de flujo mejorado. El gestor del clúster controla cuántos backfills están en curso en un nodo y se asegura de que los backfills anteriores terminen de persistir en el disco antes de que se inicien los nuevos.
En nuestras pruebas internas hemos observado una mejora muy prometedora del rendimiento con este nuevo mecanismo de control de flujo, especialmente para conjuntos de datos más grandes. También supone un menor impacto para la aplicación frontal como resultado de unas colas de escritura en disco más pequeñas y una menor presión de memoria.
Próximos pasos
Nos gustaría conocer su opinión sobre estas mejoras de Rebalance. Aquí tienes algunos recursos para empezar:
Descargar
Descargar Couchbase Server 6.5
Documentación
Notas de la versión de Couchbase Server 6.5
Novedades de Couchbase Server 6.5
Blogs
Anuncio de Couchbase Server 6.5 GA - Novedades y mejoras