Couchbase 7.6 presenta Búsqueda vectorial en la arquitectura Couchbaseestá ampliando sus capacidades de búsqueda a pasos agigantados. Este artículo muestra cómo afecta esto a las consultas de búsqueda, cómo tenemos que adaptarnos en determinadas situaciones y cómo utilizar eficientemente esta última característica. Para asegurarse de que sus búsquedas vectoriales son las mejores posibles, debe ser consciente de problemas como las consultas lentas causadas por índices ineficaces, consultas ineficientes o datos que cambian con frecuencia, así como otros casos de fallo como tiempos de espera, errores de coherencia, app herder, etc.
Introducción a las consultas vectoriales
Hubo que adaptar las consultas de búsqueda para permitir el uso de vectores. Se trata esencialmente de un nuevo tipo de consulta que permite búsqueda de similitudes en lugar de la búsqueda exacta. La diferencia es que ya no buscamos coincidencias exactas cuando se trata de vectores, sino las más próximas al vector especificado en la consulta:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "consulta": { "match_none": {} }, "knn": [ { "campo": "vector", "vector": [0.04603520780801773, ..., -0.08424953371286392], "k": 3 } ] } |
Se trata de una consulta vectorial. Difiere bastante de una consulta normal. Todas las partes vectoriales de la consulta están bajo una nueva clave llamada knnintroducido con el único fin de realizar consultas vectoriales. El sitio k en la consulta determina el número de documentos que queremos en los resultados. Esto es necesario porque en lugar de buscar la coincidencia exacta, nos preocupa encontrar la k vectores más cercanos al vector buscado. Esta consulta acabará devolviendo tres vectores que la búsqueda considera que son los más cercanos al vector de consulta.
|
1 2 3 4 5 6 7 8 9 10 |
{ "consulta": "contenido:coche", "knn": [ { "campo": "vector", "vector": [0.04603520780801773, ..., -0.08424953371286392], "k": 3 } ] } |
También puede combinar una consulta vectorial con una consulta normal para obtener un búsqueda híbrida. En este caso, la búsqueda realiza la consulta en dos fases. En la primera fase se realiza la búsqueda vectorial, fusionando todos los resultados de las distintas particiones, y en la segunda fase se realiza la búsqueda regular, utilizando los resultados de la primera fase. Este enfoque permite un mejor rendimiento tanto en términos de tiempo como de cantidad de datos pasados entre los nodos.
Ahora que ya sabemos cómo consultar vectores, repasemos las situaciones de fallo más habituales. ¿Qué puede fallar durante una consulta vectorial?
Identificación de consultas lentas
Uno de los tipos más comunes de fallo de consulta es la consulta lenta. Se denomina consulta lenta a aquella que permanece mucho tiempo procesándose en el sistema. Dependiendo del tiempo de espera establecido para esta consulta, puede permanecer en ejecución durante mucho tiempo.
Hay muchas razones por las que esto ocurre. Una de las más sencillas es que la ejecución de una consulta sea demasiado costosa. Esto puede deberse a que haga referencia a demasiados documentos, a que el número de documentos indexados sea enorme o a que el tipo de consulta sea comparativamente ineficiente.
En términos vectoriales, las causas más comunes de una consulta lenta se deben a un gran tamaño del índice con un número insuficiente de particiones, un gran valor K en la consulta o incluso una alta tasa de ingesta de datos.
Ahora que sabemos lo que es una consulta lenta, la siguiente pregunta que nos viene a la cabeza es, ¿cómo sabemos que hay una consulta lenta en ejecución? Una de las mejores maneras de hacerlo es comprobar los registros. Una consulta lenta se registrará cada 5 segundos. Este temporizador puede cambiarse utilizando las opciones del gestor y la línea de registro tendrá el siguiente aspecto:
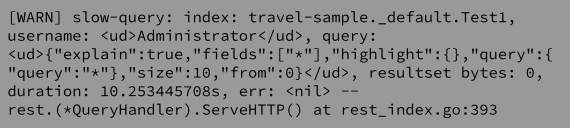
Otra forma es mirar las estadísticas. Hay una estadística disponible en /api/nsstats llamado total_consultas_lentas que registrará el número de veces que se ha detectado una consulta lenta:

También hay algunas estadísticas más que se pueden observar en el mismo endpoint que podrían darnos alguna pista sobre lo que está ocurriendo con la consulta internamente y dónde podrían estar los problemas:
-
- avg_grpc_internal_queries_latency - Tiempo medio que tarda el grpc en procesar una consulta procedente de otro nodo
- avg_grpc_queries_latency - Tiempo medio que tarda el grpc en procesar una consulta originada en el mismo nodo
- avg_internal_queries_latency - Tiempo medio de tratamiento de una consulta procedente de otro nodo
- avg_queries_latency - Tiempo medio empleado en procesar una consulta originada en el mismo nodo
Factores que contribuyen a la lentitud de las consultas
Ahora que sabemos cómo identificar una consulta lenta, el siguiente paso es entender por qué se produce y qué podemos hacer para minimizarla.
Índice de ineficiencia
Uno de los principales factores es el propio índice, el número de vectores indexados, el número de particiones o el número de nodos. Cada uno de estos factores es crucial para el rendimiento de las consultas.
El número de vectores indexados es un factor que se explica por sí mismo: cuanto mayor sea el número de vectores, más tiempo se tardará en consultarlos. A partir de la versión 7.6.0 puede deducirse aproximadamente a partir del número de documentos, pero el siguiente parche de mantenimiento incluirá una estadística que nos dará el valor exacto.
El número de particiones y nodos puede explicarse de forma intuitiva. Tomemos el ejemplo de una persona que revisa un montón de papeles en su escritorio.
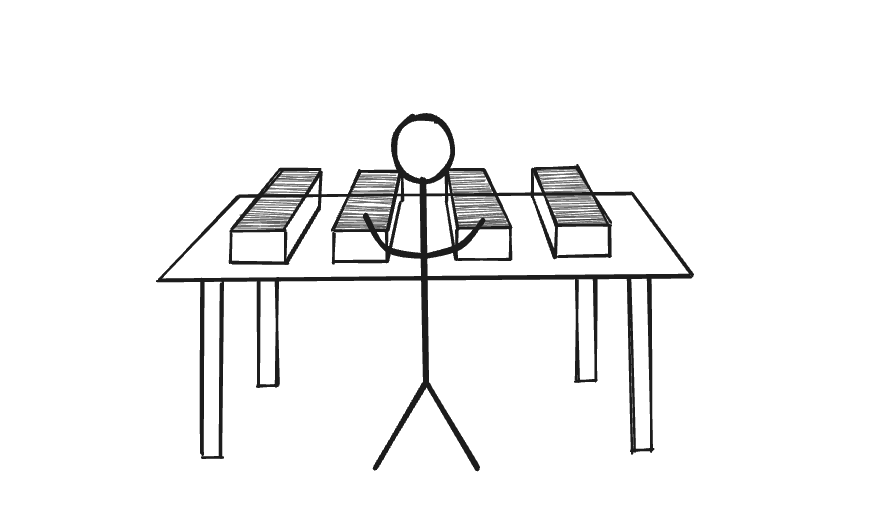
Hay muchos papeles y una sola persona, así que tarda más en encontrar lo que busca. Ahora añadamos una persona más en la misma mesa que revise la mitad de los documentos. Obviamente, esto reduce el tiempo necesario para encontrar los documentos correctos.
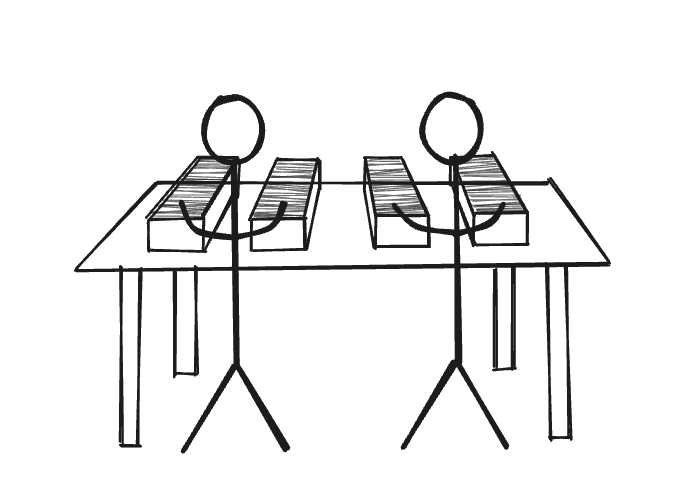
Podemos seguir añadiendo más personas a un mismo mostrador, pero llega un momento en que se acaba el espacio disponible y algunas se quedan esperando porque el mostrador está demasiado lleno.

La solución más sencilla es añadir otra mesa o comprar una más grande, para que más personas puedan sentarse y revisar los papeles a la vez.
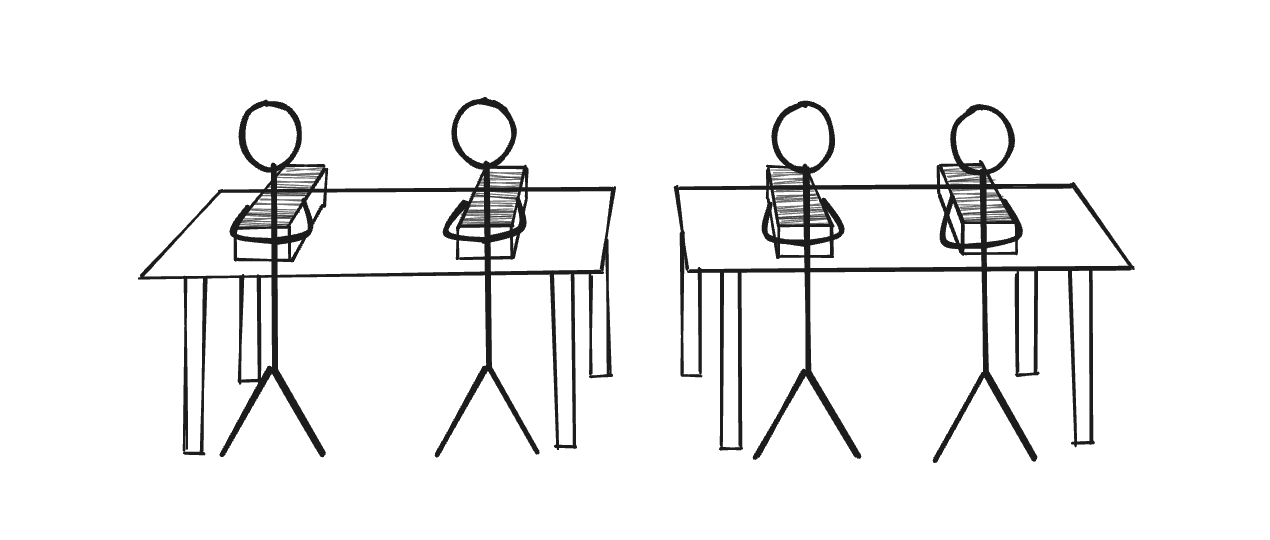
Este ejemplo es similar al ecosistema de búsqueda. Las personas son las particiones, los documentos son los vectores y las mesas son los nodos. Un mayor número de escritorios significa una mayor cantidad de recursos para atender a más personas. Más personas significa una búsqueda más rápida, pero demasiadas personas significan más comunicación entre ellas para obtener los resultados, lo que de nuevo será contraproducente. Cada sistema tiene su equilibrio y es importante encontrarlo para ser eficaz.
Consulta ineficaz
Otro factor importante que determina la cantidad de tiempo que una consulta vectorial pasa en el sistema es el valor K. Un valor K mayor significa que cada partición del índice tarda más en procesar la consulta, que es necesario transferir una mayor cantidad de datos entre nodos, que se necesitan búferes más grandes para contener todos estos datos y condensar los resultados K de cada partición (total K * número de particiones valor de los resultados) en los resultados finales de K. Cada uno de estos pasos lleva cada vez más tiempo a medida que aumenta el valor de K.

Volviendo al ejemplo anterior, un valor K grande significará que cada persona tendrá que rastrear una pila más grande de documentos, y cuando todos hayan terminado, ahora tendrán que comparar todas las pilas de documentos que preseleccionaron para encontrar los K mejores documentos.
Datos en constante cambio
La última pieza de este rompecabezas son los propios documentos. La búsqueda sigue una arquitectura de sólo anexión. Esto significa que cada cambio en el documento se añade, indexa y almacena por separado en lugar de reescribir la entrada del documento existente. Con un gran número de cambios en los documentos reales, obtenemos un índice muy ocupado con la creación constante de segmentos y la fusión constante de estos segmentos. Estas operaciones consumen muchos recursos, lo que afectará a las consultas, ya que no les quedará mucho con lo que trabajar.
Piénsalo como si la gente te trajera nuevas pilas de papeles mientras tú intentas encontrar lo que buscas. Es desordenado, no tienes suficiente espacio en la mesa, no paran de llegar papeles nuevos y tienes que hacer un seguimiento de los duplicados por si se trata de un documento actualizado.

Otros asuntos
Las consultas lentas no son la única razón por la que una consulta puede fallar. Algunos de los otros escenarios de fallo incluyen:
Tiempo de espera de la consulta
Se trata de una consulta lenta que alcanza el límite de tiempo máximo establecido por el usuario. Se debe a las mismas razones que las consultas lentas y se controla mediante total_queries_timeout.
La ventana de resultado máximo excede
Esto ocurre cuando tienes una consulta que necesita más hits que el límite maxResultWindow establecido para el cluster. Este valor por defecto es 10000 pero puede ser configurado a través de la API de opciones del gestor. Existe para evitar el flujo accidental de grandes cantidades de datos.
Resultados parciales
Esto ocurre cuando una de las particiones no está disponible y no envió sus resultados al nodo que recibió la consulta.
Rechazado por app herder
El app herder es el último punto de control para garantizar que los recursos del sistema se mantienen dentro de los límites establecidos. Cuando una consulta amenaza con superar el límite, lo que puede ocurrir debido a una gran carga de consultas o de indexación o a una operación de reequilibrio o a una combinación de las tres, el app herder cierra preventivamente la consulta impidiendo su ejecución.
Fallo de búsqueda en contexto
Esto cubre todos los posibles errores que pueden ocurrir dentro de bleve como cualquier problema con la interacción con los archivos de índice y tal.
Errores de coherencia
Los errores en la especificación de los parámetros de coherencia provocan el fallo de una consulta. Estos parámetros incluyen el nivel de coherencia de los datos, los resultados y otras variables relacionadas.
Malas peticiones
Este es el más simple y consiste básicamente en un error del usuario al realizar una consulta. Puede ser un error tipográfico, una mala estructura json o cadenas de consulta no válidas.
La introducción de la búsqueda vectorial amplía las capacidades de búsqueda de Couchbase más allá de los límites y casos de uso anteriores. Para aprovechar esta característica de manera efectiva, los usuarios necesitan entender sus funcionalidades, incluyendo la consulta, indexación de datos, y la gestión de los comportamientos del sistema en diversas condiciones. Para una comprensión aún más profunda de la búsqueda vectorial, su funcionalidad y capacidades, explora algunos de los otros blogs de nuestro sitio.
Próximos pasos
-
- Más información Conceptos de búsqueda vectorial en nuestros blogs, incluidos tutoriales y conceptos.
- Prueba gratuita de Couchbase Capella incluye búsqueda vectorial, entre otras muchas funciones. Pruébelo hoy mismo.

Contenido brillante
Muy informativo
Me ayudó a optimizar mi índice de búsqueda para mi aplicación.
Gracias Likith B