En el Estructuras de datos para aplicaciones NoSQL puesto, utilizamos el acceso simplificado a datos JSON a través de colecciones nativas, mapas y mucho más. Este artículo muestra cómo consultar esos datos utilizando consultas N1QL de alto nivel, el lenguaje basado en SQL para JSON.
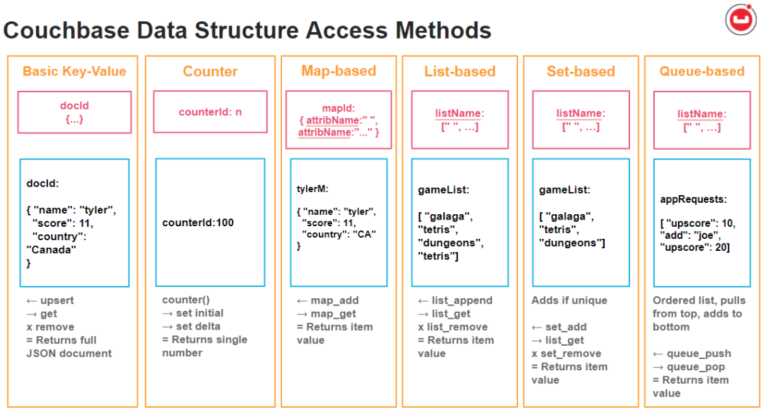
Resumen de tipos de estructuras de datos Couchbase y ejemplos JSON.
Los desarrolladores pueden centrarse en la gestión de estructuras y tipos de datos básicos utilizando lenguajes de programación. Mientras tanto, los DBA y los analistas pueden acceder a los mismos datos utilizando un lenguaje de consulta. Couchbase lo hace utilizando métodos de indexación de datos NoSQL y servicios de consulta N1QL.
Las consultas de búsqueda con el motor de búsqueda de texto completo de Couchbase también son posibles y se cubrirán en un futuro post.
¿Qué es la indexación de bases de datos NoSQL?
La indexación examina los datos y determina cómo volver a encontrar esos elementos. La indexación puede aplicarse a documentos JSON, claves/campos o valores en campos. Las claves de los documentos JSON actúan como los nombres de columna en los sistemas de indexación de bases de datos tabulares.
La base de datos gestiona estas colecciones de elementos y valores como índices que remiten a la fuente. El backend de la base de datos actualiza la indexación a medida que cambian los documentos mientras se almacenan los datos. Mientras tanto, los administradores de bases de datos pueden optimizar la indexación para casos de uso específicos, como escrituras o consultas de gran volumen.
Mediante el uso de índices, las consultas N1QL pueden encontrar rápidamente valores de campo que coincidan sin necesidad de escanear los datos originales. Este método también se aplica a las estructuras de datos comunes, colecciones y ámbitos introducidos en Couchbase 7.0.
Consulta de estructuras de datos Couchbase con N1QL
La consola web de Couchbase es una manera fácil de ver documentos de estructura de datos en la base de datos. Observa cómo los documentos de estructura de datos son a menudo mucho más simples que los documentos JSON más complejos.
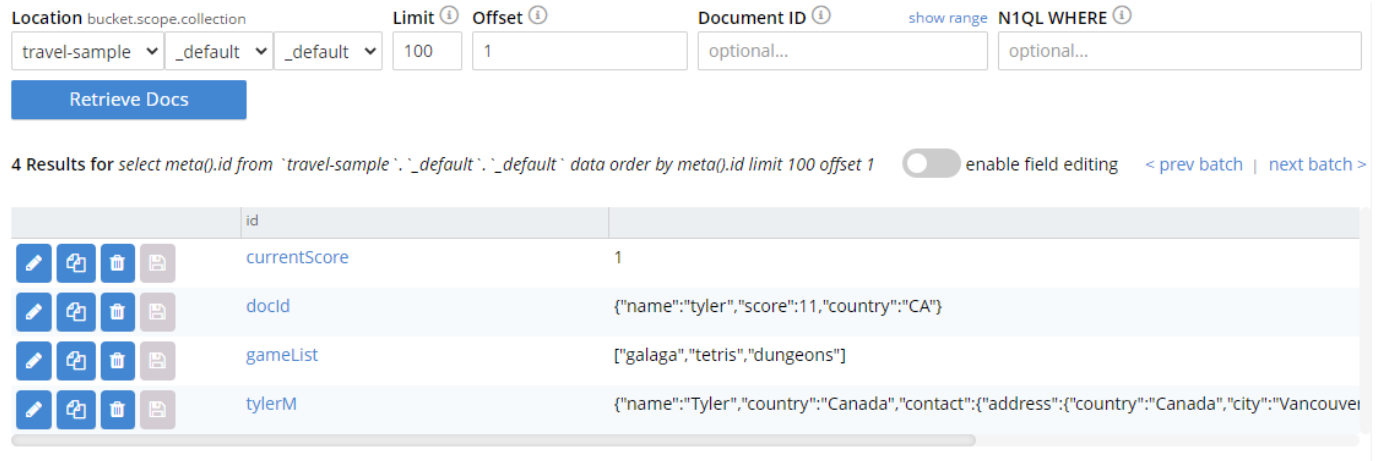
Lista de documentos de estructuras de datos en el bucket
Para empezar a escribir consultas N1QL, es necesario indexar los datos de la estructura de datos. Como mínimo, se necesita un índice primario a nivel de bucket para las operaciones básicas.
|
1 |
CREATE PRIMARY INDEX ON `travel-sample`; |
Para los documentos que utilizan las nuevas funciones de colecciones de Couchbase 7.0también deben estar indexados.
|
1 |
CREATE PRIMARY INDEX ON `travel-sample`.`scope1`.`col1` |
Pndices rimarios lucha con grandes conjuntos de datos pero son excelentes para explorar rápidamente pequeñas cantidades de datos. Utilice índices secundarios globales (GSI) cuando avance hacia la producción en un proyecto de big data.
Listado de todos los documentos de datos e identificaciones
Sin embargo, no siempre es posible una indexación más específica, ya que las estructuras de datos pueden no tener claves con nombre. Por ejemplo, un contador es sólo un ID y un valor entero sin nombre de campo. Pero, si tienes un mapa, puedes crear un índice que tenga como objetivo una clave interna.
Una consulta básica del ID del documento puede devolver todos los documentos y mostrar los nombres de los campos utilizados.
|
1 |
SELECT META().id, * FROM `travel-sample` |
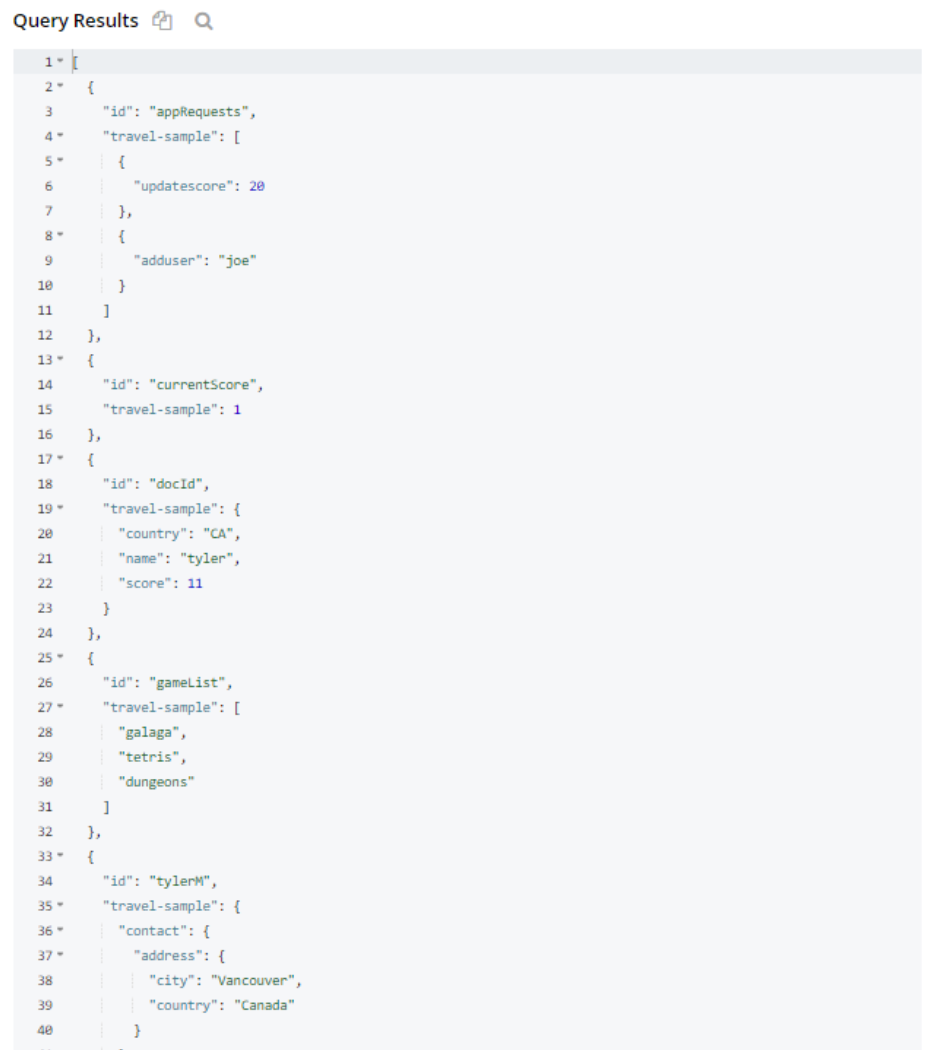
Puntuación actual es un contador básico, mientras que gameList es una lista/colección, etc.
Consulta de ámbitos/colecciones para estructuras de datos
Si utiliza ámbitos y colecciones, añádalos a la cláusula from.
|
1 |
SELECT * FROM `travel-sample`.`scope1`.`col1` |
Recupera un valor específico de un objeto de estructura de datos con nombre añadiéndolo a la cláusula where.
|
1 |
SELECT META().id, * FROM `travel-sample` WHERE META().id = 'currentScore' |
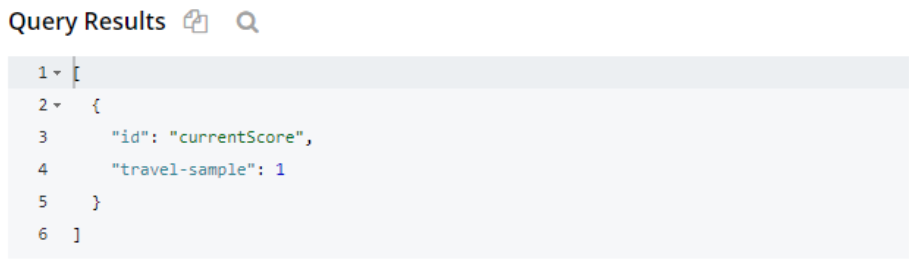
Cuando se especifican nombres de campo (y ningún ID) la consulta devuelve valores coincidentes en todos los documentos.
|
1 |
SELECT name, contact FROM `travel-sample` |
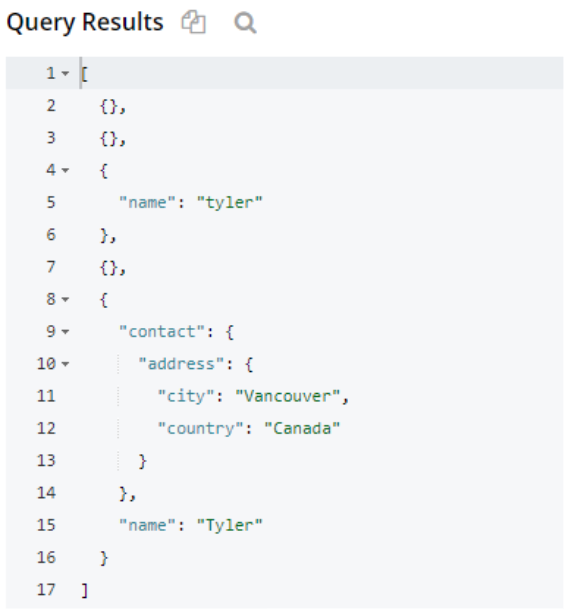
La consulta devuelve objetos con los campos específicos y sus valores. En los resultados anteriores, sólo una de las estructuras de datos tenía el valor póngase en contacto con campo. Otros dos tenían un nombre pero varios objetos en blanco muestran que no había campos coincidentes.
Para ser escalables, todas las aplicaciones de consulta deben utilizar también índices secundarios globales (GSI) para campos específicos.
Este Mejores prácticas de indexación de bases de datos El artículo cubre más escenarios informáticos utilizados en la ingeniería de software de big data.
Unirlo todo
Como puedes ver, consultar documentos y subcomponentes relacionados es muy sencillo usando Couchbase. El uso estratégico de sofisticados métodos de indexación proporciona aún más formas de acceder a los datos que tus aplicaciones están creando.
Couchbase simplifica drásticamente las arquitecturas de sistemas, permitiendo a los desarrolladores empezar sin mucho trabajo. Estas referencias te ayudarán a empezar rápidamente.
- Estructuras de datos para aplicaciones NoSQL en Couchbase 7.0
- Ámbitos y colecciones para aplicaciones multiusuario
- API de estructuras de datos de Couchbase (SDK de Python)
- Subdocumento operaciones docs (SDK de Python)
- Mejores prácticas de indexación de sistemas de bases de datos NoSQL
- Mejores prácticas de indexación de búsquedas de texto completo NoSQL
- Documentación de búsqueda de texto completo