Pasar de MongoDB al servidor Couchbase
Esta es una guía centrada en el desarrollador para trasladar el almacén de datos de su aplicación de MongoDB a Couchbase Server, como continuación de la publicación de Laurent Guía para pasar de PostgreSQL.
Aunque no cubre todos los casos, ofrece indicaciones sobre lo que debe tener en cuenta al planificar su migración.
Versiones
Esta guía está escrita para Couchbase Server 4.1 y MongoDB 3.2.
Principales diferencias
Couchbase Server y MongoDB son almacenes de documentos que pueden operar en uno o varios servidores. Sin embargo, abordan las cosas de maneras significativamente diferentes.
Cuando empieces tu migración de MongoDB a Couchbase Server, tendrás que tener en cuenta las siguientes diferencias:
| Servidor Couchbase | MongoDB | ||
|---|---|---|---|
| Modelos de datos | Documento, clave-valor | Documento | |
| Consulta | N1QL (SQL para JSON), vistas map/reduce, clave-valor | Consulta ad hoc, agregación map/reduce | |
| Concurrencia | Bloqueo optimista y pesimista |
|
|
| Modelo de escala | Distribuido maestro-maestro | Maestro-esclavo con conjuntos de réplicas |
Modelo de datos
Couchbase Server es tanto un almacén de documentos como un almacén clave-valor.
Todo empieza con clave-valor, ya que cada documento tiene una clave que puedes usar para obtener y establecer el contenido del documento. Sin embargo, puedes usar Couchbase Server como una base de datos de documentos indexando y consultando el contenido de los documentos.
Diferencias entre BSON y JSON
Es probable que tu aplicación almacene documentos de tipo JSON en MongoDB, así que empezaremos por ahí.
MongoDB almacena datos en formato BSON, que es un formato binario similar a JSON. La diferencia clave para nosotros es que BSON registra información de tipo adicional.
Al exportar datos de MongoDB mediante una herramienta como mongoexport la herramienta producirá JSON que conserva esa información de tipo en un formato denominado JSON extendido.
Veamos un ejemplo. Primero en JSON estándar:
|
1 2 3 |
{ "created_at": "2016-01-27T16:00:58+00:00" } |
Y ahora en JSON extendido:
|
1 2 3 4 5 |
{ "created_at": { "$date": "1453910458" } } |
Como puedes ver, el JSON extendido sigue siendo JSON válido. Eso significa que puedes almacenarlo, indexarlo, consultarlo y recuperarlo usando Couchbase Server. Sin embargo, necesitarás mantener esa información de tipo adicional en la capa de aplicación.
Alternativamente, puedes convertir el JSON extendido a JSON estándar antes de importarlo a Couchbase Server.
Datos no JSON
Tanto MongoDB como Couchbase Server pueden almacenar datos binarios opacos.
Aunque la representación interna de los datos binarios difiere mucho entre ambos, puedes seguir almacenando en Couchbase Server los datos binarios que has estado almacenando en MongoDB.
La principal diferencia es que Couchbase Server puede almacenar binarios de hasta 20 MB de tamaño, mientras que MongoDB ofrece una capa de conveniencia para fragmentar archivos muy grandes en múltiples documentos.
Hay argumentos de peso en contra de almacenar binarios de gran tamaño en la base de datos. Cuando tengas muchos binarios muy grandes, puedes considerar usar un servicio dedicado de almacenamiento de objetos para almacenarlos mientras usas Couchbase para mantener los metadatos de esos binarios.
Arquitectura
Fragmentación
Couchbase Server fragmenta los datos y escala horizontalmente distribuyendo automáticamente un espacio hash entre los nodos de un clúster.
A continuación, utiliza la clave de tu documento para decidir en qué parte del espacio hash -y, por tanto, en qué nodo del clúster- reside ese documento. Como desarrollador, esto se abstrae para ti en el SDK del cliente.
Con MongoDB necesitas elegir un método de fragmentación y una clave de fragmentación. La clave de fragmentación es un campo indexado dentro del documento que determina en qué parte del clúster reside el documento.
La principal diferencia aquí es que Couchbase Server maneja automáticamente toda la fragmentación por ti, mientras que MongoDB te da la opción de elegir el método de fragmentación y la clave de fragmentación. Si tus aplicaciones dependen de una distribución particular de datos a través del cluster, entonces necesitarás ajustarlo para permitir la distribución basada en hash usada por Couchbase.
La fragmentación basada en hash simplifica enormemente el escalado en comparación con MongoDB. Como desarrollador, esto puede parecer más un problema para tu equipo de operaciones. Sin embargo, significa que es más fácil confiar en Couchbase Server si el uso de tu software crece.
Replicación y coherencia
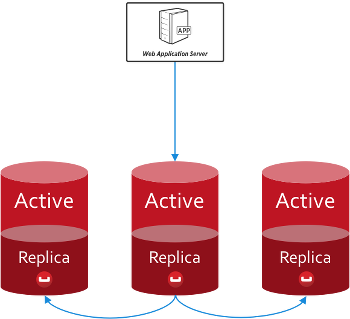 Couchbase Server mantiene una única copia activa de cada documento y luego hasta dos réplicas; puedes configurar el número de réplicas a nivel de bucket o por operación.
Couchbase Server mantiene una única copia activa de cada documento y luego hasta dos réplicas; puedes configurar el número de réplicas a nivel de bucket o por operación.
Esto significa que, en condiciones normales de funcionamiento, cada vez que se escribe en un documento o se lee de él, se trabaja con la misma copia. De este modo, no es necesario manejar versiones conflictivas de los documentos. Las réplicas sólo entran en juego cuando la copia activa no está disponible.
Como desarrollador, la distribución y replicación de documentos se abstrae por ti. Usted escribe, lee y consulta utilizando su conexión al bucket y el SDK gestiona con precisión dónde se almacenan esos datos. No hay necesidad de tener en cuenta conjuntos de réplica o esquemas de fragmentación.
Si conoce el Teorema CAP entonces también sabrá que favorecer la coherencia tiene un efecto sobre la disponibilidad. En caso de fallo de un nodo, sus documentos activos no estarán disponibles durante un breve periodo de tiempo para permitir que el clúster promueva las réplicas apropiadas al estado activo. En tu código, todo lo que tienes que hacer es reintentar una operación fallida.
Indexación
Couchbase Server ofrece dos grandes tipos de índices:
- GSI: índices secundarios globales
- vistas: generadas por consultas map-reduce.
La diferencia es más que un detalle de implementación, ya que ambos tipos de índices se crean y gestionan de forma diferente. En general, utilizarás índices GSI para replicar tus índices MongoDB.
| MongoDB | Servidor Couchbase |
|---|---|
| Campo único | GSI |
| Índice compuesto | GSI |
| Índice multiclave | GSI |
| Índice geoespacial | Índice espacial en las vistas |
| Índice de texto | La búsqueda de texto libre de Couchbase llegará a la próxima versión de Couchbase Server |
Tipos de nodos
Cuando creces más allá de un servidor MongoDB necesitas introducir procesos de enrutamiento y servidores de configuración.
Con Couchbase Server, ambas funciones se encuentran en el SDK del cliente. Cuando te conectas al cluster desde tu aplicación, el SDK recibe un mapa de dónde vive cada fragmento en el cluster. Couchbase Server entonces actualiza automáticamente el mapa del cluster cada vez que la forma del cluster cambia. Cada petición pasa directamente del servidor de la aplicación al nodo de Couchbase correspondiente.
Una vez que su clúster crezca, podrá optar por ejecutar nodos especializados en datos, consultas e indexación. Más información sobre el escalado multidimensional.
Todo esto ocurre de forma transparente para usted como desarrollador.
Cubos y colecciones
Tanto Couchbase Server como MongoDB te permiten dividir tu conjunto de datos en grupos de documentos: Couchbase tiene buckets y MongoDB tiene colecciones.
Mientras que las colecciones de MongoDB tienen un alcance equivalente a las tablas relacionales, los buckets de Couchbase Server son quizás más el equivalente a una base de datos relacional.
Esta distinción es importante porque normalmente no querrás más de diez buckets en un único cluster de Couchbase. Esto los hace un poco inadecuados como espacios de nombres y en su lugar sirven como una forma de compartir las decisiones de configuración entre tipos similares de documentos.
Esto tiene dos consecuencias principales:
- necesita otra forma de asignar nombres a sus documentos
- hay que pensar cuándo conviene crear un nuevo cubo.
Cuándo utilizar cubos múltiples
En primer lugar, hay que pensar en cómo asignar recursos a los cubos. Las dos grandes consideraciones son:
- RAM
- vistas e índices.
Cuando creas un bucket, le asignas una parte de la RAM de cada máquina. La memoria RAM que asignes a un bucket debe ser lo suficientemente grande como para almacenar el conjunto de trabajo de esos datos más los pocos bytes de metadatos asociados a cada documento.
Esto significa que puedes asignar diferentes cantidades de RAM a diferentes conjuntos de datos en función de cómo accedas a ellos.
Del mismo modo, las vistas y los índices de Couchbase se ejecutan a través de los documentos dentro de un bucket, al igual que una consulta map-reduce de MongoDB se ejecuta a través de una sola colección.
Si tienes algunos documentos que no necesitan indexación -porque sólo accedes a ellos a través de su clave- y tienes algunos grupos de documentos que tienen velocidades diferentes, puedes ver que sería prudente no ejecutar nunca los indexadores en el primer grupo de datos y ejecutar los indexadores con intervalos adecuados en el resto.
Dividir nuestros datos en distintos buckets nos permite lograr tanto un buen uso de la RAM como del tiempo de CPU que necesitan los indexadores.
Veamos el ejemplo de una aplicación de comercio electrónico, los datos que almacenaría, su perfil y cómo responde a ello en la configuración de su bucket.
| Tipo de datos | Perfil de datos | Perfil del cubo |
|---|---|---|
| Sesiones | Respuestas rápidas, acceso clave-valor, sesiones concurrentes predecibles | RAM para el número típico de sesiones en directo, sin indexación |
| Perfiles de usuario | Respuestas rápidas mientras los usuarios están activos, los datos cambian lentamente | RAM para adaptarse a los perfiles de usuario para el número típico de sesiones en directo, indexación en |
| Datos del pedido | Lectura intensiva tras la creación inicial, corta vida útil | RAM para adaptarse a los pedidos de un número típico de sesiones en directo, indexación en |
| Datos del producto | Se necesitan respuestas rápidas, leer pesado | RAM para todo el catálogo, indexación en |
Es algo más complicado que decidir si la indexación está activada o desactivada. Más bien, se eligen los tipos de índice y la velocidad de las actualizaciones decide con qué frecuencia se ejecutan los indexadores. Mezclar datos lentos y rápidos puede resultar ineficaz, ya que los indexadores de un bucket recorren todos los documentos de ese bucket, incluidos los que no se han modificado.
Asignación de nombres a los documentos
Si no podemos utilizar cubos como espacios de nombres, ¿cómo distinguimos fácilmente los distintos tipos de documentos?
Deberías usar una combinación de:
- nombre de la llave
- utilizando un "tipo" en su documento JSON.
Utilización de prefijos y sufijos semánticos en los nombres de las claves es una forma sencilla de asignar un espacio de nombre a los documentos, sobre todo cuando se utiliza Couchbase para claves-valores.
Al exigir un tipo en los esquemas de los documentos, se obtienen los datos necesarios para crear consultas que sólo se aplican a determinados tipos de documentos.
Modelo de programación
Hay tres formas de trabajar con Couchbase Server:
- acceso simple clave-valor: gran coherencia, respuestas en submilisegundos
- vistas: generadas por consultas map-reduce
- N1QL: Consultas tipo SQL con JOINs.
Viniendo de MongoDB, puede que tengas la tentación de traducir todas tus consultas de MongoDB a N1QL. Sin embargo, vale la pena pensar en los méritos relativos de cada uno y luego usar la mezcla que se adapte a tus necesidades.
Se puede llegar muy lejos con el acceso clave-valor, por ejemplo utilizando índices secundarios manuales.
Consulta
Para consultas ad-hoc, Couchbase Server ofrece N1QL. N1QL es un lenguaje similar a SQL, por lo que es bastante diferente de la consulta de MongoDB.
Veamos un ejemplo en el que devolvemos el nombre de los empleados de la oficina de Londres que han trabajado allí durante dos años o más, ordenados por fecha de inicio:
|
1 2 3 4 |
SELECT name FROM `hr` WHERE office='London' AND type='employee' AND DATE_DIFF_MILLIS(startDate, NOW_MILLIS) >= 63113904000 ORDER BY startDate; |
Como puedes ver, N1QL es muy familiar si alguna vez has trabajado con SQL. Podrás traducir tus consultas MongoDB a N1QL con relativamente poco esfuerzo.
Antes de comenzar a reescribir sus consultas, debe considerar una gran ventaja que ofrece N1QL: puede realizar JOINs a través de documentos. Tomemos nuestra consulta anterior y devolvamos también el nombre del gerente de cada persona.
|
1 2 3 4 5 6 |
SELECT r.name, s.name AS manager FROM `hr` r JOIN `hr` s ON KEYS r.manager WHERE r.office='London' AND r.type='employee' AND DATE_DIFF_MILLIS(r.startDate, NOW_MILLIS) >= 63113904000 ORDER BY r.startDate; |
Más información sobre N1QL y acerca de las vistas.
Concurrencia
En Couchbase Server, el bloqueo siempre ocurre a nivel de documento y hay dos tipos:
- pesimista: ningún otro actor puede escribir en ese documento hasta que se libere o se alcance un tiempo de espera
- optimista: utilice los valores CAS para comprobar si el documento ha cambiado desde la última vez que lo tocó y actúe en consecuencia.
En una base de datos distribuida, el bloqueo optimista es un enfoque mucho más vecino. Más información sobre cómo elegir el tipo de cerradura adecuado.
Bibliotecas e integraciones
Existen SDK compatibles oficialmente para los principales lenguajes, incluidos Java, .NET, NodeJS, Python, Go, Ruby y C. También encontrará bibliotecas cliente desarrolladas por la comunidad para lenguajes como Erlang.
También existen integraciones oficiales con Datos de primaveraSpark, Hadoop, Elasticsearch, .NET's Linq y hay un NodeJS ODM llamado Ottoman.
Conclusión
Pasar de un almacén de documentos a otro es relativamente sencillo, ya que la forma general de los datos no tiene por qué cambiar demasiado.
Como desarrollador portando una aplicación de MongoDB a Couchbase Server, tus principales consideraciones son que necesitas:
- sustituir el espaciado de nombres de las colecciones por nombres de claves y tipos de documentos
- simplifique sus consultas utilizando N1QL JOINs
- considerar dónde el acceso clave-valor puede ser la mejor opción.
Si estás cambiando de MongoDB a Couchbase Server, seguro que no eres el primero. Eso es una gran noticia para ti porque encontrarás gente que ya ha hecho el cambio antes en nuestro foros.