Toda la comunidad de desarrolladores web está entusiasmada con Kubernetes (K8s). No es de extrañar que sea el tema más candente en las conferencias y eventos para desarrolladores a los que he asistido el último año.
No es sólo una herramienta para gestionar contenedores, de hecho, K8s le permite añadir fácilmente equilibrio de carga y evita la necesidad de un capa de descubrimiento de servicios (ya no necesita eureka por ejemplo). K8s también automatiza los despliegues y actualizaciones de aplicaciones y, lo que es más importante, le permite conectar/escribir controladores personalizados para su infraestructura.
Fantástico, ¿verdad? Pero la gestión de contenedores sin estado no es tan complicada, después de todo, son esencialmente efímeros y puede matar y girar instancias como desee sin efectos secundarios considerables.
Pero esto es la mitad de la historia, en general, las aplicaciones no pueden ser totalmente sin estado, y en la mayoría de los casos, simplemente empujamos el estado a las capas inferiores. Entonces, ¿cómo lidiamos con aplicaciones con estado en K8s? Afortunadamente, desde la versión 1.5 existe algo llamado StatefulSets.
Contenedores con estado
Kubernetes StatefulSets te da un conjunto de recursos para manejar contenedores con estado, tales como: volúmenes, ids de red estables, índices ordinales de 0 a N, etc. Los volúmenes son una de las características clave que nos permiten ejecutar aplicaciones con estado sobre Kubernetes, veamos los dos tipos principales soportados actualmente:
Almacenamientos efímeros volumes
El comportamiento de los almacenamientos efímeros es diferente a lo que estás acostumbrado en Docker, en Kubernetes el volumen sobrevive a cualquier contenedor que se ejecute dentro del Pod y los datos se conservan a través de reinicios de contenedores. Pero si el Pod muere, el volumen se elimina automáticamente.
Volúmenes de almacenamiento persistentes
En un almacenamiento persistente, como su nombre indica, el tiempo de vida de los datos es independiente del tiempo de vida del Pod. Así, incluso cuando el Pod muere o es movido a otro nodo, esos datos persisten hasta que son explícitamente borrados por el usuario. En ese tipo de volúmenes, los datos se almacenan típicamente a distancia.
Estamos deseando que la compatibilidad con Kubernetes llegue a Almacenes locales persistentes ya que sin duda será el más adecuado para ejecutar bases de datos, pero mientras tanto, utilizamos almacenamientos efímeros por defecto. Llegados a este punto, puede que te preguntes por qué utilizamos almacenamientos efímeros en lugar de persistentes. No es sorprendente, hay muchas razones para ello:
- Los almacenamientos efímeros son más rápidos y baratos que los persistentes. Utilizar almacenamientos persistentes requiere más infraestructura y redes, ya que hay que enviar los datos de un lado a otro.
- Presentación de K8s 1.9 Soporte para bloques en brutoque le permite acceder a los discos físicos de su instancia VM para utilizarlos en su aplicación.
- Mantener los sistemas de almacenamiento en red no es trivial
- Siempre puedes intentar reiniciar primero el contenedor en lugar de matar todo el Pod:
1kubectl exec POD_NAME -c NOMBRE_DEL_CONTENEDOR reiniciar - Puedes configurar Couchbase para que replique automáticamente tus datos, de modo que incluso si N Pods muere, no se perderá ningún dato.
- Parte del trabajo de K8 es hacer funcionar Pods en diferentes racks para evitar fallos masivos.
Sin embargo, hay algunos escenarios en los que utilizar Almacenamientos Remotos Persistentes merecería la pena por el coste extra de latencia, como en bases de datos masivas, por ejemplo, cuando el proceso de reequilibrado tarda varios minutos en finalizar. Por eso también añadiremos soporte para Almacenamientos Remotos Persistentes.
Uno de los inconvenientes de Statefulsets es la gestión limitada, por eso decidimos extendemos la API de Kubernetes mediante el uso de una Custom Resource Definition (CRD), que nos permite crear un recurso nativo personalizado en Kubernetes similar a un StatefulSet o un Deployment, pero diseñado específicamente para gestionar instancias de Couchbase.
¡Genial! Entonces, con StatefulSets/CRDs tenemos todas las operaciones de hardware arregladas, sólo falta una "pequeña" cosa aquí, ¿qué pasa con el estado de la propia aplicación? En una base de datos, por ejemplo, la adición de un nuevo nodo al clúster no es suficiente, todavía sería necesario desencadenar algunos procesos, como el reequilibrio para mover / replicar algunos de los datos en el nodo recién añadido para que sea plenamente operativo. Esa es exactamente la razón por la que los Operadores K8s entraron en el juego.
Operadores de Kubernetes
Kubernetes 1.7 ha añadido una importante función denominada Controladores personalizados. En resumen, permite desarrolladores para ampliar y añadir nuevas funcionalidades, sustituir las existentes (como sustituir kube-proxy, por ejemplo) y, por supuesto, automatizar las tareas de administración. como si fueran un componente nativo de Kubernetes.
Un Operador no es más que un conjunto de controladores personalizados específicos de una aplicación. Entonces, ¿por qué es un cambio de juego? Bueno, los controladores tienen acceso directo a la API de Kubernetes, lo que significa que pueden supervisar el clúster, cambiar pods/servicios, escalar hacia arriba/hacia abajo y llamar a endpoints de las aplicaciones en ejecución, todo ello de acuerdo con reglas personalizadas escritas dentro de esos controladores.
Para ilustrar este comportamiento, veamos cómo funciona el Operador de Couchbase cuando se mata un Pod:
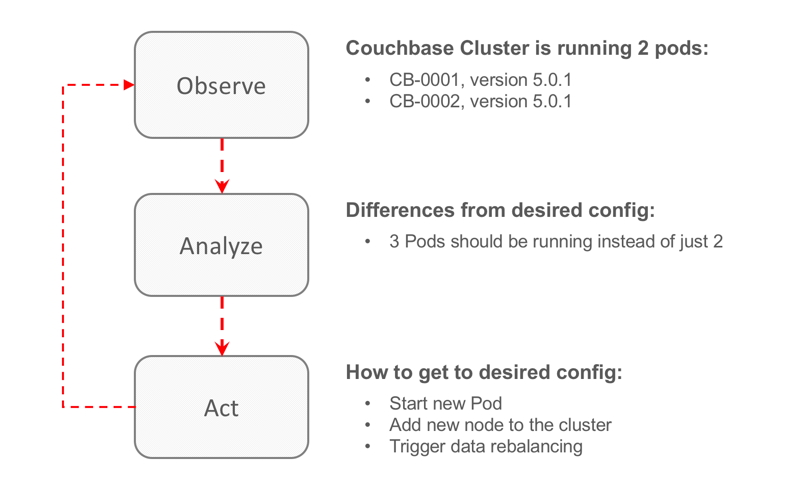
Más información sobre los operadores aquí
Como puede verse en la figura anterior, el Operador supervisa y analiza el clúster y, basándose en un conjunto de parámetros, desencadena una serie de acciones para alcanzar el estado deseado. Este proceso de reconciliación está en todas partes en K8s. Pero no todas las acciones son iguales, en nuestro ejemplo, tenemos dos categorías distintas:
- Infraestructura - añadir un nuevo nodo: El operador solicita a través de la API de Kubernetes lanzar un nuevo Pod ejecutando Couchbase Server.
- Específico de dominio - Añadir nodo al clúster/ Activar el reequilibrio de datos: El operador sabe cómo funciona Couchbase y llama al punto final rest correcto para añadir el nuevo nodo al clúster y activar el reequilibrio de datos.
Ese es el verdadero poder de los Operadores, permiten escribir una aplicación para gestionar completamente otra¿Y adivina qué tipo de aplicaciones con estado son las más difíciles de gestionar? Pues sí: Las bases de datos.
Los desarrolladores siempre han esperado que las bases de datos funcionen a la primera, cuando en realidad, históricamente son exactamente lo contrario. Incluso tenemos un nombre específico para la persona responsable de cuidar la base de datos, nuestros queridos DBA.
Couchbase's Operator se creó como un esfuerzo para cambiar este escenario y hacer que las bases de datos sean fáciles de gestionar sin atarte a un proveedor de nube específico. Actualmente, soporta el aprovisionamiento automatizado de clústeres, escalabilidad elástica, auto-recuperación, registro y acceso a la consola web, pero muchas más características vendrán en el futuro. Si desea obtener más información, consulte este artículo o consulte la documentación oficial de Couchbase aquí.
También tengo que mencionar que es el primer operador oficial lanzado para una base de datos, y hay algunos pequeños proyectos de la comunidad ya tratando de construir operadores para MySQL, Postrgres y otras bases de datos.
El ecosistema del operador crece rápidamente, graja por ejemplo, permite desplegar algo muy similar a AWS S3. El operador Apache Kafka Kubernetes llegará pronto y existen muchas otras iniciativas. Esperamos un gran impulso en el número de operadores en los próximos meses, ahora que todos los principales proveedores de nube soportan K8s.
Por último, Kubernetes proporciona un despliegue y una gestión de aplicaciones agnósticos respecto a la nube. Es tan potente que podría llevarnos a tratar a los proveedores de nube casi como una mercancía, ya que podrás migrar libremente entre ellos.
En el futuro, elegir un proveedor de nube podría ser sólo cuestión de cuál ofrece el mejor rendimiento/coste. El impacto de este cambio radical en el mercado aún no está claro, pero los desarrolladores somos sin duda los grandes beneficiados.
ACTUALIZACIÓN: Aunque este artículo se escribió no hace mucho, muchas cosas ya han cambiado. Ahora tenemos el Operador autónomo Couchbase 1.2, Almacenamiento local persistente es GA, y hay un Operador Hub para centralizar todos los operadores de código abierto.
Si tiene alguna pregunta, no dude en tuitearme en @deniswsrosa
Un blog muy informativo y conciso.