Arkadiusz Borucki trabaja como a Ingeniero de fiabilidad de sitios en Amadeus, centrado en bases de datos NoSQL y automatización. En su trabajo diario, utiliza Couchbase, MongoDB, Oracle, Python y Ansible. Es un autoproclamado entusiasta de los grandes datos, interesado en las tecnologías de almacenamiento de datos, sistemas distribuidos, análisis y automatización. Es ponente en varias conferencias y grupos de usuarios en Estados Unidos y Europa. Puedes encontrarle en Twitter en @_Aras_B

Motivación: Por qué utilizar la Infraestructura como Código
Muchos equipos informáticos siguen confiando en la configuración manual para gestionar la infraestructura: todavía se utilizan procedimientos antiguos y secuencias de comandos de shell obsoletas.
A veces, los miembros de un mismo equipo utilizan procedimientos y scripts diferentes para la misma granja de bases de datos. Esas personas pueden abandonar la empresa sin compartir conocimientos ni consejos. Este enfoque da lugar a problemas, errores, despliegues lentos y entornos incoherentes.
Las granjas de servidores son cada vez más grandes y el tamaño de los datos pasa de gigabytes a tera o petabytes. Una sola máquina ya no es capaz de manejar esta cantidad de datos. Por tanto, tenemos que escalar nuestra base de datos horizontalmente, utilizar más máquinas y distribuir los datos entre ellas.
Cuando tengamos dos, cinco o diez agrupaciones "de la vieja escuela" creadas sobre la base de procedimientos y guiones, será suficiente. Los problemas surgen cuando la explotación crece rápidamente.
- ¿Qué hacer cuando el despliegue tiene cientos de servidores?
- Cómo asegurarse el entorno es coherente?
- Cómo controlar lo que se instala en el ¿Máquinas?
- Cómo realizar un seguimiento de todos el ¿cambios?
La información sobre la configuración de la infraestructura debe estar centralizada. La infraestructura debe tratarse como el software - como código que pueden gestionarse con las mismas herramientas y procesos que utilizan los desarrolladores de software. Por ejemplo, utilizar código para describir la infraestructura. Cree un modelo de su despliegue de Couchbase - como código con control de versiones en él. No sólo podrás hacer un seguimiento de quién ha hecho qué, sino que también podrás volver a una configuración anterior. El despliegue de Couchbase será consistente porque se aplicará la misma configuración a todas las máquinas. Para prevenir futuros problemas e interrupciones tu granja de Couchbase debe ser consistente, la configuración debe estar centralizada y dividida entre entornos de producción y no producción.
Puedes probar nuevas configuraciones y ajustes en la rama de pruebas o desarrollo antes de aplicar esos cambios en la de producción.
Codifíquelo todo
Utilice el código para describir la infraestructura. Utilice Ansible para la gestión de servidores físicos o virtuales (aplicación de parches, actualizaciones, gestión de la configuración, gestión de redes, despliegue de nuevos clústeres, orquestación).
Versión todo
Utilice Git para gestionar la infraestructura como un repositorio de código. Git es un sistema de control de versiones distribuido de código abierto. Utilice un ramificación según las necesidades de su empresa (rama de producción y rama de pruebas).
Gestione su despliegue de Couchbase con Git
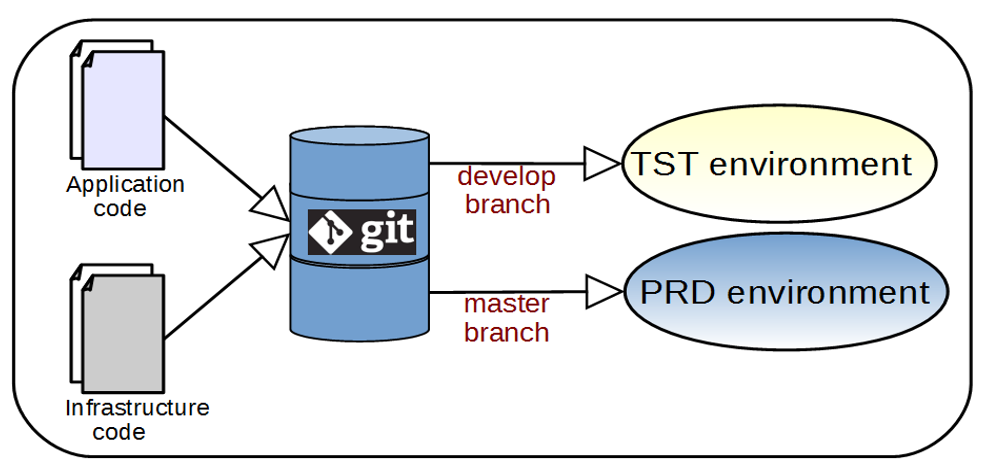
Un depósito
Utiliza una infraestructura Git como repositorio de código por organización o empresa. En un repositorio Git puedes tener varias ramas (producción, desarrollo, pruebas, staging, etc.).
Ansible: Cómo operar de forma distribuida Couchbase grupo
Las operaciones manuales en una granja de bases de datos consumen tiempo y recursos. Más operaciones manuales conllevan más errores humanos, más sobrecarga e incoherencia.
¿Se imagina una granja con 400 servidores? ¿Cuánto tiempo se tarda en entrar en cada máquina y cambiar la configuración? ¿Y si se salta una o dos máquinas? ¿Y si aplica por error configuraciones diferentes en algunas máquinas?
Ansible es una herramienta perfecta para la gestión de la configuración y la orquestación de su infraestructura. Usando Ansible puedes ir con Infraestructura como código (mantener la definición del servidor Couchbase en el repositorio Git, rastrear los cambios, y utilizar todas las ventajas que vienen con el control de versiones Git).
Utilizar Ansible módulo git para desplegar cambios desde el repositorio Git en su granja de bases de datos distribuidas. El módulo git de Ansible toma el código de la url git especificada y lo coloca en el directorio de destino.
- Ansible no tiene agente y utiliza un enfoque push (SSH).
- Ansible se basa en archivos YAML.
- Es una buena alternativa a Puppet.
- Ansible reduce los pasos manuales en los servidores.
- Ansible ayuda a Reducción 95% en gastos generales de explotación
Automatización
- Reduzca la sobrecarga y los errores humanos, acelere los procesos, proporcione coherencia: utilice Ansible para la automatización de su granja de Couchbase.
Orquestación
- Pongamos lógica en la automatización y eliminemos pasos repetitivos. Ansible también puede utilizarse como orquestador.
Automatización se ocupa de una única tarea: iniciar el servicio Couchbase, configurar un clúster, detener el proceso Couchbase.
Orquestación se ocupa de automatizar la ejecución del flujo de trabajo de un proceso.
# Ejemplo de git checkout desde Ansible Playbook
|
1 2 3 4 5 6 7 |
--- - name: "git checkout" - git: repo: 'https://server/path/to/repo.git' dest: /opt/couchbase version: staging |
Utiliza la opción de versión para especificar una rama en particular, una etiqueta o un identificador de confirmación. Una vez que extraigas el código del repositorio Git puedes aplicarlo a tu despliegue de Couchbase. Puedes aplicarlo en todos los servidores o sólo en una parte de la granja. También puedes especificar una lista de hosts en el archivo de inventario de Ansible y ejecutarlo así:
# Ejemplo ejecutar Ansible Playbook para cluster "couchstg"
|
1 |
ansible-playbook -i ./inventory/hosts.inv -l 'couchstg' ./couchbase_upgradel.yml --ask-vault-pass |
Git: ¿Qué podemos guardar en Git?
Configuración del servidor repositorios:
- La disposición por defecto de los sistemas de archivos
- Lista de paquetes linux necesarios
- Parámetros del núcleo
- Usuarios y grupos necesarios
- Scripts Cron
- Ajustes de seguridad
Repositorios Couchbase/Ansible:
- Definición del clúster Couchbase
- Couchbase Ansible playbooks
- Funciones de Couchbase
- Archivos de inventario de hosts Couchbase
- Configuración RBAC
- Configuración XDCR
Ansible: ¿Qué debe automatizarse?
- Despliegue de clústeres
- Actualizaciones
- Escala
- Resiliencia
- Supervisión
- Alerta
- Ajustes de seguridad
- Copia de seguridad y restauración
-
Reequilibrio del clúster Couchbase
- Conmutación por error de Couchbase
- Creación de cubos Couchbase
- Kernel Linux y parches de seguridad
- Cualquier actividad manual desde la GUI o shell de Couchbase
Las instalaciones manuales de clústeres y la gestión manual de nodos no deberían ser soportadas. Automatiza todo lo posible y envía siempre los cambios de código a Git. Couchbase proporciona API REST puntos finales. Desde el playbook de Ansible puedes usar métodos HTTP - GET, POST, PUT, DELETE.
La API REST de Couchbase te permite realizar cualquier cambio en una granja de Couchbase sin un solo clic en la GUI.
Ansible playbook también puede ejecutar comandos CLI de Couchbase:
# Ejemplo de auto failover (comandos CLI) desde Ansible Playbook
|
1 2 3 |
- name: auto failover command: /opt/couchbase/bin/couchbase-cli setting-autofailover -c localhost --enable-auto-failover={{ autofailover }} --auto-failover-timeout= {{ timeout }} -u {{ admin }} -p {{ passwd }} |
o # Ejemplo de reequilibrio desde Ansible Playbook
|
1 2 3 |
- name: rebalance cluster command: /opt/couchbase/bin/couchbase-cli rebalance -c localhost -u {{ admin }} -p {{ passwd }} |
# Ejemplo Instalar servidor couchbase desde Ansible Playbook
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
- name: "Install couchbase database" package: name=couchbase-server state=present notify: - wait for database start tags: installation - name: "Add couchbase database to linux runlevel" service: name=couchbase-server state=started enabled=yes tags: installation |
Couchbase: API REST
Couchbase API REST le permite gestionar la implementación de un servidor Couchbase, así como realizar operaciones como almacenar documentos de diseño y consultar resultados directamente desde el playbook de Ansible.
Puedes hacer fácilmente llamadas a la API REST de Couchbase desde tu código Ansible. También puedes crear roles Ansible personalizados para Couchbase.
Couchbase ofrece lo siguiente API RESTs:
- API de clúster - La API REST del clúster gestiona las operaciones del clúster
- API de nodos de servidor - La API REST de nodos de servidor gestiona los nodos de un clúster
- API de grupos de servidores - La API REST de grupos de servidores hace referencia a la función Rack Zone Awareness, que permite agrupaciones lógicas de servidores en un clúster en el que cada grupo de servidores pertenece físicamente a un rack o zona de disponibilidad.
- API de cubos - La API REST de cubos crea, elimina, vacía y recupera información sobre cubos y operaciones con cubos.
- API de vistas - La API REST de Views se utiliza para indexar y consultar documentos JSON.
- API XDCR - La API XDCR REST se utiliza para gestionar las operaciones de Replicación entre Centros de Datos (XDCR)
- API de registros - La API REST de registros proporciona los puntos finales de la API REST para recuperar información de registro y diagnóstico, así como la forma en que un SDK puede añadir entradas a un registro
- API de usuario - Se crea un usuario de sólo lectura con el endpoint URI /settings/readOnlyUser - sólo se puede crear un usuario de sólo lectura
# ejemplo Ansible vacía el contenido del cubo especificado a través de la API REST:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
- name: "flush couchbase bucket {{ bucket }}" uri: url: https://{{ host }}:{{port}}/pools/default/buckets/ {{ bucket }}/controller/doFlush method: POST user: root password: "{{ passwd }}" delegate_to: localhost |
Resumen
En un mundo moderno, en el que los datos crecen más rápido que nunca y necesitamos cada vez más máquinas para poder conservar y mantener nuestros datos, la gestión centralizada y la automatización con orquestación son muy importantes. La coherencia, la reducción de la sobrecarga, la reducción de los errores humanos y la agilización de los procesos son buenas razones para empezar a utilizar la infraestructura como código junto con la automatización, la orquestación, las herramientas y las técnicas relacionadas con esto.
El clúster distribuido Couchbase es un candidato perfecto. Couchbase funciona bien con herramientas como Ansible y también proporciona una útil interfaz REST API. Los métodos de la API REST de Couchbase se pueden llamar desde playbooks de Ansible o scripts de Python.
La práctica DevOps aumenta la velocidad y la estabilidad de las implantaciones, al tiempo que reduce el tiempo de recuperación de fallos y los plazos de actualización del software.
En la segunda parte de este tutorial mostraré paso a paso cómo construir el rol de Ansible para un cluster de Couchbase usando métodos de la API REST de Couchbase y comandos de línea de comandos.