La partición de índices es una nueva característica disponible en Couchbase Server 5.5.
Echa un vistazo a la Anuncio de Couchbase Server 5.5 Developer Build y descargar el comunicado gratis ahora mismo.
En este post, voy a cubrir:
- Por qué conviene utilizar la partición de índices
- Un ejemplo de cómo hacerlo
- Eliminación de particiones
- Algunas advertencias con las que hay que tener cuidado
Partición de índices
Cuando desarrolles tu aplicación, puede que quieras aprovechar la facilidad de escalado de Couchbase Server para dar más recursos a la indexación. Con escalado multidimensional (MDS)Una opción es que pueda añadir varias máquinas de gama alta al clúster con capacidades de índice a medida que las necesite.
Para aprovechar los múltiples nodos con servicios de índice, tendría que crear réplicas de índices. Esto todavía es posible, y si esto está funcionando para usted, no va a desaparecer.
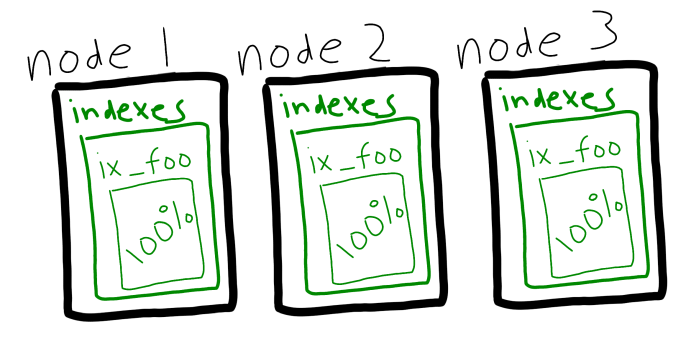
Couchbase Server 5.5 está introduciendo otra forma de repartir la carga del índice: el particionado del índice. En lugar de replicar un índice, ahora puedes dividir el índice entre los nodos con hashing.
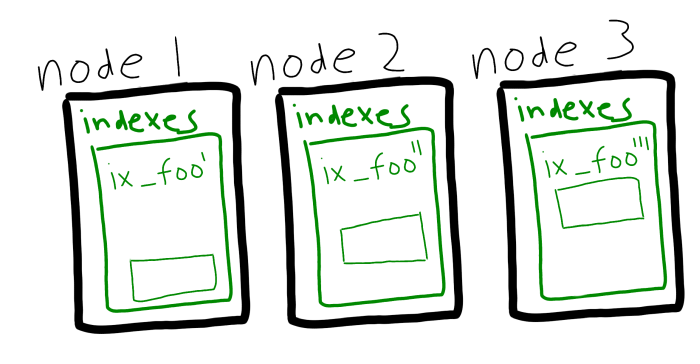
Además, puede utilizar la partición y las réplicas conjuntamente. Las réplicas de partición de índices se utilizarán automáticamente y sin interrupción si un nodo se cae.
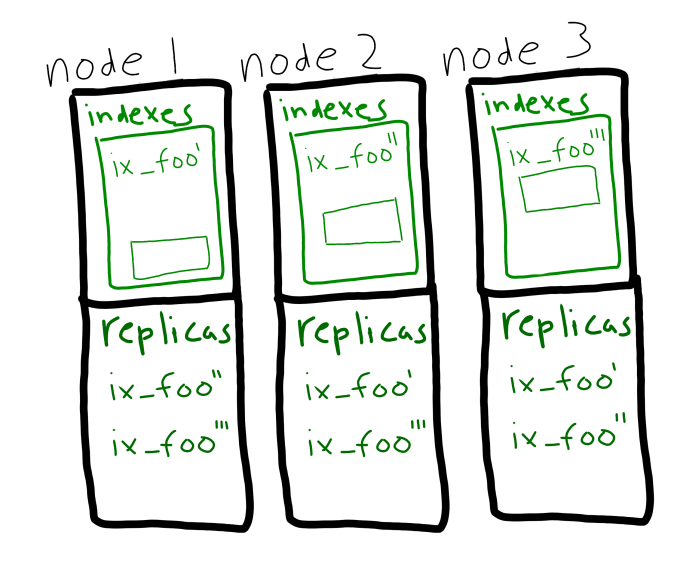
Las principales ventajas de la partición de índices:
- La carga de exploración de índices es ahora equilibrado entre todos los nodos índice. De este modo, el trabajo se distribuye de forma más uniforme y se mejora el rendimiento.
- Una consulta que utiliza la agregación (por ejemplo
SUM+GRUPO POR) puede ser funcionar en paralelo en cada partición.
Cómo utilizar la partición de índices
La sintaxis para crear una partición de índice es PARTICIÓN POR HASH(). Por ejemplo, si quisiera crear un índice compuesto en el bucket "viaje-muestra" para los campos aerolínea, vuelo, aeropuerto_de_origen y aeropuerto_de_destino:
|
1 |
CREATE INDEX ix_route ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(airline); |
Cuando crees este índice, se mostrará como "particionado" en la consola de Couchbase.

Eliminación de particiones
La eliminación de particiones es uno de los beneficios de usar particiones de índices. Se trata de una característica exclusiva de Couchbase en el mercado NoSQL.
Supongamos que tiene una partición en el campo aerolínea, como se indica más arriba. A continuación, escriba una consulta que utilice ese índice y especifique el valor de la línea aérea:
|
1 2 3 4 |
SELECT t.* FROM `travel-sample` t WHERE airline IN ["UA", "AA"] AND source_airport = "SFO" |
Entonces, el servicio de indexación sólo escaneará las particiones coincidentes ("UA" y "AA"). Esto conduce a una respuesta de consulta de rango más rápida, y la misma latencia que un índice no particionado, independientemente del tamaño del clúster. Más adelante hablaremos de ello.
Advertencias sobre la partición de índices
Puede que se haya dado cuenta de que se ha utilizado "compañía aérea" en el anterior CREAR ÍNDICE comando. Al utilizar la partición de índices, debe especificar uno (o más) campos para dar al hash que se utilizará para la partición. Este hash determinará cómo dividir el índice.
Lo más sencillo es utilizar la clave del documento en el hash:
|
1 2 |
CREATE INDEX ix_route2 ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(META().Id); |
Pero a diferencia del motor clave-valor de Couchbase, puedes usar los campos que quieras. Pero debes tener en cuenta que estos campos deben considerarse inmutable. Es decir, no deberías cambiar el valor de los campos. Así que, si tienes un campo con un valor que no suele cambiar (muchos usuarios de Couchbase crean un campo "tipo", por ejemplo), ese sería un buen candidato para particionar.
Si elige indexar en un campo "inmutable", tenga en cuenta que esto también puede provocar cierta desviación de la partición (utilizando META().Id minimizará la cantidad de sesgo). Si realiza la partición en el campo "tipo", donde 10% de los documentos tienen un tipo de "pedido" y 90% de los documentos tienen un tipo de "factura", es probable que la partición tenga un aspecto similar. El particionado de índices utiliza un algoritmo de optimización para equilibrar la RAM, la CPU y el tamaño de los datos durante el reequilibrado, pero el sesgo seguirá siendo una posibilidad.
Así que ¿por qué no usar META().Id para reducir el sesgo? Recuerde la sección anterior sobre eliminación de particiones. Si sus consultas siguen las mismas líneas que las particiones de su índice, entonces estará minimizando las operaciones de "dispersión+reunión" al tener que comprobar todas las particiones, y podrá reducir aún más la latencia.
Una advertencia más: la partición de índices es una función exclusiva de la edición Enterprise.
Resumen
La partición de índices te permite escalar de forma más fácil y automática tus capacidades de indexación. Si utilizas muchas consultas N1QL en tu proyecto, esto te resultará muy útil y te facilitará mucho el trabajo.
Si tiene alguna pregunta sobre la partición de índices o sobre cualquier otro tema relacionado con la indexación, consulte la sección Foros de Couchbase Server o el Foros N1QL si tiene preguntas sobre la creación de índices y consultas. Asegúrese de descargue la versión 5.5 de Couchbase Server hoy mismo y pruébalo. Nos encantará conocer tu opinión.
Puedes ponerte en contacto conmigo dejando un comentario a continuación o buscándome en Twitter @mgroves.