En nuevo lanzamiento de GeoCouch mejora mucho el tiempo de construcción del índice espacial (hasta 10 veces). Esto se debe a la utilización de un nuevo algoritmo de inserción masiva. El índice espacial (un Árbol R) se implementa como una estructura de datos de sólo adición (al igual que los árboles B de CouchDB) que se beneficia de la naturaleza de las inserciones masivas al permitir la adición de grandes bloques del índice de una sola vez.
Antigua aplicación
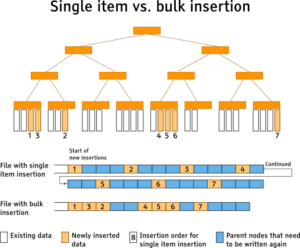
En versiones anteriores de GeoCouch, cada entrada de geometría se insertaba una a una. Esto llevaba a una enorme cantidad de pequeñas operaciones de disco, ya que cada adición se escribía en el índice. He aquí un resumen del antiguo algoritmo.
- Empezar en el nodo raíz
- Encontrar el primer hijo cuya caja delimitadora necesite la menor expansión.
- Recorrer el árbol R hasta alcanzar la hoja de destino
- Insertar el nuevo nodo en un nodo hoja
- Reescribe todos los nodos de la ruta desde el nodo recién insertado hasta el nodo raíz
Los primeros pasos son los básicos requeridos para una inserción en cualquier implementación de árbol R. El problema con este método es que cuando se utiliza una estructura de datos de sólo anexar, se requiere un alto número de escrituras ya que todos los nodos desde el nodo insertado hasta el nodo raíz necesitan ser reescritos y anexados al índice. Puedes encontrar más información sobre la naturaleza de las estructuras de datos "append-only" en mi artículo Tutorial de creación de un nuevo indexador
Aplicación actual
El índice espacial se implementa de forma similar a las vistas, el índice se actualiza cuando se realiza una petición para utilizarlo, en lugar de cuando se inserta un nuevo documento. El resultado es que una vez que se accede al índice, éste necesita ponerse al día con el documento insertado más recientemente. En cuanto cambia más de un documento, tiene más sentido procesarlo en bloque y reducir las modificaciones en disco del índice y mejorar el rendimiento global de la actualización.
Carga a granel e inserción a granel
Existe una diferencia entre la carga masiva y la inserción masiva. Por carga se entiende la creación de una nueva estructura de datos a partir de cero. Mientras que la inserción masiva significa que se insertan varios elementos nuevos en una estructura ya existente. La implementación de GeoCouch necesita ambas y se basa principalmente en dos documentos. Para la inserción Inserción masiva de árboles R mediante agrupación por semillas y para la carga a granel OMT: Algoritmo de carga masiva descendente que minimiza los solapamientos para el árbol R (con pequeñas modificaciones).
El algoritmo
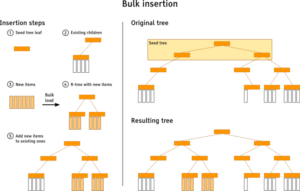
Para quienes no deseen leer la descripción completa, he aquí un breve resumen del algoritmo de inserción masiva. La idea básica es crear clústeres a partir de toda la actualización masiva que coincidan con la estructura de índices existente en ese momento (es decir, el índice árbol de destino). A continuación, esos conglomerados se cargan a granel en árboles R insertándolos textualmente en el árbol de destino.
Echemos un vistazo más de cerca a cada paso. El algoritmo comienza cargando en memoria los niveles superiores del árbol de destino (como máximo 3, de lo contrario el consumo de memoria está a punto de explotar), esto es lo que se denomina árbol semillero. A continuación, las hojas se utilizan para realizar la agrupación. Cada elemento de la inserción masiva se incorpora al árbol semilla con un algoritmo similar al algoritmo normal de inserción de árboles R. La diferencia es que los nuevos elementos no se escriben en disco, sino que se mantienen temporalmente en memoria mientras continúa el resto del proceso de inserción. La diferencia es que los nuevos elementos no se escriben en disco, sino que se mantienen temporalmente en memoria mientras continúa el resto del proceso de inserción masiva.
Una vez procesados todos los elementos, comienza el recorrido del árbol de semillas. Descendiendo en profundidad primera manera cuando se alcanza un nodo hoja. Todos los elementos almacenados temporalmente en el nodo actual se cargan a granel en un nuevo árbol R (el árbol árbol de origen) mediante el algoritmo OMT. Este árbol se añade a los nodos hijos originales de la hoja del árbol semilla. Pero hay un problema. Un árbol R siempre está equilibrado en altura, pero la altura del árbol de origen podría no caber si se añade tal cual. Básicamente hay tres casos:
- El árbol de origen encaja: El árbol puede insertarse tal cual
- El árbol fuente es demasiado pequeño: se crea un nuevo árbol semilla. Su nodo raíz es el nodo hoja del árbol semillero actual. Proceder recursivamente.
- El árbol fuente es demasiado grande: utilice los nodos hijos en lugar del nodo raíz del árbol fuente (recursivamente, baje hasta que la altura coincida).
El nodo raíz del árbol de origen puede cubrir la mayor parte del área del nodo en el que se inserta, por lo que se realiza un reagrupamiento para mejorar el rendimiento de la consulta. Los hijos de todos los nodos que se cruzan con el nodo del árbol de origen y los hijos del árbol de origen se reorganizan para minimizar el área que cubren (se utiliza el algoritmo OMT). Una vez finalizado este proceso, los nodos reagrupados se escriben finalmente en el disco.
Los nodos padre se escriben en disco cada vez que se completa un subárbol. El resultado es que el proceso de actualización masiva del índice ahorra muchas escrituras físicas en disco en comparación con la estrategia tradicional de inserción de un único elemento, en la que todos los nodos padre hasta la raíz se reescriben en cada inserción.
Retos de la inserción masiva
Aunque los algoritmos básicos son sencillos, algunas personas podrían preguntarse por qué parte del código necesario para lograrlo es tan complejo. El mayor reto es mantener la altura del árbol R resultante equilibrada y el número de hijos por nodo por debajo del número máximo. Cuando se inserta en masa, puede haber inserciones que provoquen un desbordamiento (y, por tanto, divisiones) y esto debe llevarse a cabo recursivamente hasta la parte superior del árbol.
Otro reto es rastrear en memoria la altura actual del árbol de destino, la posición actual dentro del árbol de destino/semilla y la altura prevista del árbol de origen que se insertará. Esto debe hacerse de forma eficiente para evitar consumir demasiada memoria.
Mejoras futuras
La inserción masiva actual mejora mucho el rendimiento y el tamaño de los archivos en comparación con la inserción tradicional de un único elemento, gracias a una combinación de reconstrucción y equilibrado eficientes del árbol, y a la reducción de las escrituras físicas en disco. La implementación a menudo necesita buscar nodos para obtener su cuadro delimitador, sin necesidad de solicitar otras cosas (como sus hijos). Los cambios en la estructura de datos actual (que son los primeros fragmentos de código que se escribieron para GeoCouch) podrían reducir aún más las búsquedas.
Hola, me pregunto si la API del cliente tendrá el método setBulk o el servidor Couchbase ejecutará la operación masiva.
Gracias de antemano.