Prólogo
Se espera que las aplicaciones empresariales modernas funcionen 24 horas al día, 7 días a la semana, incluso durante el despliegue previsto de nuevas funciones y la aplicación periódica de parches en el sistema operativo o la aplicación. Para conseguirlo se necesitan herramientas y tecnologías que garanticen la velocidad de desarrollo, la estabilidad de la infraestructura y la capacidad de ampliación.
Las herramientas de orquestación de contenedores como Kubernetes están revolucionando la forma en que se desarrollan y despliegan las aplicaciones hoy en día al abstraer las máquinas físicas que gestiona. Con Kubernetes, puede describir la cantidad de memoria y potencia de cálculo que desee y disponer de ella sin preocuparse de la infraestructura subyacente.
Los pods (unidad de recurso informático) y los contenedores (donde se ejecutan las aplicaciones) en un entorno Kubernetes pueden autorrepararse en caso de cualquier tipo de fallo. Son, en esencia, efímeros. Esto funciona muy bien cuando se tiene un microservicio sin estado, pero las aplicaciones que requieren que su estado se mantenga, por ejemplo, los sistemas de gestión de bases de datos como Couchbase, necesitan poder externalizar el almacenamiento de la gestión del ciclo de vida de Pods y Contenedores para que los datos se puedan recuperar rápidamente simplemente volviendo a montar los volúmenes de almacenamiento en un Pod recién elegido.
Esto es lo que Volúmenes persistentes permite en despliegues basados en Kubernetes. Operador autónomo de Couchbase es uno de los primeros en adoptar esta tecnología para que la recuperación ante cualquier fallo de la infraestructura sea fluida y, lo que es más importante, más rápida.
En este artículo veremos paso a paso cómo se puede implementar un clúster de Couchbase en Amazon Elastic Container Service para Kubernetes (Amazon EKS): 1) utilizando varios grupos de servidores Couchbase que se pueden asignar a una zona de disponibilidad independiente para una alta disponibilidad 2) aprovechando los volúmenes persistentes para una rápida recuperación en caso de fallo de la infraestructura.
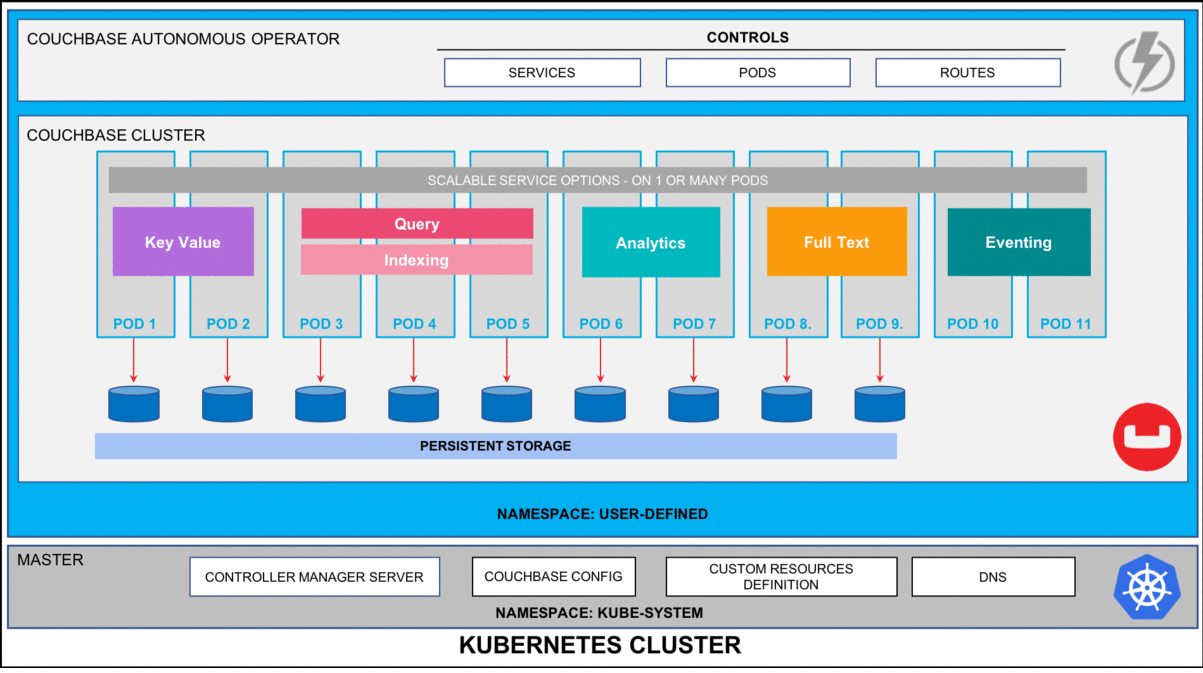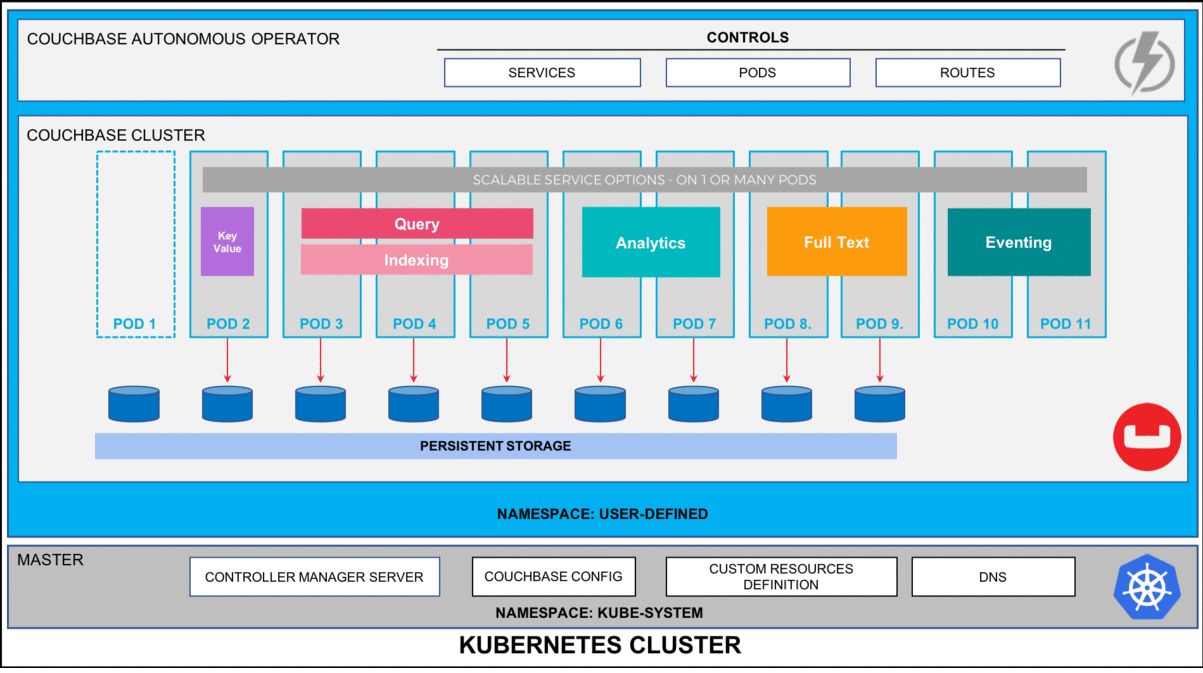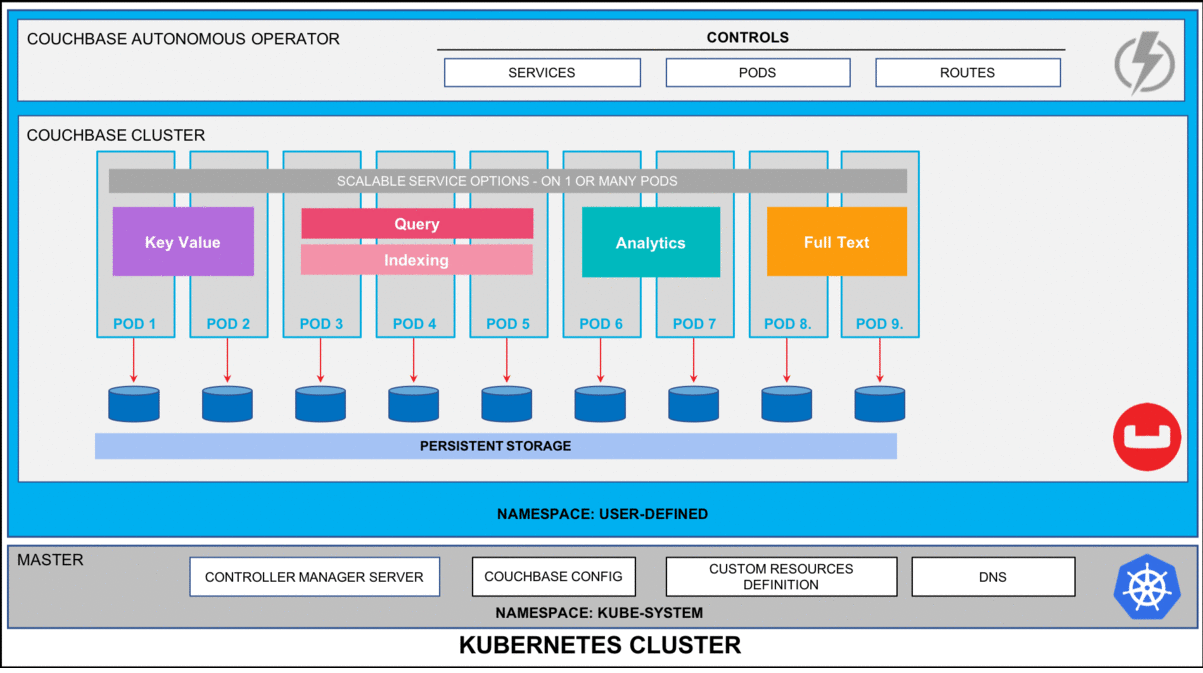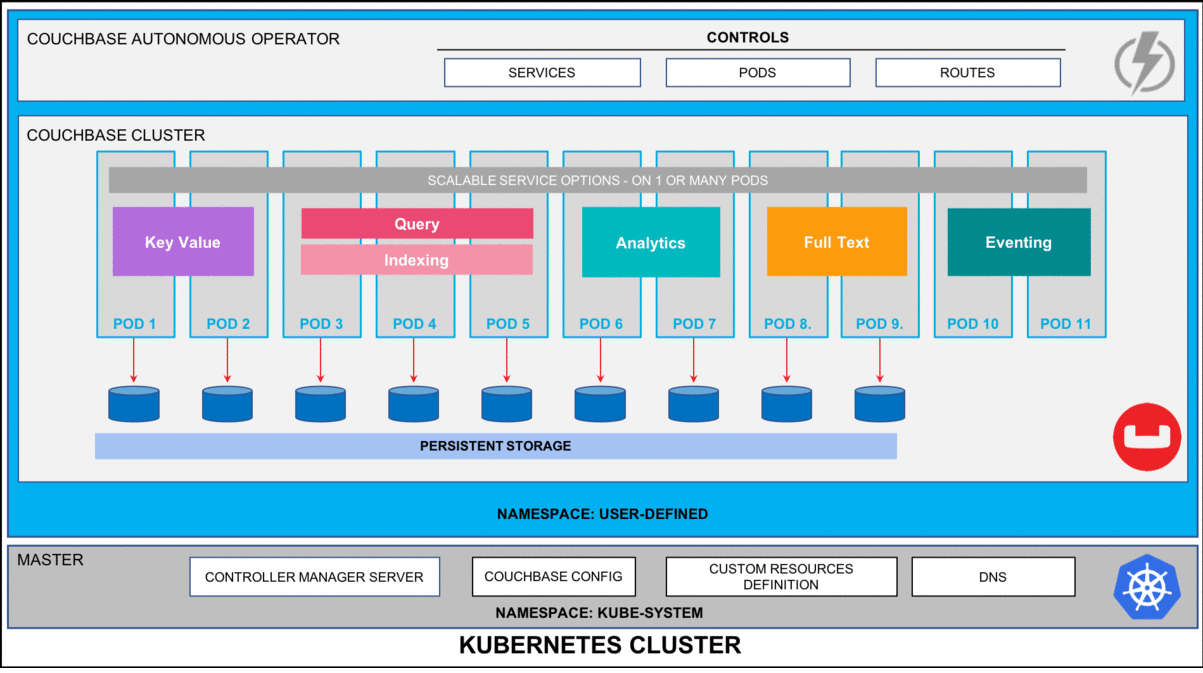
Figura 1: Couchbase Autonomous Operator para Kubernetes automonitoriza y autorrepara la plataforma de base de datos Couchbase.
1. Requisitos previos
Hay tres requisitos previos de alto nivel antes de comenzar el despliegue de Couchbase Autonomous Operator en EKS:
- Usted tiene kubectl instalado en nuestra máquina local.
- Última CLI DE AWS está configurado para que podamos establecer de forma segura un canal entre nuestra máquina local y el plano de control de Kubernetes que se ejecuta en AWS.
- Amazon Grupo EKS se despliega con al menos tres nodos trabajadores en tres zonas de disponibilidad separadas para que más tarde podamos desplegar y gestionar nuestro cluster de Couchbase. Usaremos us-east-1 como región y us-east-1a/1b/1c como tres zonas de disponibilidad, pero puedes desplegar en cualquier región/zona haciendo pequeños cambios en los archivos YAML de los ejemplos de abajo.
2. Despliegue de Couchbase Autonomous Operator
Antes de comenzar con la configuración del Operador Couchbase, ejecute el comando 'kubectl get nodes' desde la máquina local para confirmar que el clúster EKS está en funcionamiento.
|
1 2 3 4 5 6 |
$ kubectl consiga nodos NOMBRE ESTADO ROLES EDAD VERSIÓN ip-192-168-106-132.ec2.interno Listo <ninguno> 110m v1.11.9 ip-192-168-153-241.ec2.interno Listo <ninguno> 110m v1.11.9 ip-192-168-218-112.ec2.interno Listo <ninguno> 110m v1.11.9 |
Después de haber probado que podemos conectarnos al plano de control de Kubernetes que se ejecuta en el clúster de Amazon EKS desde nuestra máquina local, ahora podemos comenzar con los pasos necesarios para implementar Couchbase Autonomous Operator, que es la tecnología que permite que el clúster de Couchbase Server sea administrado por Kubernetes.
2.1. Descargar el paquete Operator
Empecemos descargando la última versión de Operador autónomo de Couchbase y descomprímelo en la máquina local. Cambia el directorio a la carpeta del operador para que podamos encontrar los archivos YAML que necesitamos para desplegar el operador Couchbase:
|
1 2 3 4 5 6 7 8 |
$ cd couchbase-autónomo-operador-kubernetes_1.2.0-981_linux-x86_64 $ ls Licencia.txt couchbase-cli-crear-usuario.yaml operador-papel-vinculante.yaml secreto.yaml LÉAME.txt couchbase-grupo.yaml operador-papel.yaml admisión.yaml crd.yaml operador-servicio-cuenta.yaml papelera operador-despliegue.yaml pelea de almohadas-datos-cargador.yaml |
2.2. Crear un espacio de nombres
Crea un espacio de nombres que permita que los recursos del cluster estén bien separados entre múltiples usuarios. Para ello utilizaremos un espacio de nombres único llamado emart para nuestro despliegue y más tarde utilizaremos este espacio de nombres para desplegar Couchbase Cluster.
En su directorio de trabajo, cree un archivo namespace.yaml con este contenido y guardarlo en el propio directorio del operador Couchbase:
|
1 2 3 4 |
apiVersion: v1 amable: Espacio de nombres metadatos: nombre: emart |
Después de guardar la configuración del espacio de nombres en un archivo, ejecute kubectl cmd para crearlo:
|
1 |
$ kubectl crear -f espacio de nombres.yaml |
Ejecute el comando get namespace para confirmar que se ha creado correctamente:
|
1 2 3 4 5 6 7 |
$ kubectl consiga espacios de nombres salida: NOMBRE ESTADO EDAD por defecto Activo 1h emart Activo 12s |
A partir de ahora utilizaremos emart como espacio de nombres para todo el aprovisionamiento de recursos.
2.3. Añadir certificado TLS
Crear secreto para Operador Couchbase y servidores con un certificado dado. Ver cómo crear un certificado personalizado si no tiene.
|
1 2 3 |
$ kubectl crear secreto genérico couchbase-servidor-tls --de-archivo cadena.pem --de-archivo pkey.clave --espacio de nombres emart secreto/couchbase-servidor-tls creado |
|
1 2 3 |
$ kubectl crear secreto genérico couchbase-operador-tls --de-archivo pki/ca.crt --espacio de nombres emart secreto/couchbase-operador-tls creado |
2.4. Instalación del controlador de admisión
El controlador de admisión es un componente necesario de Couchbase Autonomous Operator y debe instalarse por separado. El propósito principal del controlador de admisión es validar los cambios de configuración del cluster de Couchbase antes de que el Operador actúe sobre ellos, protegiendo así su despliegue de Couchbase (y al Operador) de cualquier daño accidental que pudiera surgir de una configuración inválida. Para más detalles sobre la arquitectura, visite la página de documentación de Controlador de admisiones
Siga los siguientes pasos para desplegar el controlador de admisión:
- Desde el directorio del operador Couchbase ejecute el siguiente comando para crear el controlador de admisión:
|
1 |
$ kubectl crear -f admisión.yaml --espacio de nombres emart |
- Confirme que el controlador de admisión se ha desplegado correctamente:
|
1 2 3 4 |
$ kubectl consiga despliegues --espacio de nombres emart NOMBRE DESEADO ACTUAL UP-A-FECHA DISPONIBLE EDAD couchbase-operador-admisión 1 1 1 1 1m |
2.5. Instalar CRD
El primer paso para instalar el Operador es instalar la definición de recurso personalizada (CRD) que describe el tipo de recurso CouchbaseCluster. Esto se puede lograr con el siguiente comando:
|
1 |
kubectl crear -f crd.yaml --espacio de nombres emart |
2.6. Crear un rol de operador
A continuación, crearemos un función de clúster que permite al Operador acceder a los recursos que necesita para funcionar. Dado que el Operador gestionará muchos espacios de nombreses mejor crear primero una función de clúster, ya que puede asignar esa función a un clúster. cuenta de servicio en cualquier espacio de nombres.
Para crear el rol de cluster para el Operador, ejecute el siguiente comando:
|
1 |
$ kubectl crear -f operador-papel.yaml --espacio de nombres emart |
Esta función de clúster sólo debe crearse una vez.
2.7. Crear una cuenta de servicio
Una vez creado el rol de cluster, es necesario crear una cuenta de servicio en el espacio de nombres donde se está instalando el Operator. Para crear la cuenta de servicio:
|
1 |
$ kubectl crear cuenta de servicio couchbase-operador --espacio de nombres emart |
Ahora asigna el rol de operador a la cuenta de servicio:
|
1 2 3 4 5 6 |
$ kubectl crear vinculación de funciones couchbase-operador --papel couchbase-operador \ --cuenta de servicio emart:couchbase-operador --espacio de nombres emart salida: clusterrolebinding.rbac.autorización.k8s.io/couchbase-operador creado |
Ahora, antes de continuar, asegurémonos de que todos los roles y cuentas de servicio se han creado bajo el espacio de nombres emart. Para ello, ejecute estas tres comprobaciones y asegúrese de que cada una de ellas devuelve algo:
|
1 2 3 |
Kubectl consiga papeles -n emart Kubectl consiga enlaces de roles -n emart Kubectl consiga sa -n emart |
2.8. Despliegue de Couchbase Operator
Ahora tenemos todos los roles y privilegios para desplegar nuestro operador. Desplegar el operador es tan simple como ejecutar el archivo operator.yaml desde el directorio Couchbase Autonomous Operator.
|
1 2 3 4 5 |
$ kubectl crear -f operador-despliegue.yaml --espacio de nombres emart salida: despliegue.aplicaciones/couchbase-operador creado |
El comando anterior descargará la imagen Docker de Operator (especificada en el archivo operator.yaml) y crea un despliegue, que gestiona una única instancia de Operator. El Operator utiliza un despliegue para poder reiniciarse si el pod en el que se está ejecutando muere.
Kubernetes tardaría menos de un minuto en desplegar el Operador y éste estaría listo para ejecutarse.
a) Verificar el estado de la implantación
Puede utilizar el siguiente comando para comprobar el estado de la implantación:
|
1 |
$ kubectl consiga despliegues --espacio de nombres emart |
Si ejecuta este comando inmediatamente después de desplegar el Operador, el resultado será algo parecido a lo siguiente:
|
1 2 |
NOMBRE DESEADO ACTUAL UP-A-FECHA DISPONIBLE EDAD couchbase-operador 1 1 1 0 10s |
Nota: La salida anterior significa que su operador Couchbase está desplegado y puede seguir adelante con el despliegue del clúster Couchbase a continuación.
b) Verificar el estado del operador
Puede utilizar el siguiente comando para verificar que el Operador se ha iniciado correctamente:
|
1 |
$ kubectl consiga vainas -l aplicación=couchbase-operador --espacio de nombres emart |
Si el Operador está en funcionamiento, el comando devuelve una salida en la que el campo LISTO muestra 1/1, como por ejemplo:
|
1 2 |
NOMBRE LISTO ESTADO RESTARTS EDAD couchbase-operador-8c554cbc7-6vqgf 1/1 Ejecutar 0 57s |
También puedes comprobar los registros para confirmar que el Operador está en funcionamiento. Busque el mensaje CRD inicializado, escuchando eventos... module=controller.
|
1 2 3 4 5 6 7 8 9 10 11 |
$ kubectl Registros couchbase-operador-8c554cbc7-6vqgf --espacio de nombres emart --cola 20 salida: tiempo="2019-05-30T23:00:58Z" nivel=información msg="couchbase-operator v1.2.0 (release)" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Obtención del bloqueo de recursos" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Iniciando grabadora de eventos" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Intento de ser elegido líder de los operadores de sofá" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Soy el líder, intente iniciar el operador" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Creación del controlador couchbase-operator" módulo=principal tiempo="2019-05-30T23:00:58Z" nivel=información msg="Evento(v1.ObjectReference{Kind:\"Endpoints\", Namespace:\"emart\", Name:\"couchbase-operator\", UID:\"c96ae600-832e-11e9-9cec-0e104d8254ae\", APIVersion:\"v1\", ResourceVersion:\"950158\", FieldPath:\"\"}): type: 'Normal' reason: 'LeaderElection' couchbase-operator-6cbc476d4d-2kps4 became leader" módulo=grabador_de_eventos |
3. Despliegue del cluster Couchbase usando volúmenes persistentes
En un entorno de producción donde el rendimiento y SLA del sistema es lo más importante, siempre debemos planificar el despliegue del clúster Couchbase utilizando volúmenes persistentes, ya que ayuda en:
- Recuperación de datos: Los Volúmenes Persistentes permiten recuperar los datos asociados a los Pods en caso de que un Pod se cierre. Esto ayuda a prevenir la pérdida de datos y evitar la lenta creación de índices cuando se utilizan los servicios de datos o índices.
- Reubicación de la cápsula: Kubernetes puede decidir desalojar pods que alcancen umbrales de recursos como límites de CPU y memoria. Los pods respaldados con volúmenes persistentes pueden cerrarse y reiniciarse en nodos diferentes sin que se produzca ningún tiempo de inactividad o pérdida de datos.
- Aprovisionamiento dinámico: El Operador creará Volúmenes Persistentes bajo demanda a medida que su clúster escale, aliviando la necesidad de pre-aprovisionar el almacenamiento de su clúster antes del despliegue.
- Integración en la nube: Kubernetes se integra con los aprovisionadores de almacenamiento nativos disponibles en los principales proveedores de nube, como AWS y GCE.
En la siguiente sección, veremos cómo definir clases de almacenamiento en diferentes zonas de disponibilidad y crear una plantilla de reclamación de volumen persistente, que se utilizará en couchbase-cluster-con-pv-1.2.yaml archivo.
3.1. Crear secreto para la consola de administración de Couchbase
Lo primero que tenemos que hacer es crear una credencial secreta que será utilizada por la consola web administrativa durante el inicio de sesión. Para mayor comodidad, se proporciona un secreto de muestra en el paquete Operator. Cuando lo empuja a su clúster Kubernetes, el secreto establece el nombre de usuario en Administrador y la contraseña en contraseña.
Para insertar el secreto en su clúster Kubernetes, ejecute el siguiente comando:
|
1 2 3 4 5 |
$ kubectl crear -f secreto.yaml --espacio de nombres emart Salida: Secreto/cb-ejemplo-auth creado |
3.2 Crear una clase de almacenamiento AWS para el clúster EKS
Ahora, para poder utilizar PersistentVolume para los servicios de Couchbase (datos, índice, búsqueda, etc.), necesitamos crear primero Storage Classes (SC) en cada una de las Availability Zones (AZ). Empecemos por comprobar qué clases de almacenamiento existen en nuestro entorno.
Usemos el comando kubectl para averiguarlo:
|
1 2 3 4 5 |
$ kubectl consiga clase de almacenamiento Salida: gp2 (por defecto) kubernetes.io/aws-ebs 12m |
El resultado anterior significa que sólo tenemos la clase de almacenamiento gp2 por defecto y necesitamos crear clases de almacenamiento separadas en todos los AZs donde estamos planeando desplegar nuestro cluster Couchbase.
1) Cree un archivo de manifiesto de clase de almacenamiento de AWS. El siguiente ejemplo define la estructura de la clase de almacenamiento (sc-gp2.yaml), que utiliza el tipo de volumen Amazon EBS gp2 (también conocido como unidad SSD de propósito general). Este almacenamiento lo utilizaremos más adelante en nuestro VolumeClaimTemplate.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Para más información acerca de el opciones disponible para AWS almacenamiento clases, véase [AWS](https://kubernetes.io/docs/concepts/storage/storage-classes/#aws) en la documentación de Kubernetes. ``` apiVersion: almacenamiento.k8s.io/v1 amable: StorageClass metadatos: etiquetas: k8s-complemento: almacenamiento-aws.complementos.k8s.io nombre: gp2-multi-zona parámetros: tipo: gp2 proveedor: kubernetes.io/aws-ebs reclaimPolicy: Borrar volumeBindingMode: WaitForFirstConsumer ``` Por encima de nosotros usado ```reclaimPolicy``` a Borrar que dice K8 a borrar el volúmenes de suprimido Vainas pero usted puede cambiar it a _Retain_ dependiendo en su necesita o si para solución de problemas propósito usted sería como a guarda el volúmenes de suprimido vainas. |
2) Ahora utilizaremos el comando kubectl para crear físicamente una clase de almacenamiento a partir de los archivos de manifiesto que definimos anteriormente.
|
1 2 3 4 5 6 7 |
``` $ kubectl crear -f sc-gp2.yaml Salida: clase de almacenamiento.almacenamiento.k8s.io/gp2-multi-zona creado ``` |
3) Verificar la nueva clase de almacenamiento
Una vez que hayas creado todas las clases de almacenamiento, puedes verificarlas mediante el comando kubectl:
|
1 2 3 4 5 6 7 8 9 |
``` $ kubectl consiga sc --espacio de nombres emart salida: NOMBRE PROVISIONADOR EDAD gp2 (por defecto) kubernetes.io/aws-ebs 16h gp2-multi-zona kubernetes.io/aws-ebs 96s ``` |
3.3. Conocimiento de los grupos de servidores
Server Group Awareness proporciona una mayor disponibilidad, ya que protege un clúster de fallos de infraestructura a gran escala, mediante la definición de grupos.
Los grupos deben definirse de acuerdo con la distribución física de los nodos del clúster. Por ejemplo, un grupo sólo debe incluir los nodos que se encuentran en un único rack de servidores o, en el caso de despliegues en la nube, en una única zona de disponibilidad. De este modo, si el rack de servidores o la zona de disponibilidad dejan de estar disponibles debido a un fallo eléctrico o de red, la Conmutación por error de grupo, si está activada, permite seguir accediendo a los datos afectados.
Por lo tanto, colocamos los servidores Couchbase en spec.servers.serverGroupsque se asignarán a nodos EKS físicamente separados que se ejecutan en tres AZ diferentes (us-east-1a/b/c):
|
1 2 3 4 5 6 7 8 |
spec: servidores: - nombre: datos-este-1a talla: 1 servicios: - datos grupos de servidores: - us-este-1a |
3.4. Añadir clase de almacenamiento a la plantilla de reclamación de volumen persistente
Con los grupos de servidores definidos, y las Storage Classes disponibles en las tres AZs, ahora vamos a crear volúmenes de almacenamiento dinámico y montarlos en cada uno de los servidores Couchbase que requieran datos persistentes. Para ello, primero definiremos la Plantilla de Reclamación de Volumen Persistente en nuestro couchbase-cluster.yaml (que puede encontrarse en la carpeta del operador).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Espec: volumeClaimTemplates: - metadatos: nombre: pvc-por defecto spec: storageClassName: gp2-multi-zona recursos: solicita: almacenamiento: 1Gi - metadatos: nombre: pvc-datos spec: storageClassName: gp2-multi-zona recursos: solicita: almacenamiento: 5Gi - metadatos: nombre: pvc-índice spec: storageClassName: gp2-multi-zona recursos: solicita: almacenamiento: 3Gi |
Una vez añadida la plantilla de reclamación, el paso final es emparejar la plantilla de reclamación de volumen con los grupos de servidores correspondientes en cada una de las zonas. Por ejemplo, los Pods del grupo de servidores data-east-1a deben utilizar la plantilla volumeClaimTemplate denominada pvc-datos para almacenar datos y pvc-default para los archivos binarios y de registro de Couchbase.
Por ejemplo, a continuación se muestra el emparejamiento de un Grupo de Servidores y su VolumeClaimTemplate asociado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
spec: servidores: - nombre: datos-este-1a talla: 1 servicios: - datos grupos de servidores: - us-este-1a vaina: volumeMounts: por defecto: pvc-por defecto datos: pvc-datos - nombre: datos-este-1b talla: 1 servicios: - datos grupos de servidores: - us-este-1b vaina: volumeMounts: por defecto: pvc-por defecto datos: pvc-datos - nombre: datos-este-1c talla: 1 servicios: - datos grupos de servidores: - us-este-1c vaina: volumeMounts: por defecto: pvc-por defecto datos: pvc-datos |
Observa que hemos creado tres grupos de servidores de datos separados (data-east-1a/-1b/-1c), cada uno ubicado en su propia AZ, utilizando plantillas de reclamación de volumen persistente de esa AZ. Ahora, utilizando el mismo concepto, añadiremos el índice y los servicios de consulta y los asignaremos en grupos de servidores separados para que puedan escalar independientemente de los nodos de datos.
3.5. Despliegue del clúster Couchbase
La especificación completa para desplegar el clúster Couchbase en 3 zonas diferentes utilizando volúmenes persistentes puede verse en el documento couchbase-cluster-con-pv-1.2.yaml . Este archivo, junto con otros archivos yaml de ejemplo utilizados en este artículo, puede descargarse de este repositorio git.
Por favor, abra el archivo yaml y observe que estamos desplegando el servicio de datos en tres AZs pero desplegando el servicio de índice y consulta en dos AZs solamente. Puede cambiar la configuración para satisfacer sus necesidades de producción.
Ahora usa kubectl para desplegar el cluster.
|
1 |
$ kubectl crear -f couchbase-grupo-con-pv-1.2.yaml --guardar-config --espacio de nombres emart |
Esto iniciará el despliegue del cluster Couchbase y si todo va bien tendremos cinco pods del cluster Couchbase alojando los servicios según el fichero de configuración anterior. Para comprobar el progreso ejecute este comando, que observará (argumento -w) el progreso de la creación de pods:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ kubectl consiga vainas --espacio de nombres emart -w salida: NOMBRE LISTO ESTADO RESTARTS EDAD cb_eks_demo-0000 1/1 Ejecutar 0 2m cb_eks_demo-0001 1/1 Ejecutar 0 1m cb_eks_demo-0002 1/1 Ejecutar 0 1m cb_eks_demo-0003 1/1 Ejecutar 0 37s cb_eks_demo-0004 1/1 ContenedorCrear 0 1s couchbase-operador-8c554cbc7-n8rhg 1/1 Ejecutar 0 19h |
Si por alguna razón se produce una excepción, puede encontrar los detalles de la excepción en el archivo de registro couchbase-operator. Para ver las últimas 20 líneas del registro, copie el nombre de su pod de operador y ejecute el siguiente comando sustituyendo el nombre del operador por el nombre de su entorno.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ kubectl Registros couchbase-operador-8c554cbc7-98dkl --espacio de nombres emart --cola 20 salida: tiempo="2019-02-13T18:32:26Z" nivel=información msg="El cluster no existe por lo que el operador está intentando crearlo" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:26Z" nivel=información msg="Creación de servicio headless para nodos de datos" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:26Z" nivel=información msg="Creación del servicio NodePort UI (cb-eks-demo-ui) para nodos de datos" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:26Z" nivel=información msg="Creando un pod (cb-eks-demo-0000) ejecutando Couchbase enterprise-5.5.3" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:34Z" nivel=advertencia msg="nodo init: falló con error [Post http://cb-eks-demo-0000.cb-eks-demo.emart.svc:8091/node/controller/rename: dial tcp: lookup cb-eks-demo-0000.cb-eks-demo.emart.svc on 10.100.0.10:53: no such host] ...reintentando" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:39Z" nivel=información msg="Operador añadido miembro (cb-eks-demo-0000) para gestionar" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:39Z" nivel=información msg="Inicializando el primer nodo del cluster" grupo-nombre=cb-eks-demo módulo=grupo tiempo="2019-02-13T18:32:39Z" nivel=información msg="empieza a correr..." grupo-nombre=cb-eks-demo módulo=grupo |
Cuando todos los pods estén listos entonces puedes hacer un port forward a uno de los pods del cluster Couchbase para que podamos ver el estado del cluster desde la consola web. Ejecute este comando para hacer el port forward.
|
1 |
$ kubectl puerto-adelante cb-eks-demo-0000 18091:18091 --espacio de nombres emart |
En este punto, puede abrir un navegador y escriba https://localhost:18091 que traerá Couchbase web-consola desde donde se puede controlar las estadísticas del servidor, crear cubos, ejecutar consultas desde un solo lugar.
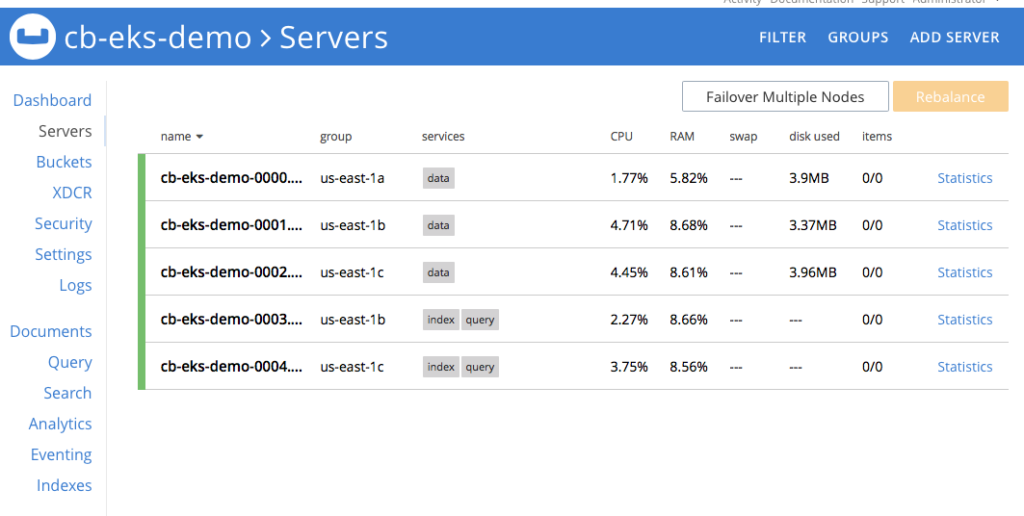
Figura 2: Cluster Couchbase de cinco nodos utilizando volúmenes persistentes.
Nota: Visite nuestro repositorio git para encontrar la última versión del taller mencionado.
Conclusión
Couchbase Autonomous Operator hace que la gestión y orquestación de Couchbase Cluster sea fluida en la plataforma Kubernetes. Lo que hace que este operador sea único es su capacidad para utilizar fácilmente las clases de almacenamiento ofrecidas por diferentes proveedores de la nube (AWS, Azure, GCP, RedHat OpenShift, etc.) para crear volúmenes persistentes, que luego son utilizados por el clúster de base de datos Couchbase para almacenar persistentemente los datos. En caso de fallo de un pod o contenedor, Kubernetes reinstala un nuevo pod/contenedor automáticamente y simplemente vuelve a montar los volúmenes persistentes, haciendo que la recuperación sea rápida. También ayuda a mantener el SLA del sistema durante la recuperación de fallos de infraestructura, ya que solo es necesaria la recuperación delta frente a la recuperación completa si no se utilizan volúmenes persistentes.
En este artículo explicamos paso a paso cómo configurar volúmenes persistentes en Amazon EKS, pero los mismos pasos también son aplicables si utilizas cualquier otro entorno Kubernetes de código abierto (AKS, GKE, etc.). Esperamos que pruebes Couchbase Autonomous Operator y nos cuentes tu experiencia.