Couchbase Lanzamiento de Sync Gateway 2.8 ha anunciado la compatibilidad con la sincronización de datos de nivel empresarial entre la nube y el perímetro. La nueva tecnología de replicación inter-Sync Gateway permite una sincronización escalable y segura de nivel empresarial entre la nube y los centros de datos periféricos en un entorno de nube distribuida para satisfacer las demandas de las aplicaciones Edge Computing.
En este post, ofrecemos una visión general de la función con algunos ejemplos sobre cómo configurar su despliegue. Para obtener más información, consulte la documentación páginas.
En primer lugar, algunos casos de uso...
Casos prácticos
Los despliegues distribuidos en la nube, en los que el almacenamiento y el procesamiento de datos se distribuyen y gestionan más cerca de las aplicaciones, son cada vez más importantes, ya que las aplicaciones exigen una alta disponibilidad garantizada, respuestas en tiempo real, cumplimiento de la privacidad de los datos y restricciones normativas, y manejan volúmenes masivos de datos. Este paradigma informático se conoce como "Edge Computing". Puede obtener más información al respecto en este blog sobre "Arquitectura de soluciones Edge Computing con Couchbase".
He aquí algunos ejemplos de aplicaciones que se benefician de este tipo de arquitectura distribuida en la nube.
- Venta al por menor :
Los grandes comercios seguirán prestando servicio a sus clientes incluso en caso de cortes de Internet mediante servidores locales. Tiempo de inactividad no sólo es perjudicial para la experiencia del cliente, sino que también puede tener un impacto duradero en la reputación. En este caso, garantizar la alta disponibilidad de las aplicaciones y la capacidad de recuperación son factores clave. - Viajar :
Los pasajeros de cruceros pueden aprovechar todos los servicios de a bordo incluso cuando los barcos estén desconectados de Internet durante días o meses. En este caso, el centro de datos del crucero seguirá prestando servicio a los pasajeros en viaje. Este es otro ejemplo en el que la alta disponibilidad garantizada de las aplicaciones y la resistencia son factores clave. - Hostelería :
Los hoteles pueden asegurarse de que los huéspedes se registran incluso cuando hay un corte de Internet. El sistema de gestión de la propiedad (PMS) del hotel garantizará que la experiencia de los huéspedes no se vea comprometida. Este es otro ejemplo en el que la alta disponibilidad garantizada de las aplicaciones y la resiliencia son factores clave. - Sanidad :
Los sistemas de monitorización de pacientes en hospitales pueden procesar localmente los datos de los pacientes y tomar medidas correctivas inmediatas. En este caso, el procesamiento de datos en tiempo real y la privacidad de los datos son factores clave. - IoT :
Las aplicaciones IoT son un motor clave de las arquitecturas Edge Computing. Las aplicaciones de este sector generan enormes volúmenes de datos que deben analizarse en tiempo real. Transferir todos esos datos a los servidores backend impone una gran sobrecarga a la red y a los servidores. Además, muchos de los datos suelen ser de naturaleza efímera y no tiene mucho sentido tener que transferirlos a servidores remotos sólo para ser procesados y descartados. Como ejemplo específico en el espacio IIoT, las fábricas pueden supervisar, recopilar y analizar datos de sensores de equipos a nivel local para el mantenimiento preventivo. Sólo los datos agregados se envían al centro de datos en la nube. El procesamiento de datos en tiempo real y el ahorro de costes por la reducción del uso de ancho de banda son los principales impulsores en este caso.
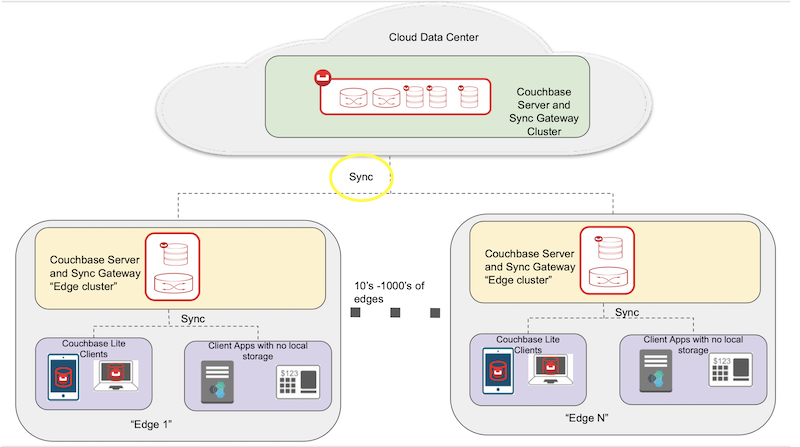
Implantación típica de la nube en la periferia
A continuación se muestra un despliegue típico de una arquitectura de nube distribuida utilizando Couchbase.
¿Cómo encaja Couchbase? Tienes Couchbase Server en los centros de datos remotos de la nube y es responsable de almacenar y procesar los datos en todos los centros de datos de borde. Luego tienes una huella más pequeña de Couchbase Server en cada uno de los centros de datos de borde. El tamaño de los servidores en los centros de datos de borde será significativamente menor que el de los centros de datos de nube, ya que sirve a una población más pequeña de clientes en el borde. Los datos locales del borde son procesados por el clúster de servidores Couchbase on-prem.
Pero, ¿qué ocurre con el movimiento de datos? En otras palabras, ¿cómo se mantienen sincronizados los datos entre la nube y el perímetro? Aquí es donde entra en juego la replicación entre Sync Gateways. Para ello, se despliega Sync Gateway en la nube y en los centros de datos periféricos, que se encarga de replicar los datos. Además, hay que tener en cuenta que la sincronización se realiza a través de Internet, que no es de fiar. Por tanto, hay que asegurarse de que los datos estén cifrados y de que existan estrictos controles de seguridad para garantizar el acceso autorizado a los datos. Además, se pueden desplegar diferentes políticas de control de acceso en la nube y en el perímetro, y garantizar que un perímetro comprometido no afecte a la nube ni a los demás centros de datos periféricos.
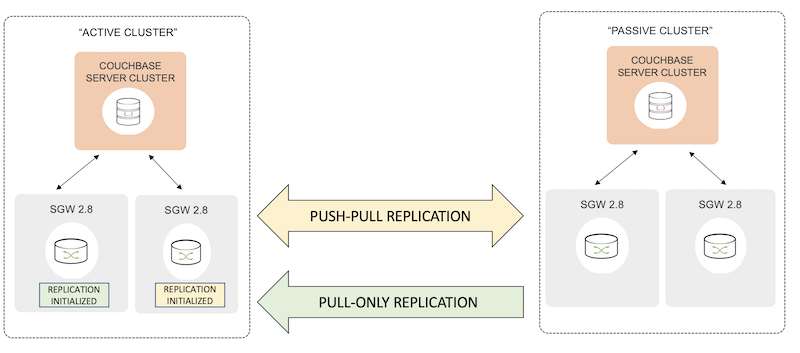
Consejo de configuración de la implantación
El clúster de Sync Gateway en el que se inicializa o programa la replicación es el "Clúster activo"y el clúster remoto de Sync Gateway que es el objetivo de la replicación es el "Clúster pasivo".
Si tiene varias réplicas que configurar entre dos clústeres, se recomienda que elija un clúster como clúster activo para todas sus réplicas. Esto es válido independientemente de la dirección de la replicación: push, pull o push-pull. Esta configuración simplifica el despliegue, la administración y la resolución de problemas de las réplicas.
Especialmente en el contexto de la sincronización nube-borde, prevemos que el borde será el clúster activo que inicie las réplicas al clúster de nube remoto. Es probable que los clústeres de borde no sean accesibles a través de una red externa.
Atributos de la tecnología Sync
Manejar la sincronización a escala a través de una red no fiable en condiciones de red poco fiables no es un reto fácil. Hay varias consideraciones a tener en cuenta y a continuación se ofrece una visión general de la replicación entre Gateways Sync. Consulte la documentación para más detalles
| Característica | Replicación inter-Sync Gateway |
|---|---|
| Escalabilidad | El número de datos de los bordes puede oscilar entre 10, 100 y 1000. El protocolo es capaz de escalar para manejar ese número de bordes |
| Seguridad | La sincronización se realiza a través de Internet, que es intrínsecamente poco fiable. Todos los datos se cifran mediante TLS y se aplican estrictos controles de acceso para impedir el acceso no autorizado a los datos. Además, se pueden desplegar diferentes políticas de control de acceso en la nube y en el extremo, y garantizar que un extremo comprometido no afecte a la nube ni a los demás centros de datos del extremo. |
| Resistencia de la red | El protocolo implementa un algoritmo de reintento exponencial. El periodo de reintento es configurable |
| Eficacia | Para optimizar el uso del ancho de banda de la red y reducir los costes de transferencia, el protocolo admite la sincronización delta, es decir, la posibilidad de sincronizar partes del documento que han cambiado. La sincronización puede funcionar tanto en modo continuo como en modo puntual. Así, las aplicaciones controlan cuándo sincronizar los datos y, por ejemplo, pueden elegir hacerlo en horas valle. |
| Conflictos de datos | Completa estrategia de resolución de conflictos. Sync Gateway proporciona soporte automático de resolución de conflictos con los resolutores fuera de la caja y usted puede definir su propia resolución de conflictos - similar a la forma en que se define la función de sincronización, puede definir una función JS como parte del archivo de configuración de Sync Gateway. |
| Facilidad operativa | Alta disponibilidad de las réplicas, equilibrio automático de la carga/distribución uniforme de las réplicas entre los nodos Sync Gateway y una interfaz REST para la administración y gestión remotas. |
| Topologías flexibles | Jerárquico. El número de niveles en la jerarquía puede ser superior a 1: por ejemplo, un centro de datos en la nube puede comunicarse con centros de datos posteriores que, a su vez, pueden comunicarse con más centros de datos posteriores. |
Ejemplos de configuraciones
En esta sección, ofrecemos algunos ejemplos de configuraciones típicas de replicadores.
Las réplicas se asignan a una base de datos y pueden configurarse en el módulo Archivo de configuración de Sync Gateway y programados durante el lanzamiento o pueden inicializarse mediante la función _replicación en cualquier momento después del inicio.
Por defecto, todos los nodos participan en las réplicas. Esto implica que las réplicas configuradas para un clúster de nodos Sync Gateway se distribuyen uniformemente entre todos los nodos. Un nodo Sync Gateway puede configurarse para no participar en la replicación mediante el parámetro sgreplicate_enabled opción de configuración.
Replicación pull-only one-shot con resolución de conflictos por defecto
En este ejemplo, una réplica con Id pull-from-target-oneshot está configurado para realizar una única extracción de documentos pertenecientes al canal canal:tiendacanal del almacenes en la base de datos remoto endpoint. Los documentos se replican en el mi_almacén_local base de datos. Las credenciales del usuario que replica se especifican a través de la opción nombre de usuario y contraseña parámetros.
La replicación se encuentra inicialmente en estado detenido y puede iniciarse posteriormente mediante replicationStatus endpoint. Sync Gateway gestiona automáticamente los conflictos mediante políticas predefinidas.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
curl -X PUT https://localhost:4985/my_local_store/_replication/pull-from-target-oneshot -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pull-from-target-oneshot", "remote": "https://remote-sgw-cluster:4984/stores", "direction": "pull", "username":"store1", "password":"sdfhdgsfh676767", "continuous": false, "filter":"sync_gateway/bychannel", "query_params": { "channels":["channel:storechannel"] }, "initial_state": "stopped" }' |
Replicación continua bidireccional con resolución de conflictos inmediata
En este ejemplo, una réplica con Id pushandpull-con-objetivo-continuo está configurado para hacer un continuo push y pull de documentos pertenecientes al canal canal:tiendacanal de almacenes en la base de datos remoto endpoint. Los documentos se replican en el mi_almacén_local base de datos. Las credenciales del usuario que replica se especifican a través de la opción nombre de usuario y contraseña parámetros.
La replicación se inicia automáticamente cuando se programa - este es el valor por defecto de estado_inicial bandera. En caso de conflicto, el bando remoto es el ganador.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
curl -X PUT https://localhost:4985/my_local_store/_replication/pushandpull-with-target-continuous -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pushandpull-with-target-continuous ", "remote": "https://remote-sgw-cluster:4984/stores", "direction": "pushAndPull", "username":"store1", "password":"sdfhdgsfh676767", "conflict_resolution_type": "remoteWins", "filter": "sync_gateway/bychannel", "query_params": { "channels":["channel:storechannel"] } }' |
Replicación continua bidireccional con resolución de conflictos personalizada
Este ejemplo es idéntico al caso anterior, salvo que asociamos un solucionador de conflictos personalizado al replicador. Ahora, cada vez que Sync Gateway detecta un conflicto durante la replicación, se invoca al solucionador de conflictos con las revisiones en conflicto. El solucionador tiene acceso al cuerpo completo del documento y a los metadatos que pueden utilizarse para resolver el conflicto. Por supuesto, puede optar por devolver cualquiera de las revisiones en conflicto para implementar el equivalente de la estrategia "LocalWins" o "RemoteWins".
BTW, no te apegues demasiado a los detalles de lo que está pasando en el resolver o su precisión/eficiencia. Estoy seguro de que hay mejores maneras de hacer esto en Javascipt - esto es sólo para demostrar el concepto.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
curl -X PUT https://localhost:4985/my_local_store/_replication/pushandpull-with-target-continuous -H 'Accept: application/json' -H 'Authorization: Basic ZGVtbzpwYXNzd29yZA==' -H 'Content-Type: application/json' -d ' { "replication_id": "pushandpull-with-target-continuous ", "remote": "https://remote-sgw-cluster:4984/stores", "direction": "pushAndPull", "username":"store1", "password":"sdfhdgsfh676767", "custom_conflict_resolver": "function(conflict) { function(conflict) { if ( (conflict.LocalDocument.type != null) && (conflict.RemoteDocument.type != null) && (conflict.LocalDocument.type == \"foo\")) { return defaultPolicy(conflict); } else { var remoteDoc = conflict.RemoteDocument; var localDoc = conflict.LocalDocument; var mergedDoc = extend({}, localDoc, remoteDoc); return mergedDoc; function extend(target) { var sources = [].slice.call(arguments, 1); sources.forEach(function (source) { for (var prop in source) { target[prop] = source[prop]; } }); return target; } } }", "filter": "sync_gateway/bychannel", "query_params": { "channels":["channel:storechannel"] } }' |
Por supuesto, hay muchos otros configuración opciones entre las que elegir que le permitirán personalizarlo para adaptarlo a las necesidades de su aplicación. Puede consultar los detalles en nuestra documentación.
Supervisión de las réplicas
Una vez que sus configuraciones estén en funcionamiento, puede supervisarlas a través de la función replicationStatus punto final. En 2.8, también lanzamos un nuevo endpoint de métricas en modo Developer Preview. Este endpoint también exporta estadísticas en formato Prometheus, lo que facilitará la monitorización con Prometheus y la visualización con Grafana. Puedes aprender más sobre esto en un próximo blog.
¿Y "SG-Replicate"?
Si ha estado trabajando con la puerta de enlace Sync, probablemente esté familiarizado con la función SG-Replicar que puede utilizarse para la replicación entre nodos Sync Gateway de distintos clústeres. La nueva versión del protocolo, que se basa en websockets, se ha rediseñado desde cero para ofrecer una serie de funciones de nivel empresarial, como el equilibrio de carga automático de las réplicas entre los nodos Sync Gateway participantes, alta disponibilidad (HA), resolución automática de conflictos integrada con solucionadores de conflictos personalizados, compatibilidad con sincronización delta, mejoras significativas en la escalabilidad y el rendimiento, etc.
Aunque "SG-Replicate" sigue siendo compatible con la versión 2.8, ha quedado obsoleta y las aplicaciones existentes deben migrar a la nueva versión de la tecnología de replicación entre Sync Gateways.
¿Qué sigue?
La solución de sincronización nube a nube de Couchbase Sync Gateway es segura, escalable y fácil de configurar y gestionar. sync es la única solución de sincronización de bases de datos peer-to-peer que permite a los clientes comunicarse directamente entre sí en entornos desconectados.
Puede descargar Sync Gateway y evauar la funcionalidad de forma gratuita.
Si quiere profundizar en los detalles, aquí puede encontrar más información
– Conectar vídeo con demostración: Utilización de la replicación de inter-Sync Gateway
– Documentación: Replicación inter-Sync Gateway
– Página de soluciones: Edge Computing
En Foros de Couchbase es un buen lugar para plantear preguntas. Por favor, deje un comentario a continuación o no dude en ponerse en contacto conmigo a través de Twitter o envíame un correo electrónico