En esta entrada del blog, echaremos un vistazo a la API de vista previa para la búsqueda de texto completo en Couchbase 4.5. Tenga en cuenta que esta API, publicada en el último SDK de Java (2.2.4), sigue siendo @Experimental.
Cubriremos:
- ¿Búsqueda de texto completo en Couchbase?
- La API de Java
- Varios tipos de consultas
- Obtener explicaciones de los aciertos
- Conclusión
Esta API experimental se puede utilizar con Couchbase Server 4.5 Developer Preview, siempre que se utilice la extensión 2.2.4 Java SDK client, que puedes obtener a través de Maven. Añada la siguiente dependencia a su pom.xml:
|
1 2 3 4 5 |
com.couchbase.client java-client 2.2.4 |
¿Búsqueda de texto completo en Couchbase?
Sí. El próximo 4.5 (nombre en clave Watson) incluirá un indexador de texto completo (FTS, también conocido como CBFT) basado en el programa de código abierto Bleve proyecto. Bleve trata sobre la búsqueda de texto completo y la indexación en Go (un saludo a nuestro propio Marty Schoch por iniciar este proyecto).
La idea es aprovechar Bleve para proporcionar una búsqueda de texto completo off-the-shelf en Couchbase Server, sin tener que utilizar conectores a software externo (que se ejecuta en su propio clúster). Si esa solución "off-the-shelf" no satisface sus necesidades hasta el final, por supuesto, todavía puede utilizar estos conectorespero para las necesidades más sencillas se puede optar por una única solución.
FTS ofrece una gran cantidad de capacidades que son proporcionadas por Bleve: Analizadores de texto, tokenizadores y filtros de tokens de posprocesamiento que van más allá del alcance de este post, así como los numerosos tipos de consultas que puede ejecutar en los índices resultantes. Veamos cuáles son esos tipos y cómo puedes esperar utilizarlos en el contexto del SDK de Java.
En el resto de esta entrada de blog, utilizaremos 3 índices que podrá crear a través de la consola de administración web en la próxima versión 4.5 Developer Preview:

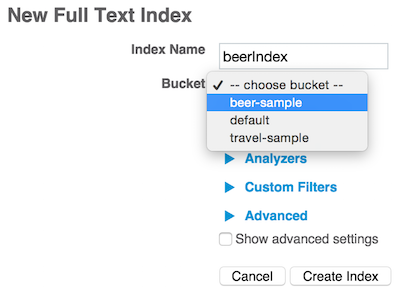
Esta es la lista de índices de la interfaz de usuario:
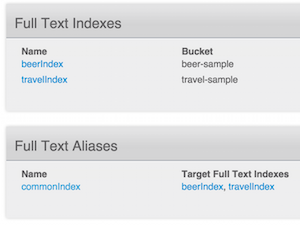
Tenemos:
- a
beerIndexque indexa todo el contenido de cada documento delcerveza-muestra - a
travelIndexque indexa todo el contenido de cada documento delviaje-muestra - un índice de alias,
commonIndexque es una unión de los dos índices anteriores.
La API de Java
El punto de entrada de la función de búsqueda de texto completo en el SDK de Java se encuentra en la carpeta Cuboutilizando el query(SearchQuery ftq) método. Esto es coherente con los métodos de consulta existentes ya presentes en la API para ejecutar un ViewQuery o un N1qlQuery.
La API para la búsqueda de texto completo sigue el constructor patrón. Identifique el tipo de consulta que desea y utilice el constructor correspondiente para construirla, obtenga la función BúsquedaQuery utilizando construir() y ejecutarlo utilizando bucket.query(searchQuery).
Tomemos un ejemplo (muy sencillo) y veamos cómo se puede consumir:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//we'll use that Cluster and Bucket for the remainder of the examples Cluster cluster = CouchbaseCluster.create("127.0.0.1"); Bucket bucket = cluster.openBucket("beer-sample"); //we use a simple form of query: SearchQuery ftq = MatchQuery.on("beerIndex").match("national").limit(3).build(); //we fire the query and look at results SearchQueryResult result = bucket.query(ftq); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { System.out.println(row); } |
Si examinamos cada sección por separado, esto es lo que ocurrió:
- Creamos un sencillo
MatchQueryen un solo plazo. - Se ejecuta en la muestra de cerveza (
.on(beerIndex), busca apariciones textuales de la palabra "nacional" (.query("nacional")) o términos cercanos. - Se realiza una configuración adicional para limitar el número de resultados a 3 (
límite(3)) y la consulta propiamente dicha se crea en este punto (.construir()). - La consulta se ejecuta (
bucket.query(ftq)) y devuelve unSearchQueryResult. - Emitimos el resultado de
totalHits()y las filas individuales (también accesibles como lista a través deaciertos()).
Ejecutando ese código sale:
|
1 2 3 4 |
totalHits: 31 SearchQueryHit{id='dc_brau', score=0.09068310490562362, fragments={}} SearchQueryHit{id='brouwerij_nacional_balashi', score=0.12085760187148556, fragments={}} SearchQueryHit{id='cervecera_nacional', score=0.09863195902067363, fragments={}} |
Vemos que el total de visitas nos da el número real de visitas antes de que se aplicara el límite. La dirección aciertos() devuelve 3 BúsquedaQueryRow objetos, según lo solicitado.
Cada acierto contiene la clave del documento asociado en Couchbase (id()), así como más información sobre la coincidencia, por ejemplo, una puntuación para la coincidencia (puntuación())... Si lo desea, puede recuperar el documento asociado utilizando bucket.get(fila.id()):
|
1 2 3 4 5 6 |
result = bucket.query(ftq); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { System.out.println(row); System.out.println(bucket.get(row.id()).content()); } |
Esto nos da, para el primer golpe:
|
1 2 3 |
SearchQueryHit{id='dc_brau', score=0.09068310490562362, fragments={}} {"country":"United States","website":"https://www.dcbrau.com/","code":"20018","address":["3178-B Bladensburg Rd. NE"],"city":"Washington","phone":"","name":"DC Brau", "description":"The first brewery to open in the nation's capital since Prohibition.","state":"DC","type":"brewery","updated":"2011-08-08 19:02:40"} |
Si observamos detenidamente el JSON del documento, nos daremos cuenta de dónde probablemente coincidía el documento. En el campo "descripción" del documento, aparece esta frase:
La primera cervecería que abrió sus puertas en nacióndesde la Prohibición.
Observe también que la consulta de texto buscó la palabra solicitada y las palabras derivadas que tienen la misma raíz. En realidad, aplicó una imprecisión de 2 (véase la sección siguiente).
Este patrón también puede aplicarse a otros tipos de consulta, así que veamos algunos más para ver qué tipo de búsqueda puede realizarse.
Varios tipos de consultas
Consulta difusa
La consulta difusa puede realizarse con la función MatchQueryespecificando un Distancia Levenshtein como máximo imprecisión() permitir en el plazo:
|
1 2 3 4 5 6 7 8 9 10 11 |
result = bucket.query(MatchQuery.on("beerIndex") .match("sammar") .field("name") .fuzziness(2) //actually the default .build()); System.out.println("nFuzzy Match Query"); System.out.println("totalHits (fuzziness = 2): " + result.totalHits()); for (SearchQueryRow row : result) { System.out.println(bucket.get(row.id()).content().get("name")); } |
A un nivel de 2Esto coincide con palabras como "martillo", "mamá" o "verano":
|
1 2 3 4 5 |
Fuzzy Match Query totalHits (fuzziness = 2): 45 Mamma Mia! Pizza Beer Redhook Long Hammer IPA Summer Wheat |
A un nivel de 1no se encuentra ninguna coincidencia:
|
1 2 |
Fuzzy Match Query totalHits (fuzziness = 1): 0 |
También se ofrece un tipo de consulta dedicada a la imprecisión y que no aplica ningún analizador en el FuzzyQuery.
Términos múltiples: MatchPhrase
Como hemos visto, MatchQuery es una consulta basada en términos que permite especificar opcionalmente la imprecisión y también aplica al término buscado el mismo filtro que se haya podido aplicar al campo (por ejemplo, stemming, etc...):
|
1 2 3 4 |
MatchQuery.on("beerIndex") .match("sesonal") .fuzziness(2) .field("description").build(); |
Puede buscar varios términos en una sola consulta utilizando un atributo Frase de partido consulta. Se analizan los términos y se puede activar opcionalmente la imprecisión:
|
1 |
MatchPhraseQuery.on("beerIndex").matchPhrase("summer seasonal").field("description"); |
Consulta Regexp
A RegexpQuery no sólo hace coincidencias literales, sino que permite hacer coincidencias utilizando una expresión regular. Tome este ejemplo:
|
1 2 3 4 5 6 7 8 9 10 |
result = bucket.query(RegexpQuery.on("beerIndex") .regexp("[tp]ale") .field("name") .build()); System.out.println("nRegexp Query"); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { System.out.println(bucket.get(row.id()).content().get("name")); } |
Observe que esta consulta se dirige a un campo concreto del archivo json (campo("nombre")). Queremos todos los nombres que contengan "cuento" o "pálido". He aquí algunos nombres que coinciden con esta búsqueda:
|
1 2 3 4 5 |
Regexp Query totalHits: 408 Tall Tale Pale Ale Bard's Tale Beer Company Pale Ale |
Prefijo Consulta
A PrefixQuery busca apariciones de palabras que empiecen por la cadena dada:
|
1 2 3 4 5 6 7 8 9 10 |
result = bucket.query(PrefixQuery.on("beerIndex") .prefix("weiss") .field("name") .build()); System.out.println("nPrefix Query"); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { System.out.println(bucket.get(row.id()).content().get("name")); } |
Una vez más, sólo miramos dentro del nombre campo, esta vez para las palabras que empiezan por "weiss":
|
1 2 3 4 5 6 |
Prefix Query totalHits: 74 Bavarian-Weissbier Hefeweisse / Weisser Hirsch Münchner Kindl Weissbier / Münchner Weisse Franziskaner Hefe-Weissbier Hell / Franziskaner Club-Weiss Weissenheimer Wheat |
Consultas por rango y fecha
FTS también funciona bien con datos no textuales. Por ejemplo, el NumericRangeQuery permite buscar valores numéricos dentro de un intervalo proporcionado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
result = bucket.query(NumericRangeQuery.on("beerIndex") .min(3) .max(4) .field("abv") .fields("name", "abv") .build()); System.out.println("nNumeric Range Query"); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { JsonDocument doc = bucket.get(row.id()); System.out.println(""" + doc.content().get("name") + "", abv: " + doc.content().get("abv")); } |
Qué salidas:
|
1 2 3 4 5 |
Numeric Range Query totalHits: 62 "Stud Service Stout", abv: 3.1 "Blonde", abv: 3.0 "Locke Mountain Light", abv: 3.7 |
Las fechas también se cubren con el DateRangeQuery:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Calendar calendar = Calendar.getInstance(); calendar.set(2011, Calendar.MARCH, 1); Date start = calendar.getTime(); calendar.set(2011, Calendar.APRIL, 1); Date end = calendar.getTime(); result = bucket.query(DateRangeQuery.on("beerIndex") .start(start) .end(end) .field("updated") .fields("name", "updated") .build()); System.out.println("nDate Range Query"); System.out.println("totalHits: " + result.totalHits()); for (SearchQueryRow row : result) { JsonDocument doc = bucket.get(row.id()); System.out.println(""" + doc.content().get("name") + "", updated: " + doc.content().get("updated")); } |
Qué salidas:
|
1 2 3 4 5 6 |
Date Range Query totalHits: 4 "Dank", updated: 2011-03-16 09:06:54 "Oso", updated: 2011-03-16 09:05:15 "Summer Teeth", updated: 2011-03-08 12:22:14 "Columbus Brewing Company", updated: 2011-03-08 12:19:07 |
Consulta genérica
FTS también ofrecen una forma más genérica de consulta que combina frases, términos y más utilizando la función Cadena Sintaxis de consulta. Se puede acceder a él en la API a través de la función StringQuery.
Combinación de
Además, puede combinar criterios sencillos como MatchQuery mediante consultas combinadas. Tomando estas dos simples consultas de términos:
|
1 2 |
MatchQuery bitterQuery = MatchQuery.on("beerIndex").match("bitter").field("description").build(); MatchQuery maltyQuery = MatchQuery.on("beerIndex").match("malty").field("description").build(); |
Puedes combinarlos de diferentes maneras:
- a
conjunciónbusca todos los términos
|
1 |
ConjunctionQuery.on("beerIndex").conjuncts(bitterQuery, maltyQuery) |
- a
disyunciónbusca al menos un término
|
1 |
DisjunctionQuery.on("beerIndex").disjuncts(bitterQuery, maltyQuery) |
- a
consulta booleanapermite combinar los dos enfoques
|
1 |
BooleanQuery.on("beerIndex").must(bitterQuery).mustNot(maltyQuery) |
Obtener explicaciones de los aciertos
Si desea obtener información sobre la puntuación y el emparejamiento de un determinado BúsquedaQueryRowpuede construir su consulta utilizando la función .explain(true) y obtener los detalles del índice en el parámetro explicación() campo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
{"message":"sum of:","children":[{"message":"product of:","children":[{"message":"sum of:","children":[{"message":"product of:","children":[{"message":"sum of:","children":[ { "message": "weight(_all:national^1.000000 in penn_brewery-penn_marzen), product of:", "children": [ { "message": "queryWeight(_all:national^1.000000), product of:", "children": [ { "message": "boost", "value": 1 }, { "message": "idf(docFreq=17, maxDocs=7303)", "value": 7.005668743723945 }, { "message": "queryNorm", "value": 0.1427415478209491 } ], "value": 0.9999999999999999 }, { "message": "fieldWeight(_all:national in penn_brewery-penn_marzen), product of:", "children": [ { "message": "tf(termFreq(_all:national)=1", "value": 1 }, { "message": "fieldNorm(field=_all, doc=penn_brewery-penn_marzen)", "value": 0.10000000149011612 }, { "message": "idf(docFreq=17, maxDocs=7303)", "value": 7.005668743723945 } ], "value": 0.7005668848116544 } ], "value": 0.7005668848116543 } ],"value":0.7005668848116543},{"message":"coord(1/1)","value":1}],"value":0.7005668848116543}],"value":0.7005668848116543},{"message":"coord(1/1)","value":1}],"value":0.7005668848116543}],"value":0.7005668848116543} |
Conclusión
Esperamos que este avance de la API haya despertado su interés.
Descárguese el primer Vista previa para desarrolladores de Couchbase 4.5 con servicio integrado de búsqueda de texto completo. Esperamos que pueda empezar a buscar rápidamente utilizando el servicio asociado API del SDK de Java.
Y hasta entonces... ¡Feliz codificación!
– El equipo del SDK de Java