Agrupación agregada es como voy a titular esta entrada del blog, pero no sé si es el mejor nombre. ¿Alguna vez has utilizado MySQL Función GROUP_CONCAT o el PARA XML RUTA('') solución en SQL Server? Eso es básicamente sobre lo que estoy escribiendo hoy. Con Couchbase Server, la forma más fácil de hacerlo es con N1QL's ARRAY_AGG pero también puedes hacerlo con una vista MapReduce de la vieja escuela.
Escribo este post porque uno de nuestros ingenieros de soluciones estaba trabajando en este problema para un cliente (cuyo nombre se mantendrá en el anonimato). Ninguno de los dos pudo encontrar una entrada de blog como esta con la respuesta, así que después de trabajar juntos para encontrar una solución, decidí que escribiría un blog sobre ello para mi futuro yo (que es más o menos la razón principal por la que escribo cualquier cosa, en realidad. La otra razón es saber si alguien conoce una forma mejor).
Antes de empezar, he puesto a tu disposición algo de material por si quieres seguirme la pista. El código fuente que utilicé para generar los datos del "paciente" utilizados en este post está disponible en GitHub. Si no eres experto en .NET, puedes utilizar cbimport en datos de muestra que he creado. (O, puede utilizar el Caja de arena N1QL(más información al respecto más adelante). El resto de esta entrada del blog asume que usted tiene un cubo "pacientes" con los datos de la muestra en el mismo.
Requisitos
Tengo un cubo de documentos de pacientes. Cada paciente tiene un único médico. El documento del paciente se refiere a un médico mediante un campo llamado doctorId. Puede haber otros datos en el documento del paciente, pero nos centramos principalmente en la clave del documento del paciente y el doctorId valor. Algunos ejemplos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
key 01257721 { "doctorId": 58, "patientName": "Robyn Kirby", "patientDob": "1986-05-16T19:01:52.4075881-04:00" } key 116wmq8i { "doctorId": 8, "patientName": "Helen Clark", "patientDob": "2016-02-01T04:54:30.3505879-05:00" } |
A continuación, podemos suponer que cada médico puede tener varios pacientes. También podemos suponer que existe un documento de médico, pero en realidad no lo necesitamos para este tutorial, así que vamos a centrarnos en los pacientes por ahora.
Por último, lo que queremos para nuestra aplicación (o informe o lo que sea), es una agrupación agregada de los pacientes con su médico. Cada registro identificaría un médico y una lista/array/colección de pacientes. Algo así como
| doctor | pacientes |
|---|---|
|
58 |
01257721, 450mkkri, 8g2mrze2 ... |
|
8 |
05woknfk, 116wmq8i, 2t5yttqi ... |
|
... etc ... |
... etc ... |
Esto podría ser útil para un cuadro de mando que muestre todos los pacientes asignados a médicos, por ejemplo. Cómo podemos obtener los datos de esta forma, con N1QL o con MapReduce?
N1QL Agrupación agregada
N1QL nos da la ARRAY_AGG función para hacerlo posible.
Empiece seleccionando el doctorId de cada documento de paciente, y la clave del documento de paciente. A continuación, aplique ARRAY_AGG al ID del documento del paciente. Por último, agrupe los resultados por el doctorId.
|
1 2 3 |
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients FROM patients p GROUP BY p.doctorId; |
Nota: no olvides ejecutar CREAR ÍNDICE PRIMARIO EN pacientes para este tutorial para habilitar un escaneo de índice primario.
Imagínese esta consulta sin ARRAY_AGG. Devolvería un registro por cada paciente. Añadiendo el ARRAY_AGG y el GRUPO PORahora devuelve un registro por cada médico.
A continuación se muestra un fragmento de los resultados en el conjunto de datos de muestra que he creado:
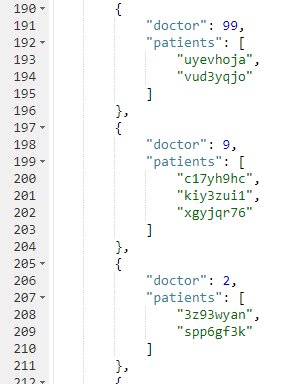
Si no quiere tomarse la molestia de crear un cubo e importar datos de muestra, también puede intentarlo en la función Sandbox tutorial N1QL. No hay documentos de pacientes, por lo que la consulta será un poco diferente.
Voy a agrupar los correos electrónicos por edad. Empieza seleccionando la edad de cada documento, y el email de cada documento. A continuación, aplica ARRAY_AGG al correo electrónico. Por último, agrupa los resultados por edad.
|
1 2 3 |
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails FROM tutorial t group by t.age; |
Aquí tienes una captura de pantalla de algunos de los resultados del sandbox:

Grupo agregado con MapReduce
También se puede lograr una agrupación agregada similar con una vista MapReduce.
Empieza creando una nueva Vista. Desde la consola de Couchbase, ve a Índices y luego a Vistas. Selecciona el bucket "pacientes". Haz clic en "Crear vista de desarrollo". Nombra un documento de diseño (yo llamé al mío "_design/dev_patient". Crea una vista, yo llamé a la mía "doctorPatientGroup".
Necesitaremos tanto una función Map como una función Reduce personalizada.
En primer lugar, para el mapa, sólo queremos el doctorId (en una matriz, ya que vamos a utilizar la agrupación) y el ID del documento del paciente.
|
1 2 3 |
function (doc, meta) { emit([doc.doctorId], meta.id); } |
A continuación, para la función reducir, tomaremos los valores y los concatenaremos en un array. A continuación se muestra una forma en que usted puede hacerlo. No pretendo ser un experto en JavaScript o un experto en MapReduce, por lo que podría haber una manera más eficiente para hacer frente a esto:
|
1 2 3 4 |
function reduce(key, values, rereduce) { var merged = [].concat.apply([], values); return merged; } |
Una vez creadas las funciones map y reduce, guarda el índice.
Por último, cuando llame a este índice, establezca group_level en 1. Puede hacerlo en la interfaz de usuario:
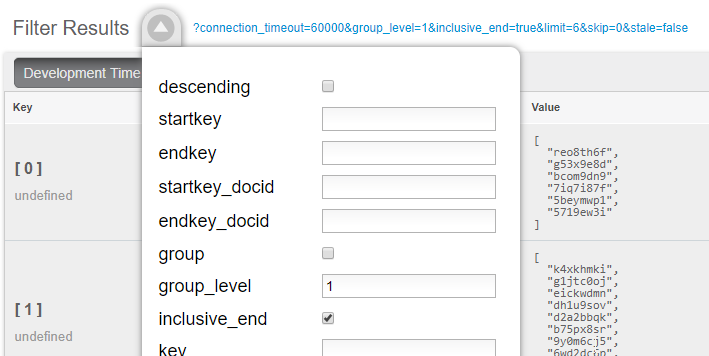
O puede hacerlo desde la URL del índice. He aquí un ejemplo de un clúster que se ejecuta en mi máquina local:
|
1 |
https://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=false |
El resultado de esa vista debería tener este aspecto (truncado para que quede más bonito en una entrada de blog):
|
1 2 3 4 5 6 7 8 9 |
{"rows":[ {"key":[0],"value":["reo8th6f","g53x9e8d", ... ]}, {"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]}, {"key":[2],"value":["spp6gf3k","3z93wyan"]}, {"key":[3],"value":["qnx93fh3","gssusiun", ...]}, {"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]}, {"key":[5],"value":["ywjfvad6","so4uznxx", ...]} ... ]} |
Resumen
Creo que el método N1QL es más fácil, pero puede haber beneficios de rendimiento para el uso de MapReduce en algunos casos. En cualquier caso, se puede lograr la agrupación agregada tan fácilmente (si no más fácilmente) como en una base de datos relacional.
¿Quieres saber más sobre N1QL? No deje de consultar el tutorial/sandbox completo de N1QL. ¿Le interesan las vistas MapReduce? Eche un vistazo a las Documentación sobre MapReduce Views para empezar.
¿Le ha resultado útil este post? ¿Tiene sugerencias para mejorarlo? Deje un comentario a continuación o póngase en contacto conmigo en Twitter @mgroves.