Desbloquee el razonamiento avanzado con un menor coste total de propiedad para la IA empresarial
Hoy, estamos encantados de compartir que DeepSeek-R1 está ahora integrado en Capella AI Services, ¡disponible en vista previa! Este potente modelo destilado, basado en Llama 8B, mejora su capacidad para crear aplicaciones agenticas con razonamiento avanzado, al tiempo que garantiza el cumplimiento de la privacidad.
En este blog, demostraremos cómo aprovechar estos modelos mediante la creación de un chatbot para mejorar la búsqueda empresarial y la gestión del conocimiento. Con las potentes capacidades de inferencia de DeepSeek, las organizaciones pueden mejorar:
-
- Revisión jurídica y de conformidad
- Automatización de la atención al cliente
- Solución de problemas técnicos
Para esta demostración, utilizaremos DeepSeek Distill-Llama-3-8B, pero Capella AI Services en GA planea introducir variantes de mayor parámetro del modelo para ampliar aún más sus capacidades.
🚀 ¿Le interesa probar DeepSeek-R1? Echa un vistazo Servicios de IA de Capella o Inscríbase en el Vista previa privada.
Comprender el modelo DeepSeek
Enfoque de destilación
DeepSeek Distill-Llama-3-8B se entrena con destilación de conocimientosdonde a modelo de profesor más grande (DeepSeek-R1) orienta la formación de un modelo de estudiante más pequeño y eficiente (Llama 3 8B). El resultado es un modelo compacto pero potente que conserva una gran capacidad de razonamiento al tiempo que reduce los costes computacionales.
Conjunto de datos: evaluación comparativa con BEIR
Estamos evaluando las capacidades de razonamiento del modelo utilizando el Conjunto de datos BEIRun punto de referencia estándar para razonamiento basado en la recuperación. El conjunto de datos consta de 75K documentos en varios ámbitos, estructurados del siguiente modo:
|
1 2 3 4 5 6 |
{ "_id": "632589828c8b9fca2c3a59e97451fde8fa7d188d", "title": "A hybrid of genetic algorithm and particle swarm optimization for recurrent network design", "text": "An evolutionary recurrent network which automates the design of recurrent neural/fuzzy networks using a new evolutionary learning algorithm is proposed in this paper...", "query": "what is gappso?" } |
La capacidad del modelo se comprueba determinando qué documentos contienen las respuestas correctas a determinadas consultasdemostrando su fuerza de razonamiento.
Primeros pasos: implantación de DeepSeek en Capella AI Services
Paso 1: Ingesta de documentos
Ahora puede generar incrustaciones vectoriales para documentos estructurados y no estructurados utilizando los servicios de Capella AI. En primer lugar, vamos a importar los documentos estructurados del conjunto de datos BEIR en una colección couchbase antes de desplegar un flujo de trabajo de vectorización.
Configura un clúster de base de datos operativo de 5 nodos (¡o más grande!) en Couchbase Capella con las funciones de búsqueda y eventos habilitadas. Puedes aprovechar una opción de despliegue multinodo preconfigurada o crear una configuración personalizada.

Una vez desplegado el clúster, diríjase a la sección Importar en la pestaña Herramientas de datos y haga clic en la opción de importación. Para grandes conjuntos de datos, puede utilizar la opción cb-import función.
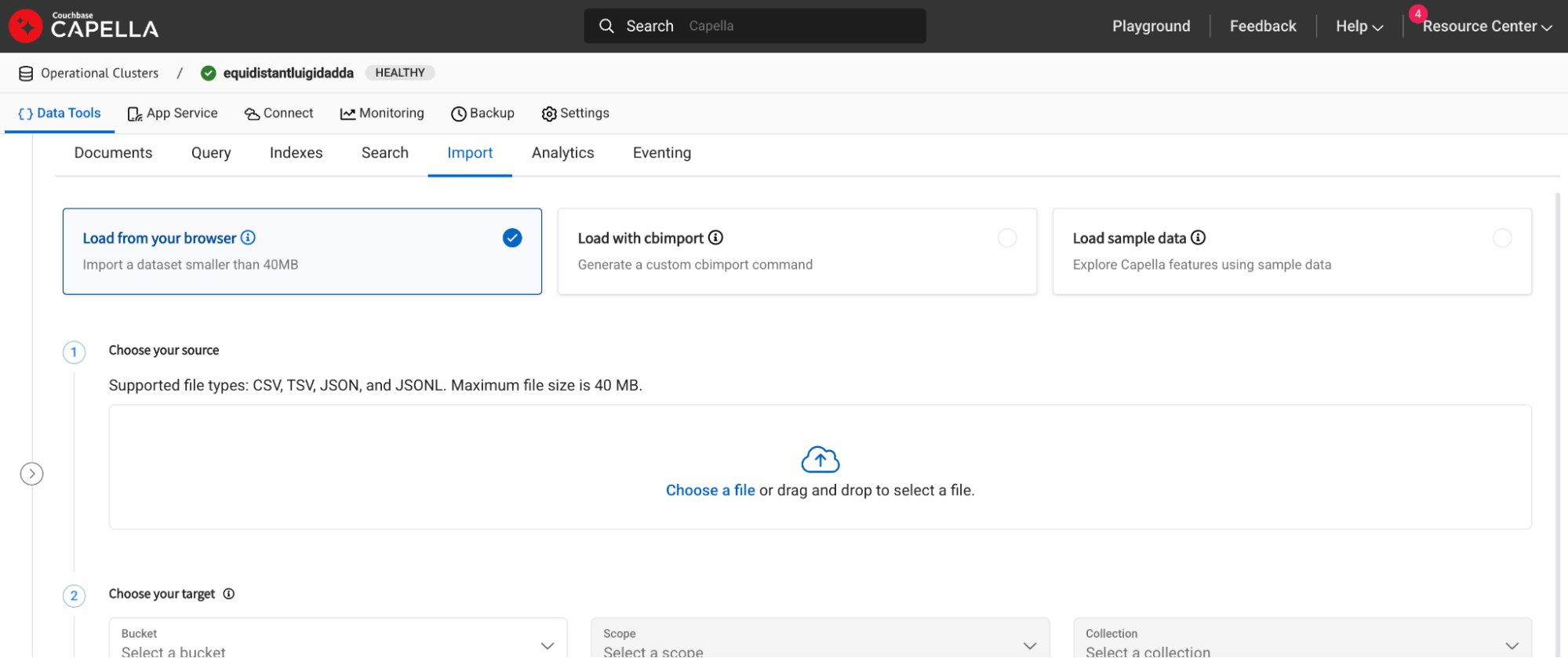

Paso 2: Establecer un modelo de incrustación
Vuelve a la pestaña de modelos en la pestaña de servicios de Capella AI. Haga clic en el botón Modelo de servicio antes de seleccionar las siguientes opciones:
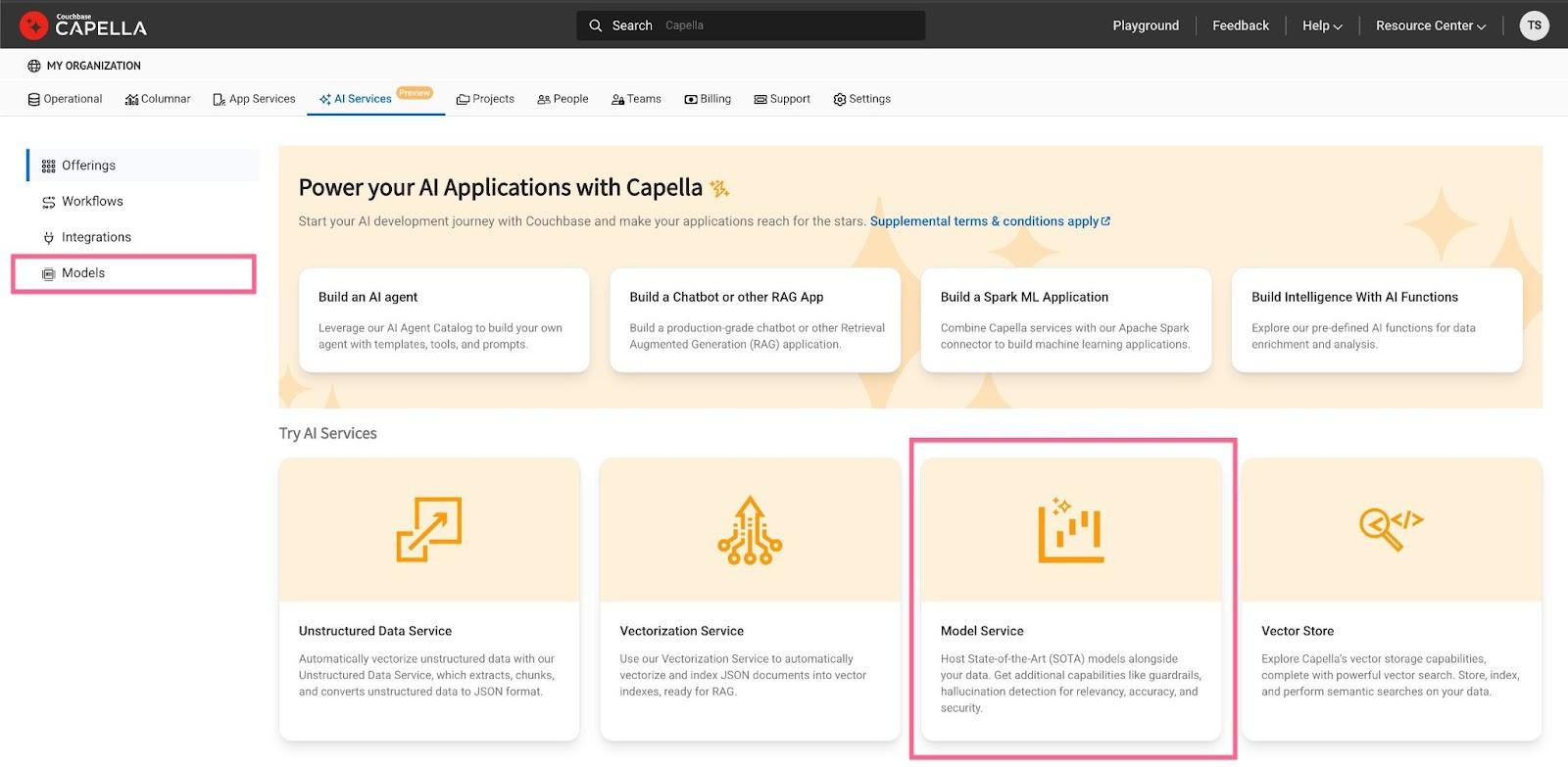

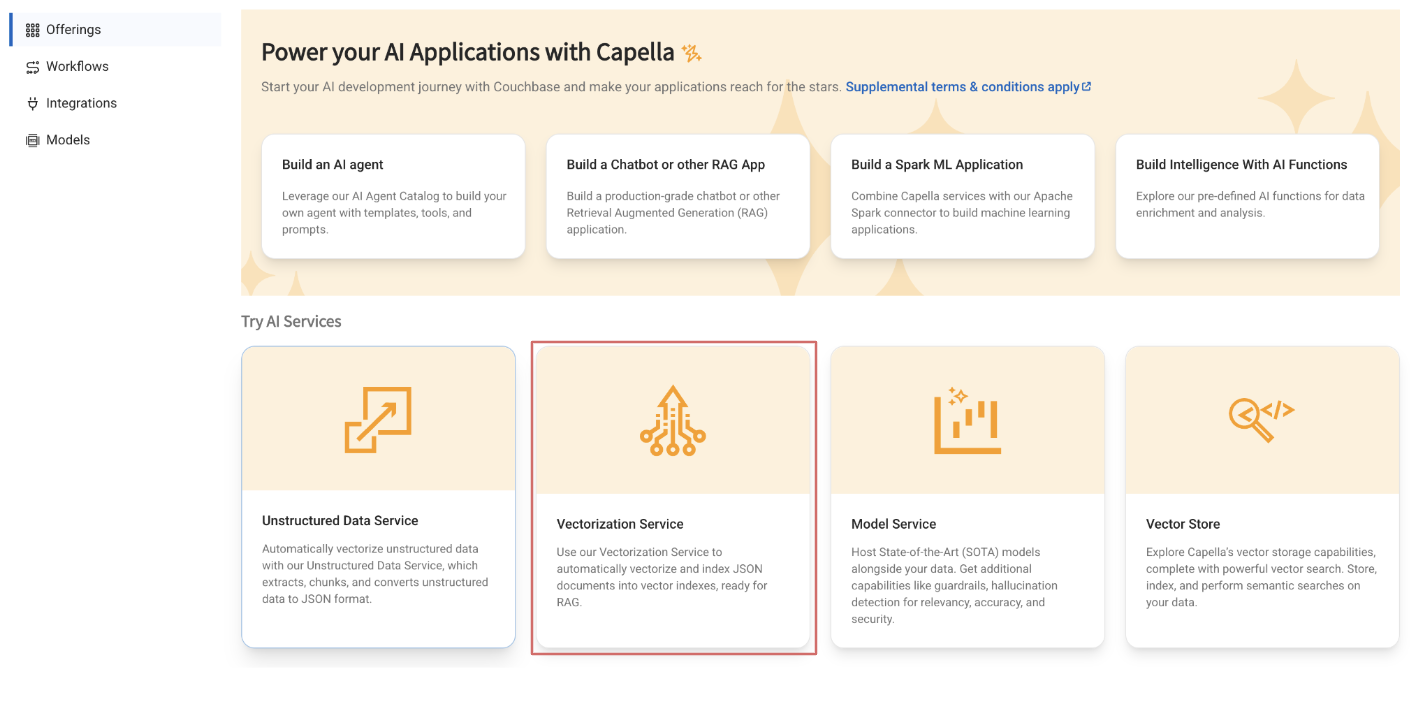
Paso 3: Configurar un flujo de trabajo de vectorización
Ahora que los documentos han sido ingestados, consulte este post para más detalles sobre cómo desplegar un flujo de trabajo de vectorización.
Asigne un nombre a su flujo de trabajo y especifique la colección que contiene los documentos ingestados.

Seleccione el modelo de incrustación desplegado en el paso anterior.
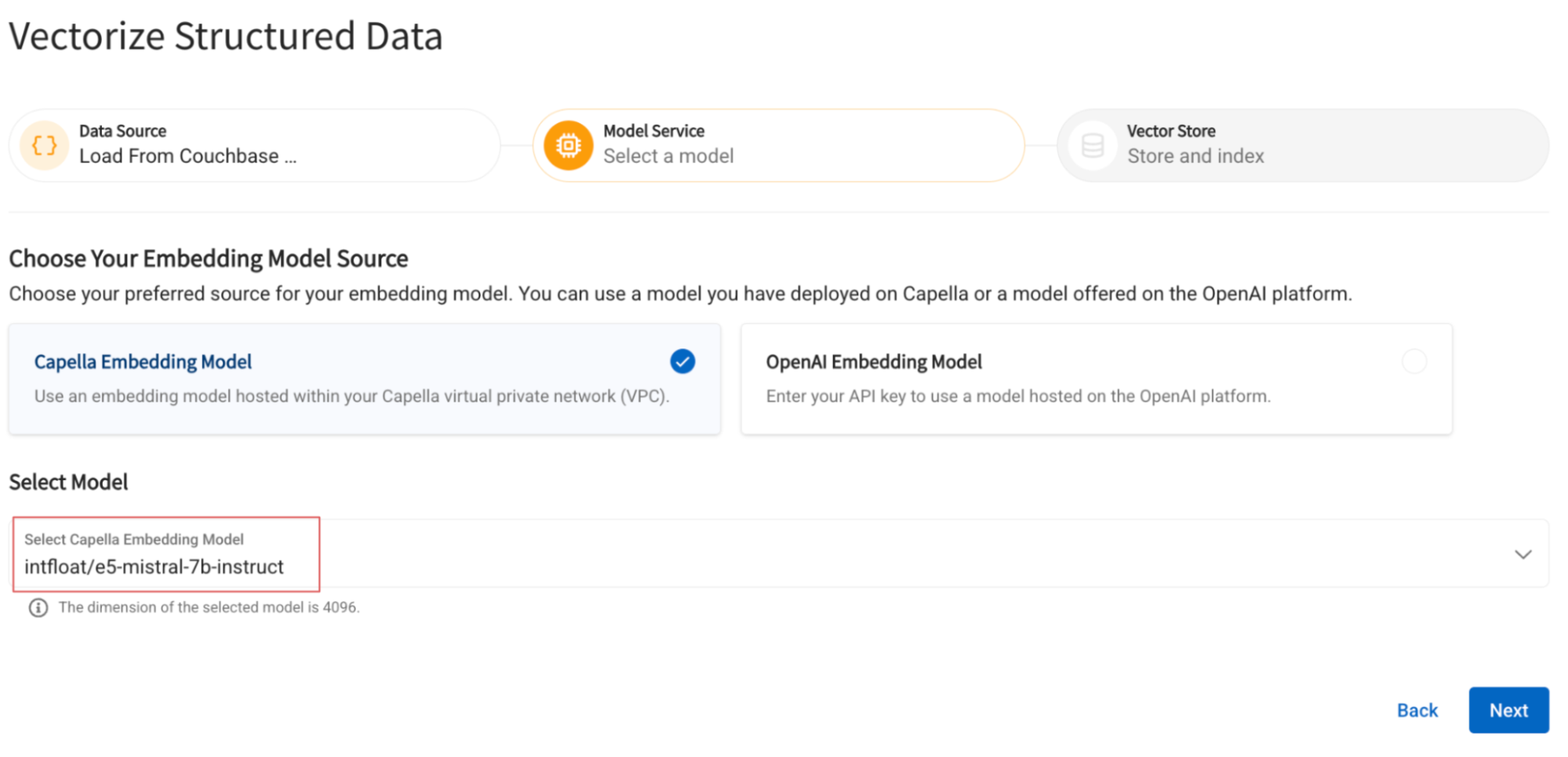
Especifique el nombre del campo en el que se insertarán los vectores generados y el nombre del índice que se construirá sobre él:
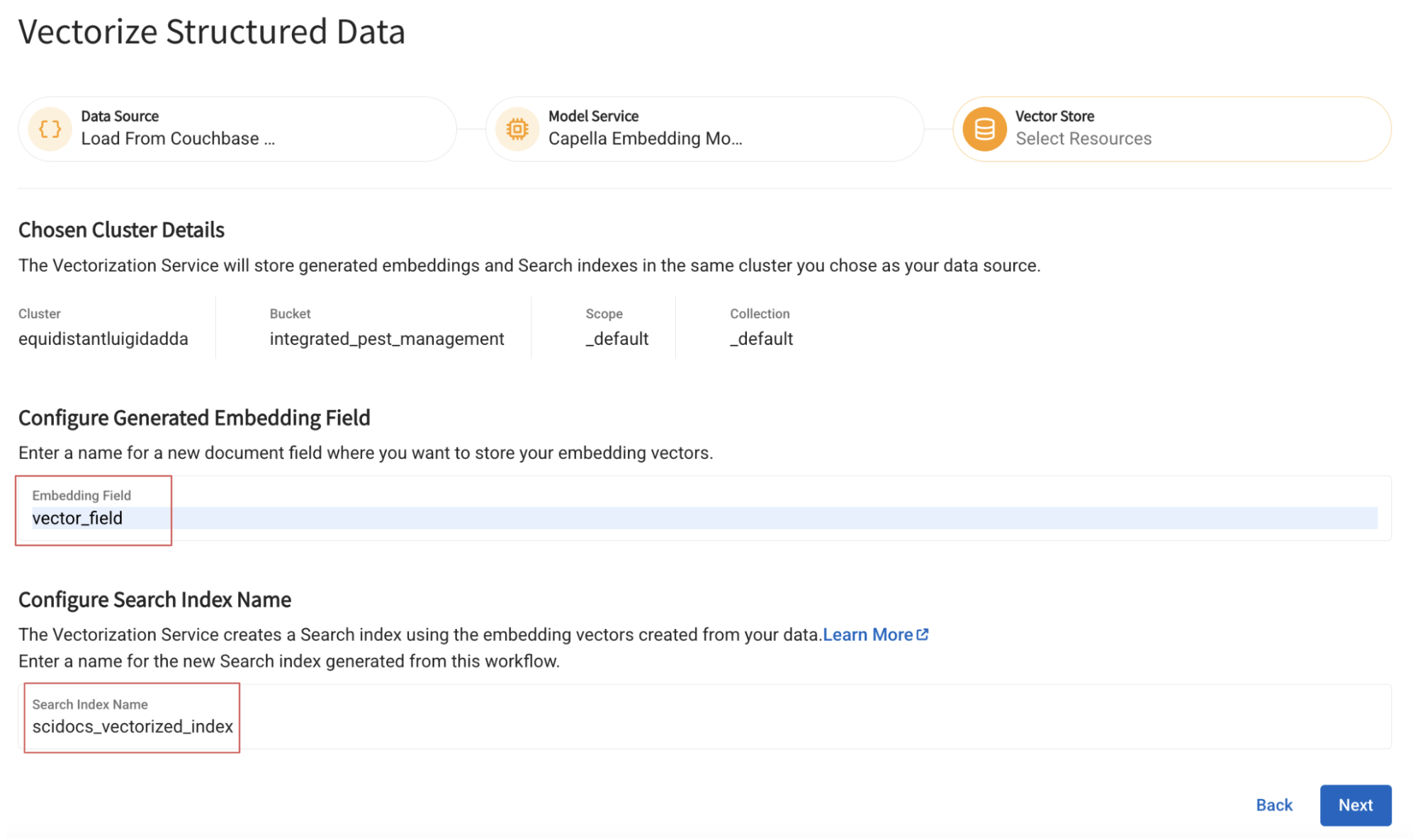
Paso 4: Configurar el modelo DeepSeek
Vuelve a la sección de servicios de Capella AI y haz clic en la pestaña de modelos y haz clic en el botón Modelo de servicio antes de seleccionar las siguientes opciones:
Seleccione el clúster de base de datos operativa creado anteriormente en el menú desplegable, seleccione el Capella Pequeño y el modelo DeepSeek Distill-LLama-3-8B en el menú desplegable.

Configure la caché seleccionando un bucket-scope-collection y marcando la casilla Caché conversacional caja.

Crear una aplicación con DeepSeek
Paso 1: Configurar los ajustes para que la aplicación acceda a los datos
Asegúrese de que su dirección IP está en la lista blanca para acceder a los documentos de su base de datos operativa. Para ello, vaya a la página Conectar del clúster operativo creado anteriormente.

Paso 2: Ejecutar la aplicación
Utilice el ejemplo proporcionado aquí para configurar una aplicación que recupere los documentos del conjunto de datos BEIR almacenados en su base de datos operativa y, a continuación, genere una respuesta. Asegúrese de especificar correctamente sus credenciales de base de datos codificadas en base64 y el punto final del modelo. Puede encontrar el punto final del modelo accediendo a la carpeta Servicios de IA -> Modelos y, a continuación, haga clic en el botón de flecha hacia abajo, que mostrará la configuración del modelo.
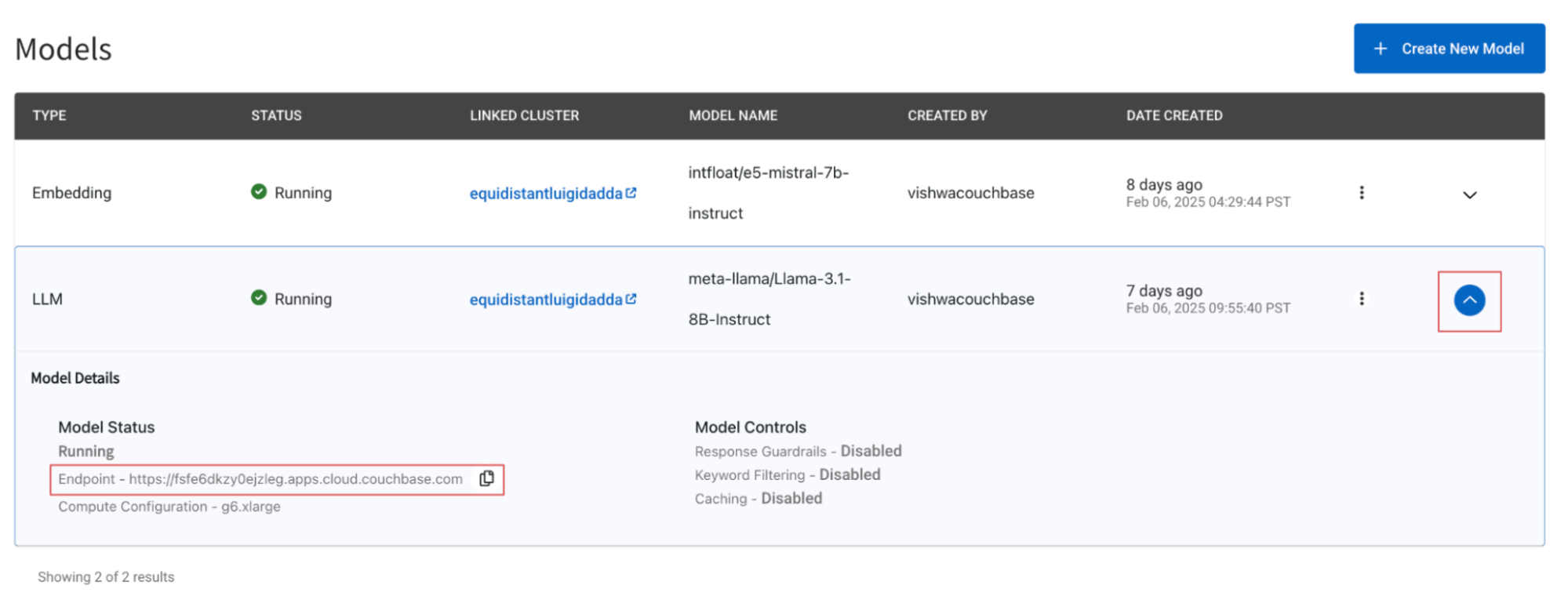
Paso 3: Probar el DeepSeek-R1-Distill-Llama-8B
Envíe una consulta de ejemplo al modelo y compruebe los resultados. Una vez que haya verificado la respuesta del modelo, puede ejecutar todo el conjunto de datos a través del modelo.
Próximos pasos
-
- 🚀 Acceso anticipado a DeepSeek-R1 - Inscribirse en la lista de espera
- 📖 Más información sobre los modelos DeepSeek - Documento de investigación DeepSeek
- 🔗 Explorar el conjunto de datos BEIR - Repositorio oficial BEIR
Capella AI Services está aquí para ayudarle a crear aplicaciones impulsadas por IA con los mejores modelos de su clase. ¡Innovemos juntos!
