Cualquier aplicación web moderna que interactúe con usuarios de distintas localidades debe hacer frente a distintos requisitos de privacidad y directrices de consentimiento de datos de los usuarios. Esto puede resultar abrumador para cualquier equipo de ingenieros, tanto si se trata de un equipo de cincuenta personas como de uno solo.
¿Cómo simplificar el proceso para eliminar las complicaciones y reducir la probabilidad de incumplimiento?
En esta guía, recorreremos una implementación que aprovecha los servicios de AWS que trabajan en conjunto con Couchbase para desinfectar los datos antes de que lleguen a un almacén de datos. Esta implementación simplificada se puede utilizar en cualquier contexto y se puede ampliar para adaptarla al caso de uso que esté creando.
tl;dr ¿Te interesa ver sólo el código junto con un LÉAME que contiene instrucciones de despliegue? Encuentra todo lo que necesitas en GitHub.
Visión general
Ejemplo
Imagine una pequeña plataforma de comercio electrónico que vende artesanía única hecha a mano. Este sitio funciona con un modelo de compra única, lo que significa que los usuarios no tienen que crear cuentas ni iniciar sesión. Los compradores simplemente navegan por el catálogo, seleccionan los artículos que desean comprar y pasan por caja. Durante el proceso de compra, proporcionan información esencial como nombre completo, dirección postal, dirección de facturación, información de pago, número de teléfono y dirección de correo electrónico. Esta información personal es necesaria para completar la compra y garantizar que el artículo se envía a la dirección correcta.
Una vez realizado el pedido, los datos viajan a través de varios microservicios. El servicio de procesamiento de pedidos valida los detalles y comprueba el inventario, el servicio de pago gestiona de forma segura la información de facturación para procesar las transacciones y el servicio de envío utiliza la dirección postal facilitada para organizar la entrega.
El sitio está diseñado para ofrecer a los usuarios una experiencia de compra fluida y sencilla. No hay cuentas. No es necesario pasar por un largo proceso de registro. Basta con elegir el artículo que se quiere comprar, realizar el pago junto con la información de envío y listo. Sin embargo, mientras que el cliente ha tenido una experiencia de compra sin fricciones, sus datos personales no pueden tener la misma experiencia sin fricciones en su aplicación. Para mantener la privacidad y cumplir la normativa, esta IIP debe ser desinfectada antes de ser almacenada en la base de datos del historial de compras a largo plazo.
Aunque este escenario pueda parecer único, en realidad es una situación que puede darse en nuestras aplicaciones todo el tiempo. Toda aplicación que recopile cualquier aspecto de la información de un usuario debe garantizar un consentimiento riguroso y cumplir las leyes y normativas de cada localidad en la que opere en todo el mundo. Esto puede suponer un enorme reto, y conlleva graves ramificaciones si no se hace correctamente.
Flujo de trabajo de la solución
Para gestionar eficazmente los requisitos de privacidad de los datos en tiempo real, tendremos que aprovechar las capacidades de datos en tiempo real de AWS y Couchbase para transformar los datos en cuanto se crean. Es un reto legal almacenar datos privados incluso durante un momento en una base de datos de acuerdo con la normativa GDPR. Como tal, no solo es una buena práctica de datos añadir los datos solo después de que se hayan desinfectado, sino que incluso puede ser un requisito legal.
La solución que estamos creando aprovechará AWS Simple Queue Service (SQS), Elastic Container Registry (ECR) y una función Lambda que trabaja en asociación con Couchbase Capella, la base de datos como servicio (DBaaS) totalmente administrada. Este flujo de trabajo se puede implementar con cualquier remitente de mensajes al servicio de cola, que iniciará el proceso de saneamiento de datos. En otras palabras, es plug and play.
El siguiente flujo de trabajo demuestra visualmente cómo funciona la solución.
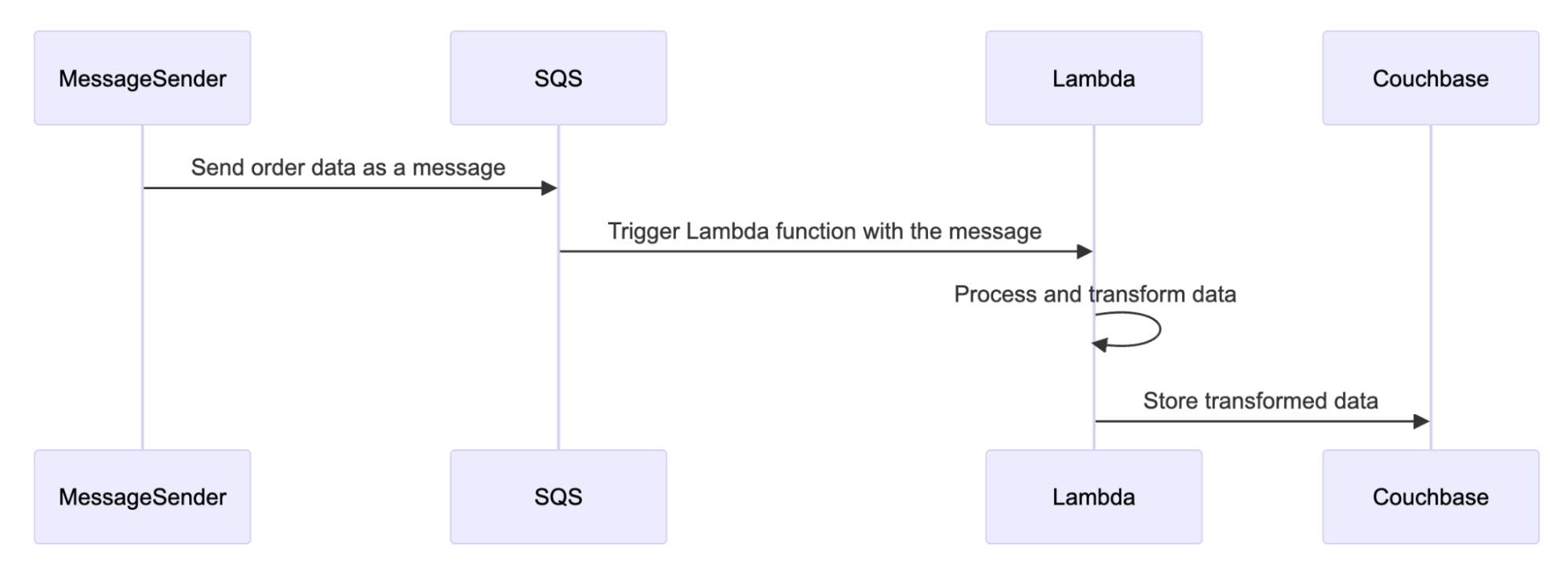
En primer lugar, cualquier emisor de mensajes envía datos al servicio de cola. Esto activa la función Lambda con el mensaje. La función Lambda procesa y transforma los datos eliminando toda la IIP del mensaje. Finalmente, los datos desinfectados se envían a Couchbase para ser añadidos de forma segura al almacén de datos.
Ahora que entendemos el flujo de trabajo, ¡construyámoslo!
Aplicación
Configuración de Couchbase Capella
Registrarse y probar Couchbase Capella es gratuito y, si aún no lo ha hecho, puede hacerlo accediendo a nube.couchbase.com y creando una cuenta con tus credenciales de GitHub o Google, o creando una cuenta nueva con una combinación de dirección de correo electrónico y contraseña.
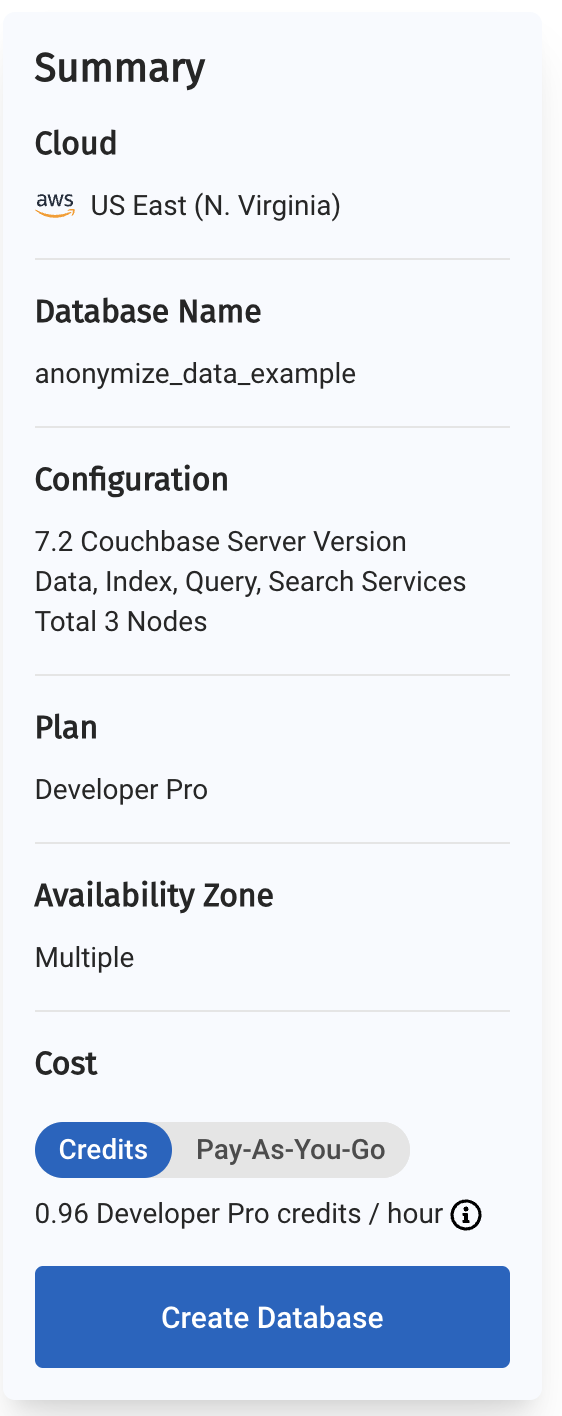 Una vez que lo haya hecho, desde su panel de control de Capella, creará su primera base de datos. Para los fines de este tutorial, vamos a llamarla anonimizar_datos_ejemplo.
Una vez que lo haya hecho, desde su panel de control de Capella, creará su primera base de datos. Para los fines de este tutorial, vamos a llamarla anonimizar_datos_ejemplo.
El resumen de su nueva base de datos se presentará en la parte izquierda del panel de control. Capella es multi-nube y puede trabajar con AWS, Google Cloud o Azure. En este ejemplo, se desplegará en AWS.
Una vez creada la base de datos, es necesario crear un archivo cubo. A cubo en Couchbase es el contenedor donde se almacenan los datos. Cada elemento de datos, conocido como documentose guarda en JSON, lo que hace que su sintaxis resulte familiar a la mayoría de los desarrolladores. Puedes nombrar tu cubo como quieras. Sin embargo, para los propósitos de este tutorial, vamos a llamar a este cubo datos_anonimizados_ejemplo.
Ahora que has creado tanto tu base de datos como tu bucket, estás listo para crear tus credenciales de acceso a la base de datos y obtener tu URL de conexión que usarás en tu función Lambda.
Navegue hasta el Conectar en el cuadro de mandos de Capella y tome nota de la sección Cadena de conexión.
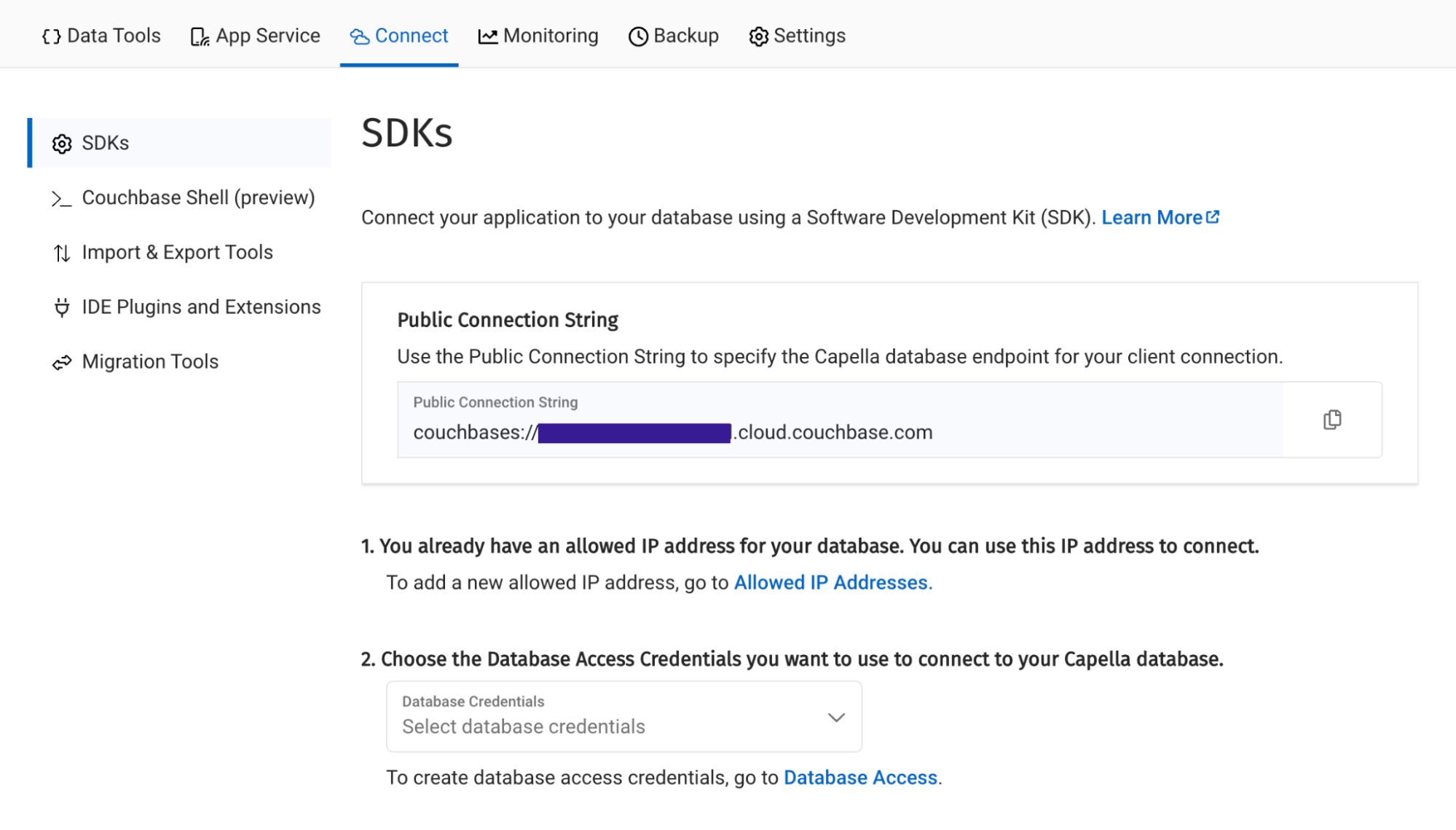
A continuación, haga clic en el botón Acceso a bases de datos en la sección dos. En esa sección, creará credenciales (un nombre de usuario y una contraseña) que su función Lambda utilizará para autenticarse con la base de datos. Puedes limitar las credenciales al bucket específico que has creado o darle permiso para todos los buckets y bases de datos de tu cuenta. En cualquier caso, debes asegurarte de que tiene acceso de lectura y escritura.
En este punto, ya estás listo para crear la función Lambda que se invocará cada vez que el servicio de cola reciba un mensaje.
Creación de la función lambda
Cada aplicación tendrá diferente IIP que pueda recoger, y dependiendo de las localidades en las que la aplicación esté operando, también puede tener diferentes requisitos de lo que debe eliminar antes de guardar los datos. En este ejemplo, eliminaremos la dirección IP y el apellido de cada mensaje antes de enviarlo a Couchbase.
La función para limpiar los datos es bastante sencilla:
|
1 2 3 4 5 |
function anonymizeData(data) { data.user.last_name = ''; delete data.user.ip_address; return data; } |
Esta función, anonimizarDatosse invocará en el manipulador del código. Si no está familiarizado con un manipulador es utilizada por AWS Lambda para procesar los mensajes entrantes de la cola SQS, transformar los datos y almacenarlos en Couchbase. Tu código ejecutable principal debe comenzar con un exports.handler.
En manipulador obtiene las credenciales de Couchbase y la cadena de conexión de las variables de entorno establecidas en la configuración de la función Lambda. Puedes encontrar instrucciones detalladas sobre la configuración de variables de entorno para una función Lambda en la sección Documentación de AWS. A continuación, la función analiza el mensaje recibido de SQS y llama a la función anonimizarDatos en él. Por último upserts los datos en el bucket de Couchbase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
exports.handler = async (event) => { console.log('Starting Lambda function'); if (!event.Records || !Array.isArray(event.Records)) { throw new TypeError('event.Records is not iterable'); } const connectionString = process.env.COUCHBASE_CONNECTION_STRING; const username = process.env.COUCHBASE_USERNAME; const password = process.env.COUCHBASE_PASSWORD; const bucketName = process.env.COUCHBASE_BUCKET_NAME; try { const cluster = await couchbase.connect(connectionString, { username: username, password: password }); console.log('Connected to Couchbase cluster'); const bucket = cluster.bucket(bucketName); const collection = bucket.defaultCollection(); for (const record of event.Records) { console.log('Processing record:', record); const payload = JSON.parse(record.body); const transformedData = anonymizeData(payload); console.log('Transformed data:', transformedData); await collection.upsert(transformedData.record_id, transformedData); console.log('Data upserted:', transformedData.record_id); } } catch (error) { console.error('Error during processing:', error); throw error; } }; |
Para configurar la función Lambda utilizando la CLI de AWS, necesitas crear una nueva función Lambda y especificar el rol IAM y el manejador necesarios. A continuación te mostramos cómo puedes hacerlo:
|
1 2 3 4 |
aws lambda create-function --function-name AnonymizeDataExampleFunction \ --package-type Image \ --code ImageUri=<your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest \ --role arn:aws:iam::<your-account-id>:role/<your-lambda-execution-role> |
Asegúrese de sustituir <your-account-id>, <your-region>y <your-lambda-execution-role> con tu ID de cuenta de AWS real, la región y el ARN del rol de IAM que creaste para la función de Lambda. Este comando configura la función de Lambda para utilizar la imagen de Docker que publicará en AWS ECR.
La función Lambda ya está lista para empaquetarse en una imagen Docker y publicarse en el servicio ECR de AWS.
Despliegue de la imagen Docker en ECR
Para implementar la imagen de Docker en AWS ECR, comenzamos por crear la imagen de Docker para la plataforma linux/amd64. Esto asegura la compatibilidad con la arquitectura x86_64 de nuestra función Lambda. Utilizamos un Dockerfile que instala las herramientas y dependencias necesarias, establece el directorio de trabajo, copia los archivos necesarios, instala las dependencias y copia el código de la función Lambda. La página Dockerfile también especifica el comando para ejecutar la función Lambda.
Aquí está el Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
FROM public.ecr.aws/lambda/nodejs:18 # Install necessary tools and dependencies RUN yum -y install gcc-c++ tar gzip findutils # Set the working directory WORKDIR /var/task # Copy package.json and package-lock.json COPY package*.json ./ # Install dependencies RUN npm install # Copy the function code COPY index.js ./ # Command to run the Lambda function CMD [ "index.handler" ] |
Una vez que el Dockerfile está listo, construimos la imagen Docker con la plataforma especificada:
|
1 |
docker build --platform linux/amd64 -t anonymize_data_example_image . |
Después de construir la imagen, la etiquetamos adecuadamente para el repositorio ECR de AWS:
|
1 |
docker tag anonymize_data_example_image:latest <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Para enviar la imagen Docker a ECR, primero iniciamos sesión en el registro de ECR utilizando la CLI de AWS para obtener las credenciales de inicio de sesión:
|
1 |
aws ecr get-login-password --region <your-region> | docker login --username AWS --password-stdin <your-account-id>.dkr.ecr.<your-region>.amazonaws.com |
Con las credenciales en su lugar, empujamos la imagen Docker al repositorio ECR:
|
1 |
docker push <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Por último, actualizamos la función lambda denominada AnonymizeDataExampleFunction para utilizar la nueva imagen Docker de ECR. Esto implica especificar la URI de la imagen y asegurarse de que la función Lambda está configurada para ejecutar el código de la imagen Docker recién empujada:
|
1 |
aws lambda update-function-code --function-name AnonymizeDataExampleFunction --image-uri <your-account-id>.dkr.ecr.<your-region>.amazonaws.com/anonymize_data_example_image:latest |
Siguiendo estos pasos, la imagen de Docker se implementa correctamente en AWS ECR y la función de Lambda se actualiza para utilizar la nueva imagen, lo que permite a la aplicación desinfectar la información de identificación personal antes de almacenarla en Couchbase. Esta configuración garantiza que el procesamiento de datos cumple los requisitos de privacidad al tiempo que aprovecha la potencia de AWS y Couchbase.
Configuración del servicio SQS
Para facilitar el flujo de datos entre el remitente del mensaje y la función de Lambda, necesitamos configurar una cola de Amazon SQS. La cola de SQS actuará como un búfer que recibe y almacena mensajes hasta que la función de Lambda los procesa. A continuación se explica cómo configurar una cola SQS y convertirla en un activador de la función de Lambda mediante la CLI de AWS.
En primer lugar, cree una nueva cola SQS. Esta cola recibirá mensajes con datos de usuario del remitente del mensaje, que es la aplicación.
|
1 |
aws sqs create-queue --queue-name AnonymizeDataExampleQueue |
Después de crear la cola, recibirá una URL para la cola. Esta URL es necesaria para enviar mensajes a la cola y configurarla como activador de la función Lambda.
A continuación, necesitamos obtener el ARN de la cola SQS, que es necesario para configurar permisos y disparadores. Utilice el siguiente comando para recuperar el ARN:
|
1 |
aws sqs get-queue-attributes --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --attribute-names QueueArn |
Sustituir <your-region> y <your-account-id> con su región AWS real y su ID de cuenta.
El resultado incluirá ColaArnque se parece a esto:
|
1 2 3 4 5 |
{ "Attributes": { "QueueArn": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } } |
Ahora, tenemos que conceder a la función Lambda permiso para leer mensajes de la cola SQS. Crea un archivo de política llamado lambda-sqs-policy.json con el siguiente contenido:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sqs:ReceiveMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:DeleteMessage", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" }, { "Effect": "Allow", "Action": "sqs:GetQueueAttributes", "Resource": "arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue" } ] } |
Aplique esta política al rol de ejecución Lambda:
|
1 |
aws iam put-role-policy --role-name <your-lambda-execution-role> --policy-name LambdaSQSPolicy --policy-document file://lambda-sqs-policy.json |
A continuación, añada la cola SQS como activador de la función Lambda:
|
1 |
aws lambda create-event-source-mapping --function-name AnonymizeDataExampleFunction --batch-size 10 --event-source-arn arn:aws:sqs:<your-region>:<your-account-id>:AnonymizeDataExampleQueue |
Este comando configura la función Lambda para que se active cuando lleguen mensajes a la cola SQS.
Ahora, su función Lambda está configurada para recibir cada mensaje enviado al servicio de cola. El flujo de trabajo está completo. Esta configuración garantiza una gestión eficiente de los datos de los usuarios al tiempo que mantiene el cumplimiento de los requisitos de privacidad.
Probar la aplicación localmente
Para asegurarse de que todo funciona como se espera, puede probar el flujo de trabajo enviando directamente un mensaje a la cola. Desde la línea de comandos ejecute lo siguiente:
|
1 |
aws sqs send-message --queue-url https://sqs.<your-region>.amazonaws.com/<your-account-id>/AnonymizeDataExampleQueue --message-body "{\"record_id\": \"purchase_002\", \"item\": \"item_1\", \"user\": {\"first_name\": \"John\", \"last_name\": \"Doe\", \"ip_address\": \"192.168.1.1\"}, \"timestamp\": \"2024-07-01T12:34:56Z\"}" |
El mensaje activará la función Lambda, que a su vez añadirá los datos a tu bucket de Couchbase después de desinfectarlos. Puede ver los datos de muestra que envió en el mensaje iniciando sesión en el panel de Capella o en su archivo VSCode o Jetbrains IDE directamente usando su respectiva extensión de Couchbase.
Conclusión
El trabajo de construir, desplegar y mantener cualquier aplicación moderna hoy en día es una tarea enorme. En la medida de lo posible, las partes de esa tarea que no están directamente relacionadas con la actividad principal de la aplicación deben simplificarse y abstraerse para reducir la carga cognitiva de los ingenieros, los SRE y todos los demás implicados. La normativa sobre privacidad es un elemento importante que debe cumplirse estrictamente y que no debe causar grandes quebraderos de cabeza ni aumentar la carga de trabajo.
La creación de un flujo de trabajo plug and play automatizado que pueda ubicarse fácilmente entre cualquier aplicación que interactúe con información de identificación personal y la base de datos en la que se almacenan los datos aliviará significativamente la carga cognitiva, reducirá la carga y agilizará el proceso de desarrollo. Con el aprovechamiento conjunto de AWS y Couchbase, puede hacerlo posible para sus necesidades de saneamiento de datos en tiempo real, garantizando así tanto la integridad del usuario como la productividad de ingeniería.
