
In the last six months alone, we’ve seen data centers physically burned and global identity layers vanish. There are more threats than ever, and yet the expectation of “five nines” (99.999%) availability remains.
When your database serves as the persistent system of record, its availability is central to your entire application ecosystem. If the database fails, the ripple effect can be devastating for customer experience, revenue, internal productivity, brand reputation, and can even lead to financial penalties or life-critical failures in medical systems.
This situation begs the crucial question: How do you make sure you achieve your business continuity goals when systems are inherently prone to failure due to extreme complexity and human error? It’s not only natural disasters such as earthquake and floods that you need to plan for but also man-made threats, including acts of warfare. As data centers evolve into the central nervous systems of the state and the market, they are no longer collateral damage – they have become primary targets in the anatomy of modern warfare.
Couchbase anticipated these profound challenges from the beginning, and it’s embedded in our name: “Couch” in Couchbase stands for “cluster of unreliable commodity hardware.” This core philosophy has driven us to engineer the unmatched resiliency for mission-critical applications.
This blog post outlines our strategic point of view on deploying Couchbase for maximum resilience, covering high availability, disaster recovery, backups, and multi-region cloud strategies.
Defining Your Resilience Goals: RPO and RTO
Before architecting a solution for business continuity, you must define what recovery actually looks like for your business in a disaster scenario. This is measured by two primary metrics:
- Recovery Point Objective (RPO): The maximum acceptable data loss (measured backward in time from the point of failure).
- Recovery Time Objective (RTO): The maximum acceptable service downtime.
While the ideal RPO/RTO is zero, achieving near-zero requires a careful balance between these requirements and implementation cost. Couchbase is engineered to deliver near-zero RPO/RTO, however, a sophisticated architecture investment is table stakes.
The Three Pillars of Service Outage Mitigation
To have comprehensive protection against outages in the case of disaster, we recommend a defense-in-depth approach using three core Couchbase technologies:
- Intra-Cluster Resilience (Clustering): Deploying a multi-node cluster across a group of separate physical data centers (or availability zones (AZs) in a cloud environment) eliminates any single point of failure within a local environment. Couchbase includes rack-zone awareness as a built-in feature that groups nodes into logical Server Groups that correspond to physical racks or AZs.
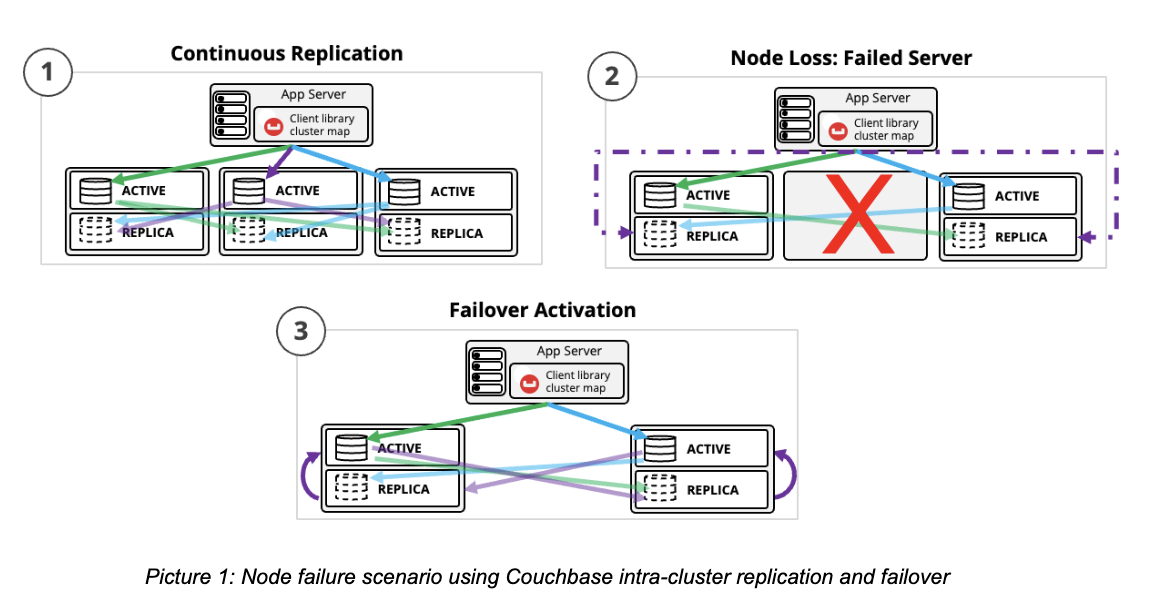
- Cross-Region Resilience With Cross Data Center Replication (XDCR): XDCR is Couchbase’s high performance memory-to-memory replication technology that enables replication (uni or bidirectional) of data across different clusters in different geographies. XDCR is what extends your application’s resilience far beyond a single cloud region.
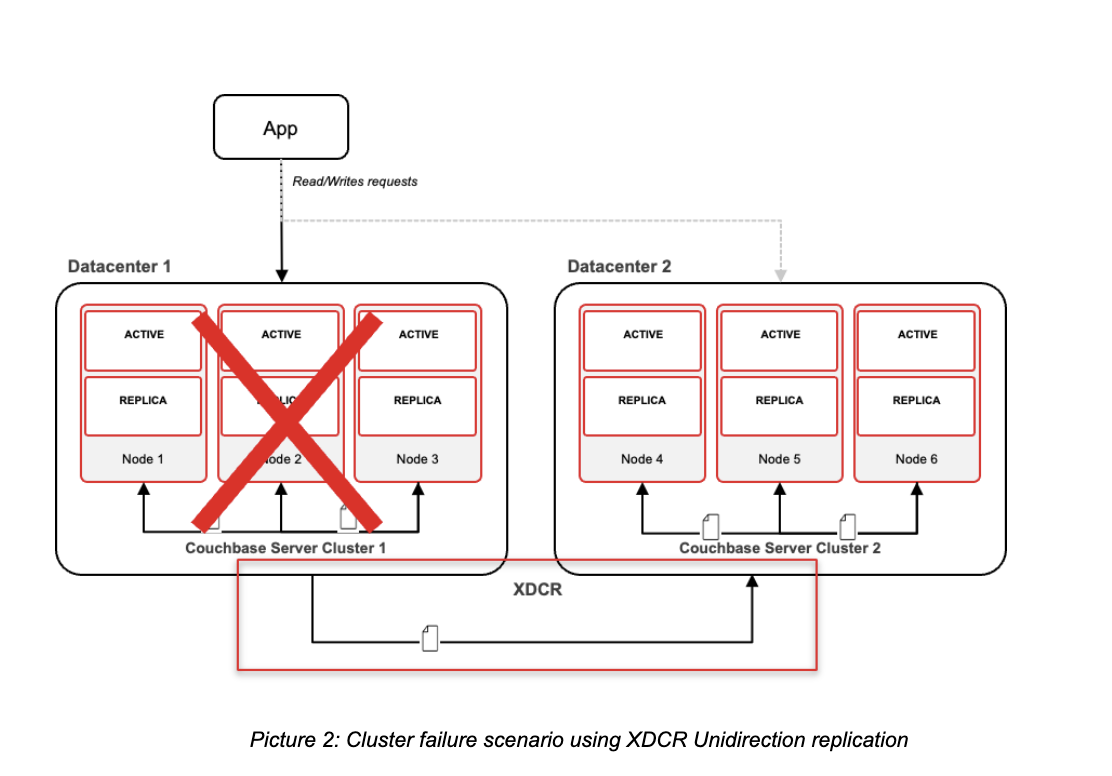
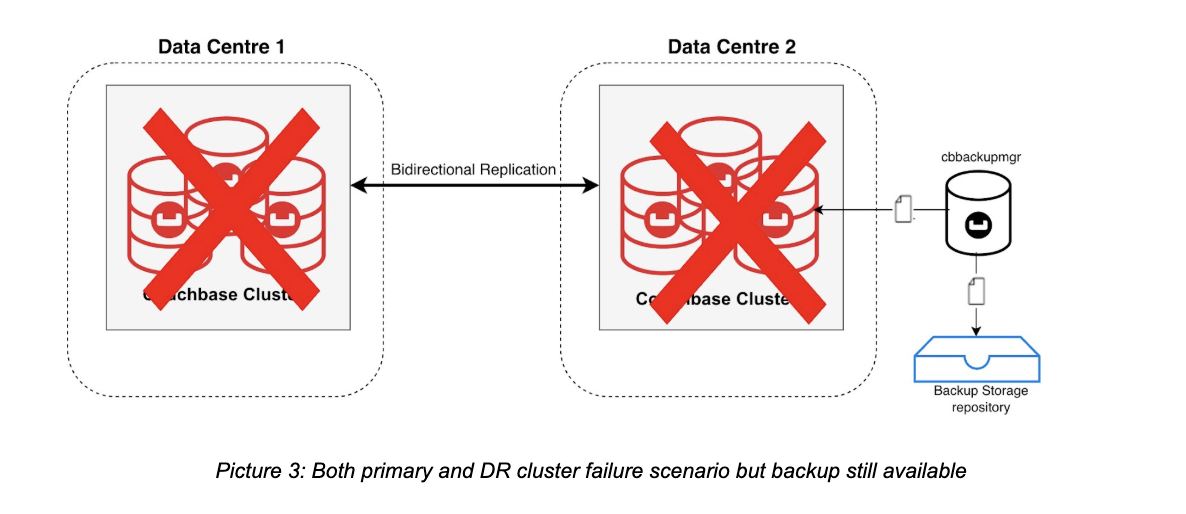
- The Ultimate Safety Net With Backups: Backups provides a final safety net to recover from catastrophic data corruption or incidents where live replication might have inadvertently propagated an error. Couchbase offers the cbbackupmgr as its bucket backup tool that can be installed separately for taking full and incremental backup of a cluster. For better automation, Couchbase also offers it as a Backup Service that can be deployed as part of the cluster. Couchbase’s fully-managed service, Capella, provides the option of full cluster backup.
Cross-Region High Availability Through XDCR Topologies
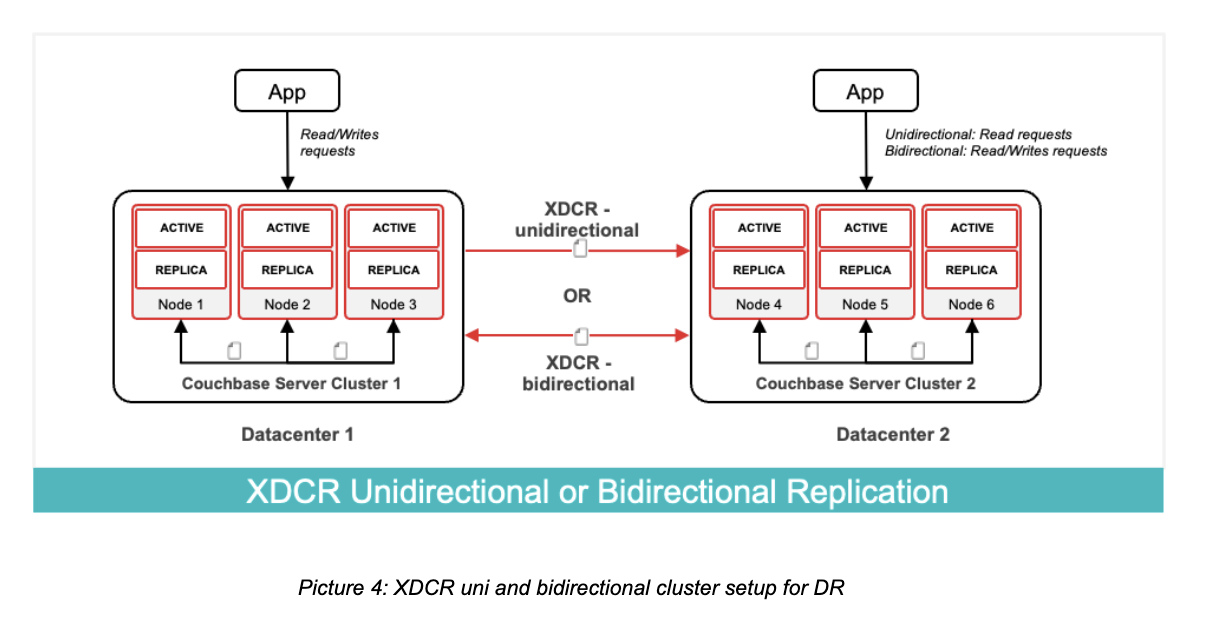
XDCR is the engine behind Couchbase’s multi-region resilience. It is a memory-to-memory, asynchronous replication technology that operates at the speed of the network. This is what takes resiliency beyond a single geography (cloud region) in Couchbase and can support both Active-Active and hot standby configurations.
Couchbase offers the same integrated architecture (XDCR) whether you run it on your own hardware, in a private cloud, or as a managed service. Furthermore, this also works with multiple clusters in different topologies such as ring, mesh, and hub-and-spoke.
Active-Active (Bidirectional)
This configuration is ideal for globally distributed applications that demand low latency and true load balancing, allowing multiple clusters to handle both read and write traffic simultaneously.
- Conflict Resolution: Since writes can happen at any site, Couchbase provides two mechanisms to ensure conflicts resolve: the most updates win (based on Revision ID) or Last Write Wins (timestamp-based using Hybrid Logical Clocks).
Hot Standby (Unidirectional)
This is the standard for a robust Disaster Recovery (DR) plan, where a primary cluster replicates data to a dedicated DR cluster.
- Pristine Copy: It ensures the DR site remains an exact replica and is ready to take traffic if the primary cluster is down for some reason. Unidirectional flow ensures that the DR cluster doesn’t accidentally send updates back to the primary during a localized issue.
- Safe Failover: Couchbase intelligently manages time skews and replication latency to ensure that when you redirect traffic to a new region, in-flight mutations are received.
Multi-Region Support and Cloud Deployment
Even the largest cloud provider regions are vulnerable to outages, so for enterprises deploying in the cloud (self-managed or Couchbase Capella), resilience should consider geographic separation to survive regional outages. This is where XDCR provides a few more advantages.
- Infrastructure Agnostic: XDCR operates flawlessly across on-prem, public, and hybrid clouds. This means you don’t have to choose between different options to deploy your database and it allows for seamless migration between different deployments.
- Bandwidth Optimization: To manage cloud costs and performance, Couchbase offers Data Compression (using Snappy) and Network Bandwidth Throttling. This ensures replication doesn’t saturate your network or blow your budget.
- Kubernetes Integration: The Couchbase Autonomous Operator can automate the recovery of clusters across regions, using XDCR to maintain consistency even as your containerized infrastructure scales or moves.
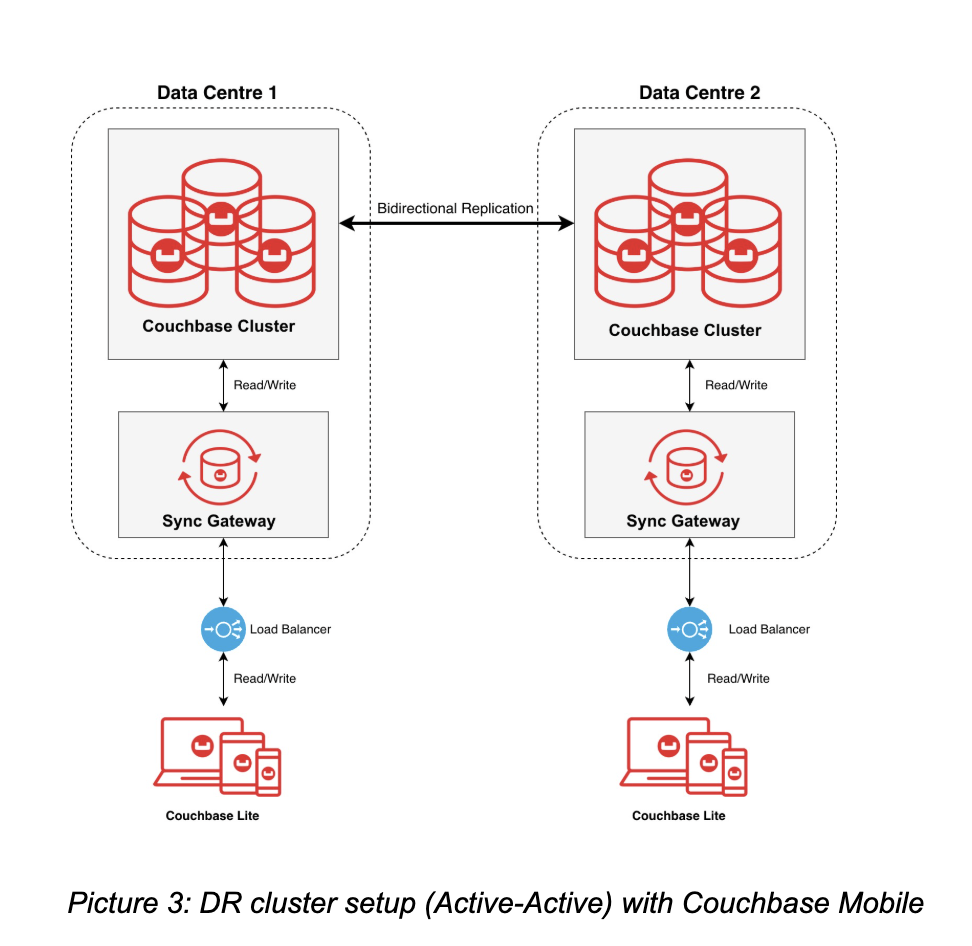
Resilience at the Edge: Mobile Considerations
If your mission-critical app has a mobile component, resilience must extend to the device itself. Couchbase Mobile enables offline-first applications and has two main components:
- Couchbase Lite: An embedded database that runs locally on the device, providing CRUD and search capabilities without requiring a network connection.
- Sync Gateway: Manages the secure synchronization and conflict resolution of data between the edge and the core database.
Edge DR: With its release last year, Couchbase provides high availability and true multi-region mobile resilience even with Active-Active cluster setups. This means both clusters can process reads and writes from mobile clients simultaneously, delivering:
- Zero-Downtime DR: Since both clusters can be active, a failure in one region simply means configuring the Load Balancer to direct all traffic to the other without the need to reconfigure Sync Gateway or XDCR in the heat of a crisis.
- Unified Conflict Resolution: These deployments leverage advanced Version Vectors, ensuring that mobile and server updates converge consistently across both active clusters.
Backup and Restore for Ultimate Resilience
To further strengthen your resilience posture and support your business continuity planning, it is essential to integrate Backup and Restore as the third pillar of your strategy. While clustering provides local availability and XDCR handles regional failover, backups are your ultimate defense against catastrophic data loss, such as accidental deletions or widespread data corruption.
To meet demanding SLAs, you must align your backup strategy with your RPO and RTO requirements:
- Periodic Full and Incremental Backups: Start with a full backup of your data, followed by frequent incremental backups to capture only the changes (mutations). This approach minimizes the storage footprint while keeping your RPO low.
- Offsite Cross-Region Storage: Never store your backups on the same infrastructure as your live clusters. For cloud deployments, leverage cross-region object storage to ensure that even a total cloud region failure does not destroy your recovery data.
- Validation and Testing: A backup is only as good as your ability to restore it. Regularly test your restore procedures to ensure you can meet your RTO during a real crisis.
The Couchbase cbbackupmgr tool is key to backing up and restoring your bucket data. It offers flexibility by allowing you to store backups in a repository of your choice, and enhances security with the option to encrypt those backups. To make it easier to create/maintain backups, you can deploy Couchbase Backup Service in your cluster on a separate node. The backup service uses the same cbbackupmgr tool under the hood.
Capella goes even further by offering these functionalities as part of the service with just a few clicks of button – without requiring the Backup Service or cbbbackupmgr. On top of that, Capella also offers capabilities to back up and restore an entire cluster and all of its buckets in a single backup using the underlying cloud provider’s snapshot technologies. You can take incremental storage snapshots for any backup after your first cluster backup, and the entire cluster backup makes the whole process of backup and restore very quick.
Couchbase is working to further enhance backup capabilities to ensure Point-in-Time Recovery (PITR) and immutability for greater peace of mind. PITR is already available in Developer Preview.
Conclusion: A Multi-Layered Resilience With Couchbase
Resilience is not a bolt-on feature. It must be designed with your application architecture. It is far better to establish a robust strategy during the initial architecture phase than to revisit it after a service outage has already impacted your brand.
True resilience for mission-critical applications requires the seamless integration of:
- Clustering (for local failover protection)
- XDCR (for regional failover protection)
- Backups (for data integrity protection)
By defining clear SLAs and strategically utilizing these three powerful tools, you ensure your business can withstand anything from a single node failure to a global regional outage.
Deixe um comentário
Você precisa fazer o login para publicar um comentário.