Cormac Hogan é diretor e tecnólogo-chefe no escritório do CTO na unidade de negócios de armazenamento e disponibilidade (SABU) da VMware.

Biografia: Entrei na VMware em abril de 2005 e, anteriormente, ocupei cargos nas organizações de engenharia, marketing técnico e suporte técnico da VMware. Escrevi vários white papers relacionados a armazenamento e fiz várias apresentações sobre práticas recomendadas de armazenamento e recursos de armazenamento do vSphere. Também sou coautor dos livros "Essential Virtual SAN" e "vSAN 6.7 Deep Dive".
Uma primeira olhada no Operador Autônomo do Couchbase
Algumas semanas atrás, Dei uma olhada no Heptio Velero, anteriormente conhecido como Ark. O Velero oferece recursos de backup e restauração para aplicativos nativos da nuvem. Durante essa pesquisa, usei um banco de dados Couchbase como meu aplicativo de escolha para backup/restauração. Depois de falar com a equipe do Couchbase sobre essa postagem no blog, eles recomendaram fortemente que eu experimentasse o novo Couchbase Autonomous Operator em vez do método StatefulSet que eu estava usando para o aplicativo. O Couchbase fala sobre as vantagens da abordagem do operador em relação ao StatefulSets aqui.
Agora, embora o Couchbase forneça etapas sobre como implantar o Couchbase com seu operador, ele o cria no namespace padrão do K8s. No meu teste, quero colocar o Couchbase em seu próprio namespace. As etapas fornecidas aqui servem para que você comece a usar o novo Couchbase Operator, executado na infraestrutura do vSphere e do vSAN, em seu próprio namespace do Kubernetes. Também falo sobre alguns problemas com a ferramenta de geração de carga incluída, chamada pillowfight.
O Couchbase fornece instruções prescritivas sobre como começar a usar sua operadora aqui. Ele inclui todos os arquivos de configuração necessários. Algumas informações sobre o operador:
- Quando carregado, ele faz o download da imagem do Operator Docker, conforme especificado no operator.yaml arquivo. Ele usa uma construção de implantação para que possa reiniciar se o pod em que está sendo executado morrer.
- Ele cria a definição de recurso personalizado (CRD) do CouchbaseCluster
- Ele começa a escutar os eventos do CouchbaseCluster.
Fiz algumas modificações para permitir que o Couchbase seja executado em seu próprio namespace:
- Primeiramente, criei um novo namespace (obviamente) chamado couchbase.
- Quando a função de cluster foi criada, criei a conta de serviço no novo namespace do couchbase e, em seguida, atribuí a função de cluster a essa conta de serviço usando uma associação de função de cluster.
- Modifiquei o operator.yaml para incluir um arquivo metadata.namespace=couchbase para que ela se aplique ao namespace do couchbase
Ao monitorar os logs do pod do operador do couchbase, podemos observar as seguintes mensagens de inicialização:
|
1 2 3 4 5 6 7 8 9 10 |
$ kubectl logs couchbase-operator-6fcfbd8599-zqsh2 -n couchbase time="2019-03-20T09:27:41Z" level=info msg="couchbase-operator v1.1.0 (release)" module=main time="2019-03-20T09:27:41Z" level=info msg="Obtaining resource lock" module=main time="2019-03-20T09:27:41Z" level=info msg="Starting event recorder" module=main time="2019-03-20T09:27:41Z" level=info msg="Attempting to be elected the couchbase-operator leader" module=main time="2019-03-20T09:27:41Z" level=info msg="Event(v1.ObjectReference{Kind:\"Endpoints\", Namespace:\"couchbase\", Name:\"couchbase-operator\", UID:\"68fece18-4af2-11e9-be9b-005056a24d92\", APIVersion:\"v1\", ResourceVersion:\"1596774\", FieldPath:\"\"}): type: 'Normal' reason: 'LeaderElection' couchbase-operator-6fcfbd8599-zqsh2 became leader" module=event_recorder time="2019-03-20T09:27:41Z" level=info msg="I'm the leader, attempt to start the operator" module=main time="2019-03-20T09:27:41Z" level=info msg="Creating the couchbase-operator controller" module=main time="2019-03-20T09:27:46Z" level=info msg="CRD initialized, listening for events..." module=controller time="2019-03-20T09:27:46Z" level=info msg="starting couchbaseclusters controller" |
- Eu o coloquei no namespace do couchbase com o metadados.namespace entrada
- Eu defini spec.disableBucketManagement para true, o que me permite fazer alterações nos buckets via UI/CLI (caso contrário, tenho que fazer todas as alterações por meio de edições no arquivo YAML)
- Adicionei Persistent Volumes para as montagens padrão e de dados (tive que criar uma nova StorageClass para o volumeClaimTemplate a ser usado para isso - veja abaixo)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
apiVersion: couchbase.com/v1 kind: CouchbaseCluster metadata: name: cb-example namespace: couchbase spec: securityContext: fsGroup: 1000 baseImage: couchbase/server version: enterprise-5.5.2 authSecret: cb-example-auth exposeAdminConsole: true disableBucketManagement: true adminConsoleServices: - data cluster: dataServiceMemoryQuota: 256 indexServiceMemoryQuota: 256 searchServiceMemoryQuota: 256 eventingServiceMemoryQuota: 256 analyticsServiceMemoryQuota: 1024 indexStorageSetting: memory_optimized autoFailoverTimeout: 120 autoFailoverMaxCount: 3 autoFailoverOnDataDiskIssues: true autoFailoverOnDataDiskIssuesTimePeriod: 120 autoFailoverServerGroup: false buckets: - name: default type: couchbase memoryQuota: 128 replicas: 1 ioPriority: high evictionPolicy: fullEviction conflictResolution: seqno enableFlush: true enableIndexReplica: false servers: - size: 3 name: all_services services: - index - query - search - eventing - analytics - <strong>data pod: volumeMounts: default: couchbase data: couchbase volumeClaimTemplates: - metadata: name: couchbase spec: storageClassName: "couchbasesc" resources: requests: storage: 1Gi </strong> |
Estou ignorando os requisitos de autenticação e de usuário, que estão todos documentados no site do Couchbase. No entanto, depois que o aplicativo tiver sido implantado, você poderá ver o seguinte nos logs do pod do operador do Couchbase:
|
1 2 3 4 5 6 7 8 9 10 |
$ kubectl logs couchbase-operator-6fcfbd8599-zqsh2 -n couchbase . . time="2019-03-20T09:48:34Z" level=info msg="Watching new cluster" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Janitor process starting" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Setting up client for operator communication with the cluster" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Cluster does not exist so the operator is attempting to create it" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Creating headless service for data nodes" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Creating NodePort UI service (cb-example-ui) for data nodes" cluster-name=cb-example module=cluster time="2019-03-20T09:48:34Z" level=info msg="Creating a pod (cb-example-0000) running Couchbase enterprise-5.5.2" cluster-name=cb-example module=cluster |
E se tudo for bem-sucedido, você poderá consultar os pods, os volumes persistentes e os serviços à medida que forem inicializados.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ kubectl get po -n couchbase NAME READY STATUS RESTARTS AGE cb-example-0000 1/1 Running 0 7m8s cb-example-0001 1/1 Running 0 6m7s cb-example-0002 1/1 Running 0 5m14s couchbase-operator-6fcfbd8599-zqsh2 1/1 Running 0 28m $ kubectl get pv -n couchbase NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-100e3c17-40e3-11e9-be9b-005056a24d92 10Gi RWO Delete Bound velero/minio-pv-claim-1 minio-sc 12d pvc-53c6962f-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0000-00-default couchbasesc 7m51s pvc-5b30f298-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0000-01-data couchbasesc 7m44s pvc-795bcf7b-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0001-00-default couchbasesc 6m51s pvc-7edc6a4d-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0001-01-data couchbasesc 6m43s pvc-97e9f6a9-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0002-00-data couchbasesc 6m2s pvc-9bcc3d4d-4af5-11e9-be9b-005056a24d92 1Gi RWO Delete Bound couchbase/pvc-couchbase-cb-example-0002-01-default couchbasesc 5m50s $ kubectl get svc -n couchbase NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE cb-example ClusterIP None 8091/TCP,18091/TCP 8m55s |
- Siga as etapas documentadas para configurar o couchbase ClusterRole
- Criar o namespace do couchbase - kubectl create ns couchbase
- Criar a conta de serviço do operador do couchbase no namespace do couchbase kubectl create serviceaccount couchbase-operator -namespace couchbase
- Criar o operador (modificado para o namespace do couchbase) - kubectl create -f operator.yaml
- Crie os segredos necessários (modificados para o namespac do couchbase) - kubectl create -f secret.yaml
- Crie o cluster do couchbase usando cbopctl - cbopctl create -f couchbase-cluster-sc.yaml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
apiVersion: batch/v1 kind: Job metadata: name: pillowfight namespace: couchbase spec: template: metadata: name: pillowfight spec: containers: - name: pillowfight image: couchbaseutils/pillowfight:v2.9.3 command: ["cbc-pillowfight", "-U", "couchbase://cb-example-0000.cb-example.couchbase.svc.cluster.local/default?select_bucket=true", "-I", "10000", "-B", "1000", "-c", "10", "-t", "1", "-P", "password"] restartPolicy: Never |
A única diferença para o cormac A sintaxe do comando é um pouco diferente:
|
1 2 3 4 5 6 7 8 9 |
$ kubectl get po -n couchbase NAME READY STATUS RESTARTS AGE cb-example-0000 1/1 Running 0 20m cb-example-0001 1/1 Running 0 19m cb-example-0002 1/1 Running 0 18m couchbase-operator-6fcfbd8599-ggv98 1/1 Running 0 24m create-user-dk6xg 0/1 Completed 0 89s pillowfight-fqvgp 0/1 Completed 0 70s pillowfightcormac-dmqnf 0/1 Completed 0 7s |
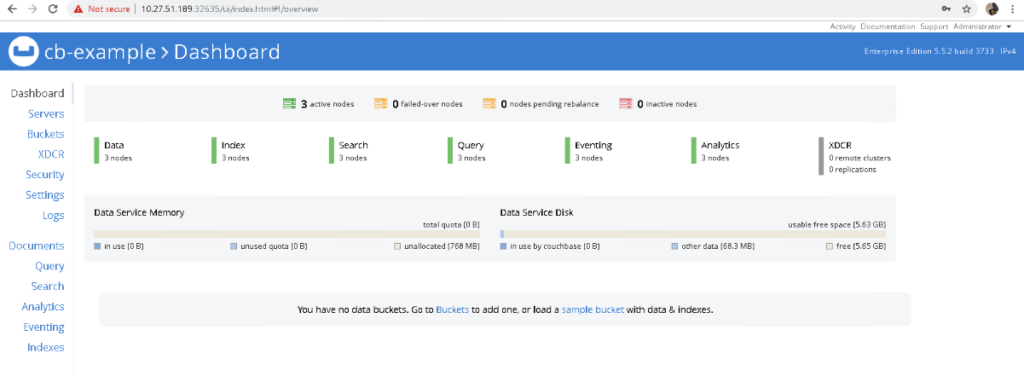
Mais importante ainda, se dermos uma olhada na interface do usuário do Couchbase, veremos que agora temos 1.000 itens em cada bucket:
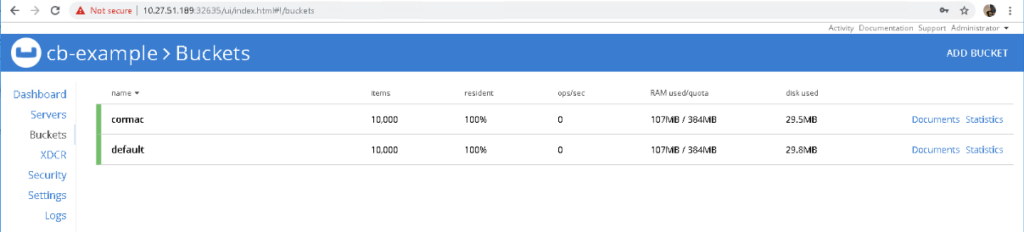
E é isso. Você está pronto e funcionando com seu operador do Couchbase. E para encerrar, isso foi provisionado em um cluster K8s sobre a infraestrutura VMware PKS, vSphere e vSAN. A propósito, o problema com o pillowfight foi relatado aqui (o problema foi resolvido).