Prolog
O Artigo anterior forneceu detalhes sobre como migrar um conjunto de dados do MongoDB para o Couchbase Server. Este artigo mostra como usar o SDK do Couchbase para acessar os dados por meio de um aplicativo de console Java. Os trechos de código mostram como se conectar ao cluster do Couchbase, realizar operações de chave/valor e executar pesquisas secundárias por meio de consultas N1QL lado a lado com o código correspondente para fazer o mesmo com o SDK Java do Mongo.
Todo o código deste blog está disponível no seguinte repositório Git: mongodb-to-couchbase.
Pré-requisitos
Um cluster do Couchbase contendo o conjunto de dados de acordo com os detalhes no Artigo anterior.
Criar um usuário de aplicativo
Antes que um cliente (aplicativo) possa se conectar ao cluster do Couchbase Server, é necessário definir um usuário do aplicativo que será usado para autenticação pelo cliente. Couchbase Controle de acesso baseado em função permite definir usuários e atribuir a eles as funções apropriadas. Use o console da Web para criar um usuário de aplicativo chamado mflix_client da seguinte forma.
Ir para o Segurança no console da Web e clique em ADICIONAR USUÁRIO:
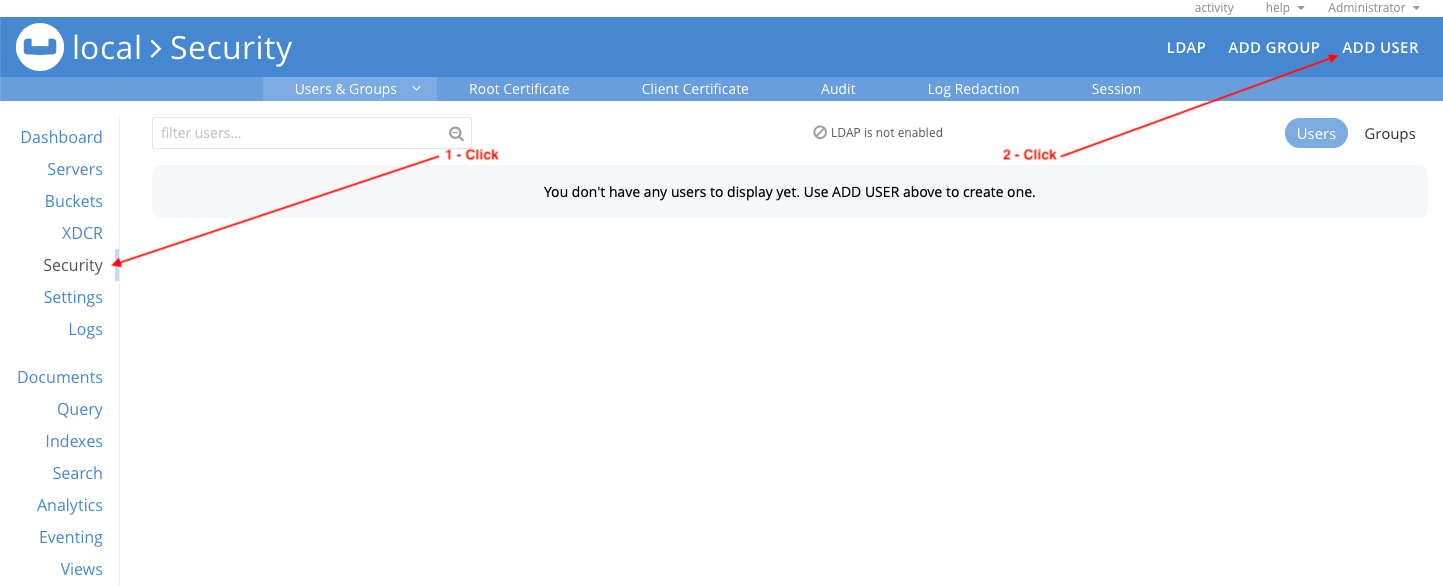
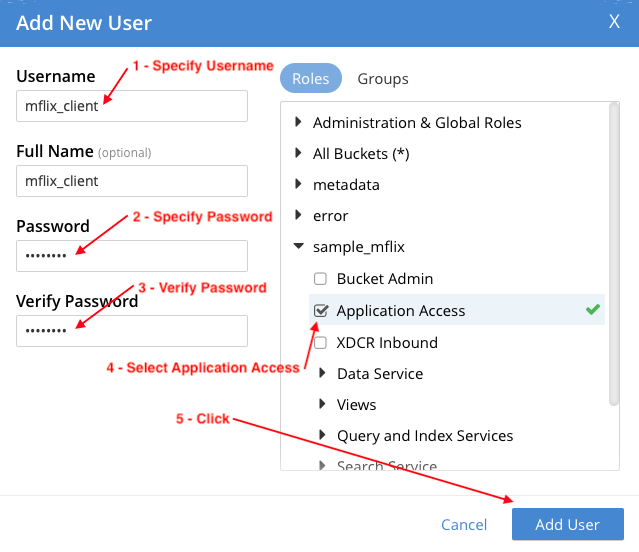
Configurar o mflix_client usuário da seguinte forma e clique em Adicionar usuário:
- Nome de usuário: mflix_client
- Senha: senha (ou qualquer senha de sua escolha).
- Verificar senha: o mesmo que Senha valor acima.
- Funções: Expandir o sample_mflix e selecione Acesso a aplicativos. Usuários com o Função de acesso a aplicativos têm acesso total de leitura e gravação a todos os dados no bucket sample_mflix. A função não permite acesso ao Console da Web do Couchbase: ela se destina a aplicativos, e não a usuários.
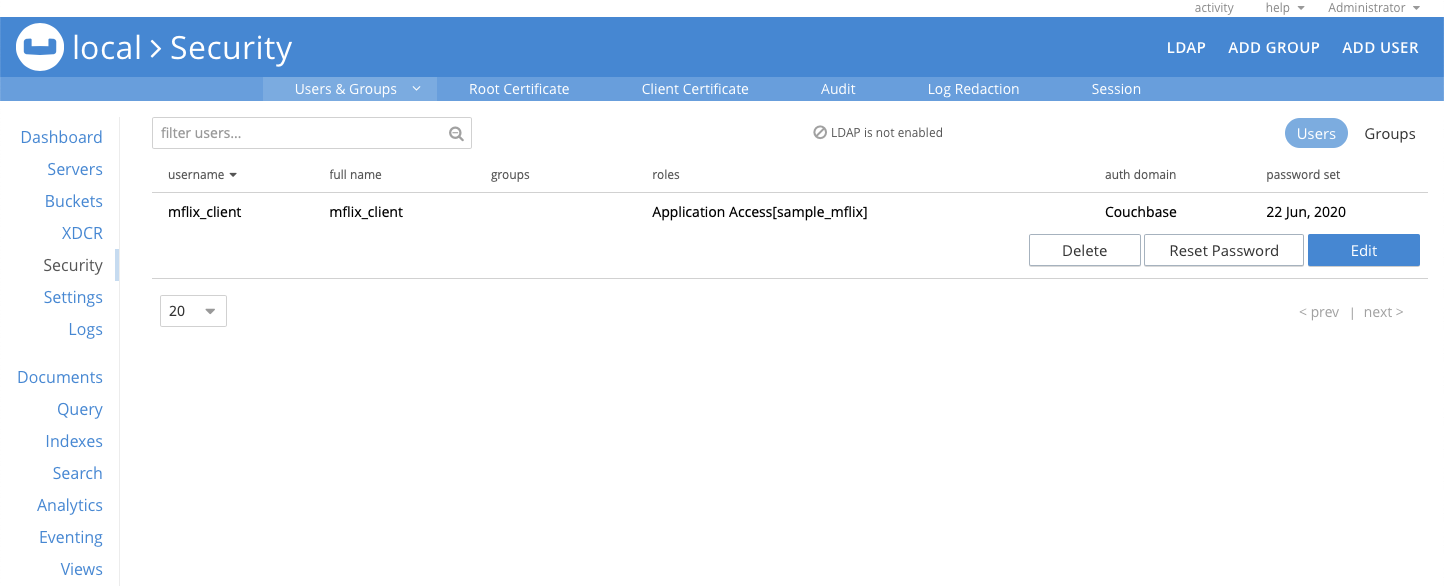
No Segurança você verá o novo usuário mflix_client:
Criar índices para consultas N1QL
Índices secundários no Couchbase Server suportam a execução eficiente de consultas (ou pesquisas secundárias) da mesma forma que os índices no MongoDB. Os exemplos de código neste artigo executam Consultas N1QL que usam dois índices que você criará ao executar as consultas N1QL. Vá para a seção Consulta no console da Web:
O primeiro índice está no atributo name de todos os documentos de comentários no bucket sample_mflix. Insira a seguinte instrução N1QL no arquivo Editor de consultas:
|
1 |
CREATE INDEX idx1 on sample_mflix(name) WHERE type="comment" |
Clique em Executar e, após alguns instantes, o criação de índices está completo:
O segundo índice está nos atributos year, imdb.rating e title de todos os documentos de filmes no bucket sample_mflix. Digite a seguinte instrução N1QL no arquivo Editor de consultas:
|
1 |
CREATE INDEX idx2 on sample_mflix(year, imdb.rating, title) WHERE type="movie" |
Clique em Executar e, após alguns instantes, a criação do índice estará concluída:
Ir para o Índices no console da Web para verificar se os índices idx1 & idx2 existem:
Converter chamadas de API do MongoDB em chamadas de API do Couchbase
O código de amostra deste artigo usa os SDKs Java do Couchbase e do MongoDB e é fornecido apenas como um exemplo de como usar algumas das APIs do SDK. Consulte os links a seguir para obter a documentação completa do SDK do Couchbase para seu idioma:
Conectar-se ao servidor Couchbase
Para acessar os recursos do cluster, os clientes devem autenticar passando as credenciais apropriadas para o Couchbase Server. O código de exemplo usa as credenciais de usuário do aplicativo mflix_client criadas acima para autenticação.
O exemplo de código a seguir se conecta ao cluster do Couchbase em execução no nó especificado, obtém uma referência ao bucket mflix_client e uma referência à coleção padrão nesse bucket.
Couchbase
|
1 2 3 |
Cluster cluster = Cluster.connect("127.0.0.1", "mflix_client", "password"); Bucket bucket = cluster.bucket("sample_mflix"); Collection collection = bucket.defaultCollection(); |
MongoDB
|
1 2 3 4 |
MongoClient mongoClient = MongoClients.create("mongodb+srv://<user>:<password>@<host>/<database> "); MongoDatabase mongoDatabase = mongoClient.getDatabase("sample_mflix"); MongoCollection<Document> comments = mongoDatabase.getCollection("comments"); MongoCollection<Document> movies = mongoDatabase.getCollection("movies"); |
Recuperar um documento por ID
Use o Coleção.get() método para recuperar documentos completos por ID. O exemplo de código a seguir recupera dois documentos da coleção padrão do bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 |
// get() will throw an exception if a document with the specified ID does not exist GetResult comment = collection.get("comment:5a9427648b0beebeb69579cc"); System.out.println(comment.contentAsObject()); GetResult movie = collection.get("movie:573a1390f29313caabcd4135"); System.out.println(movie.contentAsObject()); |
MongoDB
|
1 2 |
comments.find(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579cc"))); movies.find(Filters.eq("_id", new ObjectId("573a1390f29313caabcd4135"))); |
Inserir um novo documento
Use o Collection.insert() método para criar um novo documento com o ID e o conteúdo especificados, se ele ainda não existir. O exemplo de código a seguir insere esse documento na coleção padrão do bucket sample_mflix:
|
1 2 3 4 5 6 7 |
{ "name":"Anat Chase", "email":"anat_chase@fakegmail.com", "movie_id":"movie:573a1390f29313caabcd4135", "text":"This is Anat's review", "type":"comment" } |
Couchbase
|
1 2 3 4 5 6 7 8 9 |
JsonObject doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Anat's review") .put("type", "comment"); // insert() will throw an exception if a document with the specified ID already exists collection.insert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
Document doc = new Document("_id", new ObjectId("5a9427648b0beebeb69579c0")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Anat's review"); comments.insertOne(doc); |
Inserir vários documentos novos
Operações de loteamento permite que você utilize melhor a sua rede e acelere o seu aplicativo, aumentando o rendimento da rede e reduzindo a latência. As operações em lote funcionam da seguinte forma pipelining solicitações pela rede. Quando as solicitações são canalizadas, elas são enviadas em um grande grupo para o cluster. O cluster, por sua vez dutos respostas de volta para o cliente.
O exemplo de código a seguir usa essa abordagem para inserir dois novos documentos no bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Create two JSON documents List<Tuple2<String, JsonObject>> documents = new ArrayList<Tuple2<String, JsonObject>>(); doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd42e8") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c1", doc)); JsonObject doc2 = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4323") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c2", doc2)); // Insert the 2 documents in one batch, waiting until the last one is done. // insert() will throw an exception if a document with the specified ID already exists Flux .fromIterable(documents) .parallel().runOn(Schedulers.elastic()) .concatMap(doc3 -> reactiveCollection.insert(doc3.getT1(), doc3.getT2()) .onErrorResume(e -> Mono.error(new Exception(doc3.getT1(), e)))) .sequential().collectList().block(); |
MongoDB
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
List<Document> documents = new ArrayList<Document>(); Document doc1 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c1")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd42e8")) .append("text", "This is Anat's review"); documents.add(doc1); Document doc2 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c2")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4323")) .append("text", "This is Anat's review"); documents.add(doc2); comments.insertMany(documents); |
Atualizar um documento existente
Use o Collection.replace() método para atualizar um documento existente com o ID especificado somente se ele já existir. O Couchbase suporta operações de subdocumentos que pode ser usado para acessar eficientemente peças de documentos. As operações de subdocumentos podem ser mais rápidas e mais eficientes em termos de rede do que documento completo porque transmitem apenas as seções acessadas do documento pela rede. As operações de documento completo e subdocumento são atômicas, permitindo modificações seguras em documentos com controle de simultaneidade integrado.
O exemplo de código a seguir usa operações de subdocumento para atualizar o atributo de texto de um documento especificado.
Couchbase
|
1 2 3 4 5 |
// Update a document using the sub-document API to modify the specific attribute(s) // replace() will throw an exception if a document with the specified ID does not exist collection.mutateIn( "comment:5a9427648b0beebeb69579c0", Arrays.asList(replace("text", "This is not Anat's review"))); |
MongoDB
|
1 2 3 |
comments.updateOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), Updates.combine(Updates.set("text", ""))); |
Atualizar vários documentos
Além do acesso primário por meio de APIs de chave/valor, você também pode executar consultas N1QL por meio das APIs N1QL. N1QL é uma linguagem declarativa para consulta, transformação e manipulação de dados JSON - pense em SQL para JSON.
O exemplo de código a seguir executa uma consulta N1QL para atualizar os atributos de nome e e-mail de todos os documentos de comentários em que o nome é Anat Chase. Essa consulta usa a função idx1 criado acima.
Couchbase
|
1 2 3 4 5 6 |
// execute a N1QL UPDATE query via the query API String statement = "UPDATE sample_mflix " + "SET name='Anita Chase', email='anita_chase@fakegmail.com' " + "WHERE type='comment' AND name='Anat Chase'"; QueryResult updateResult = cluster.query(statement); |
MongoDB
|
1 2 3 4 5 |
comments.updateMany( Filters.eq("name", "Anat Chase"), Updates.combine( Updates.set("name", "Anita Chase"), Updates.set("email", "anita_chase@fakegmail.com"))); |
Atualizar ou inserir um documento
Use o Collection.upsert() método para inserir o documento, caso ele não exista, ou substituí-lo, caso exista. Se não existir um documento com o ID especificado, upsert() criará um novo documento. Se existir um documento com o ID especificado, upsert() atualizará o documento existente. O exemplo de código a seguir atualiza um documento existente no bucket sample_mflix.
Couchbase
|
1 2 3 4 5 6 7 8 9 |
doc = JsonObject.create() .put("name", "Mia Hannas") .put("email", "mia_hannas@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Mia's review") .put("type", "comment"); // upsert() will update the document if it exists or insert the document if it does not exist collection.upsert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
collection.replaceOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), new Document("name", "Mia Hannas") .append("email", "mia_hannas@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Mia's review"), new UpdateOptions().upsert(true)); |
Excluir um documento
Use o Collection.remove() método para remover um documento completo com o ID especificado. O exemplo de código a seguir exclui um documento existente do bucket sample_mflix.
Couchbase
|
1 2 |
// remove() will throw an exception if the document does not exist collection.remove("comment:5a9427648b0beebeb69579c0"); |
MongoDB
|
1 |
collection.deleteOne(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0"))); |
Excluir vários documentos
Você também pode usar consultas N1QL para excluir documentos. O exemplo de código a seguir executa uma consulta N1QL para excluir vários documentos do bucket sample_mflix. Todos os documentos de comentários em que o nome é Anita Chase serão excluídos. Essa consulta usa o parâmetro idx1 criado acima.
Couchbase
|
1 2 3 4 5 |
// execute a N1QL DELETE query via the query API String statement = "DELETE FROM sample_mflix " + "WHERE type='comment' AND name='Anita Chase'"; QueryResult deleteResult = cluster.query(statement); |
MongoDB
|
1 |
comments.deleteMany(Filters.eq("name", "Anita Chase")); |
Acesso a dados com N1QL
O N1QL também pode ser usado para realizar pesquisas secundárias de dados mais complicadas. O exemplo de código a seguir executa uma consulta N1QL de bloqueio para selecionar o título, o ano e o imdb.rating de todos os documentos de filmes em que o ano está entre 1970 e 1979, ordenados pelo imdb.rating. A consulta usa a função idx2 criado acima.
Semelhante a operações reativas de chave/valor em lote, consultas reativas e assíncronas deve ser usado para melhorar o desempenho.
Couchbase
|
1 2 3 4 5 6 7 8 |
// execute a N1QL SELECT query (blocking) via the query API String selectStatement = "SELECT title, year, imdb.rating FROM sample_mflix " + "WHERE type='movie' AND year BETWEEN 1970 AND 1979 ORDER BY imdb.rating DESC"; final QueryResult selectResult = cluster.query(selectStatement); for (JsonObject row : selectResult.rowsAsObject()) { System.out.println(row.toString()); } |
MongoDB
|
1 2 3 4 5 |
movies.find(Filters.and(Filters.gte("year", 1970), Filters.lte("year", 1979))) .sort(Sorts.descending("imdb.rating")) .projection(Projections.fields( Projections.include("title", "year", "imdb.rating"), Projections.excludeId())); |
O que vem a seguir
Explore os outros recursos do SDK do Couchbase, incluindo Análises e Pesquisa de texto completo. Aproveite nosso treinamento on-line gratuito, disponível em https://learn.couchbase.com para saber mais sobre o Couchbase.
Para obter informações detalhadas sobre as vantagens arquitetônicas do Couchbase Data Platform em relação ao MongoDB, consulte este documento: Couchbase: Melhor que o MongoDB em todos os sentidos.
Saiba por que outras empresas escolhem o Couchbase em vez do MongoDB: