프롤로그
그리고 이전 기사 에서 MongoDB 데이터 세트를 Couchbase Server로 마이그레이션하는 방법에 대한 자세한 내용을 제공했습니다. 이 문서에서는 Couchbase SDK를 사용하여 Java 콘솔 애플리케이션을 통해 데이터에 액세스하는 방법을 보여줍니다. 코드 스니펫은 Couchbase 클러스터에 연결하고, 키/값 연산을 수행하고, N1QL 쿼리를 통해 보조 조회를 실행하는 방법을 Mongo Java SDK에서 동일한 작업을 수행하는 해당 코드와 함께 나란히 보여 줍니다.
이 블로그의 모든 코드는 다음 Git 리포지토리에서 사용할 수 있습니다: 몽고DB-카우치베이스.
전제 조건
의 세부 정보에 따라 데이터 세트가 포함된 Couchbase 클러스터입니다. 이전 기사.
애플리케이션 사용자 만들기
클라이언트(애플리케이션)가 Couchbase Server 클러스터에 연결하려면 먼저 클라이언트에서 인증에 사용할 애플리케이션 사용자를 정의해야 합니다. Couchbase 역할 기반 액세스 제어 를 사용하면 사용자를 정의하고 적절한 역할을 할당할 수 있습니다. 웹 콘솔을 사용하여 다음과 같은 애플리케이션 사용자를 만듭니다. 엠플릭스_클라이언트 를 다음과 같이 설정합니다.
로 이동합니다. 보안 섹션에서 웹 콘솔의 사용자 추가:
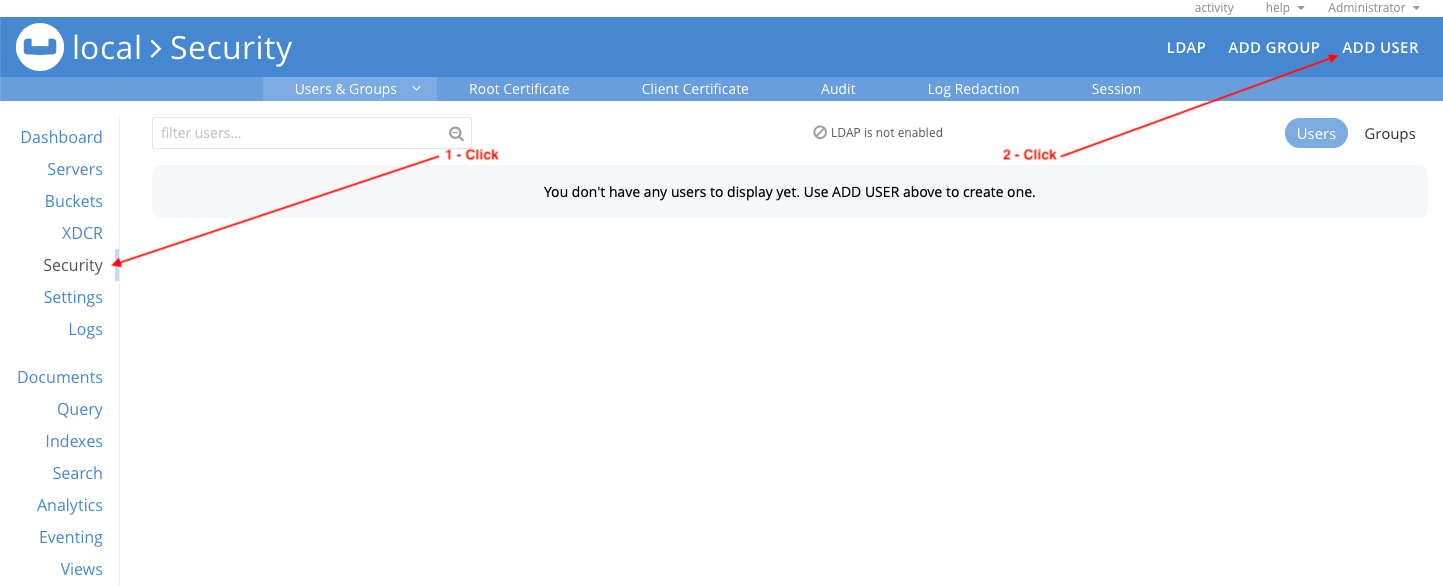
구성 엠플릭스_클라이언트 사용자를 다음과 같이 설정하고 사용자 추가:
- 사용자 이름: 엠플릭스_클라이언트
- 비밀번호비밀번호(또는 원하는 비밀번호)를 입력합니다.
- 비밀번호 확인다음과 동일 비밀번호 값을 설정합니다.
- 역할: 확장 sample_mflix 섹션에서 애플리케이션 액세스. . 애플리케이션 액세스 역할 샘플_mflix 버킷의 모든 데이터에 대한 전체 읽기 및 쓰기 권한을 갖습니다. 이 역할은 사용자가 아닌 애플리케이션을 위한 것으로, Couchbase 웹 콘솔에 대한 액세스는 허용하지 않습니다.
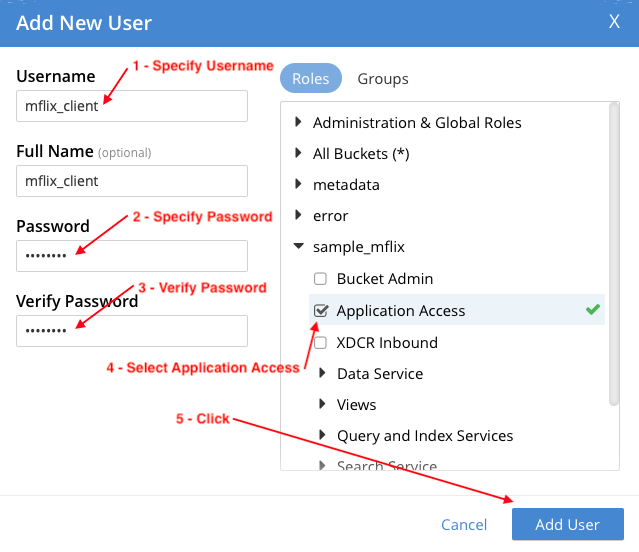
에서 보안 섹션에 새 mflix_client 사용자가 표시됩니다:
N1QL 쿼리에 대한 인덱스 생성
보조 색인 는 MongoDB의 인덱스처럼 쿼리(또는 보조 조회)의 효율적인 실행을 지원합니다. 이 문서의 코드 샘플은 다음을 실행합니다. N1QL 쿼리 두 개의 인덱스를 사용하는 N1QL 쿼리를 실행하여 생성할 수 있습니다. 인덱스의 쿼리 섹션으로 이동합니다:
첫 번째 인덱스는 sample_mflix 버킷에 있는 모든 댓글 문서의 이름 속성에 있습니다. 다음 N1QL 문을 쿼리 편집기:
|
1 |
CREATE INDEX idx1 on sample_mflix(name) WHERE type="comment" |
클릭 실행 그리고 잠시 후 인덱스 생성 가 완료되었습니다:
두 번째 인덱스는 sample_mflix 버킷에 있는 모든 영화 문서의 연도, imdb.rating, 제목 속성에 대한 인덱스입니다. 다음 N1QL 문을 쿼리 편집기:
|
1 |
CREATE INDEX idx2 on sample_mflix(year, imdb.rating, title) WHERE type="movie" |
클릭 실행 를 입력하면 잠시 후 인덱스 생성이 완료됩니다:
로 이동합니다. 색인 섹션에서 인덱스가 있는지 확인합니다. idx1 & idx2 존재합니다:
MongoDB API 호출을 Couchbase API 호출로 변환하기
이 문서의 샘플 코드는 Couchbase 및 MongoDB Java SDK를 사용하며 일부 SDK API를 사용하는 방법의 예시로만 제공됩니다. 해당 언어의 Couchbase SDK 설명서 전문은 다음 링크를 참조하세요:
카우치베이스 서버에 연결
클러스터 리소스에 액세스하려면 클라이언트는 다음을 수행해야 합니다. 인증 에 적절한 자격 증명을 전달하여 인증합니다. 샘플 코드는 위에서 생성한 mflix_client 애플리케이션 사용자 자격 증명을 사용하여 인증합니다.
다음 코드 샘플은 지정된 노드에서 실행 중인 Couchbase 클러스터에 연결하고, mflix_client 버킷에 대한 참조와 해당 버킷의 기본 컬렉션에 대한 참조를 가져옵니다.
카우치베이스
|
1 2 3 |
Cluster cluster = Cluster.connect("127.0.0.1", "mflix_client", "password"); Bucket bucket = cluster.bucket("sample_mflix"); Collection collection = bucket.defaultCollection(); |
MongoDB
|
1 2 3 4 |
MongoClient mongoClient = MongoClients.create("mongodb+srv://<user>:<password>@<host>/<database> "); MongoDatabase mongoDatabase = mongoClient.getDatabase("sample_mflix"); MongoCollection<Document> comments = mongoDatabase.getCollection("comments"); MongoCollection<Document> movies = mongoDatabase.getCollection("movies"); |
ID로 문서 검색
사용 Collection.get() 메서드를 전체 문서 검색 를 검색합니다. 다음 코드 샘플은 sample_mflix 버킷 기본 컬렉션에서 두 개의 문서를 검색합니다.
카우치베이스
|
1 2 3 4 5 6 |
// get() will throw an exception if a document with the specified ID does not exist GetResult comment = collection.get("comment:5a9427648b0beebeb69579cc"); System.out.println(comment.contentAsObject()); GetResult movie = collection.get("movie:573a1390f29313caabcd4135"); System.out.println(movie.contentAsObject()); |
MongoDB
|
1 2 |
comments.find(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579cc"))); movies.find(Filters.eq("_id", new ObjectId("573a1390f29313caabcd4135"))); |
새 문서 삽입
사용 Collection.insert() 메서드를 새 문서 만들기 가 아직 존재하지 않는 경우 지정된 ID 및 콘텐츠로 채워집니다. 다음 코드 샘플은 sample_mflix 버킷 기본 컬렉션에 이 문서를 삽입합니다:
|
1 2 3 4 5 6 7 |
{ "name":"Anat Chase", "email":"anat_chase@fakegmail.com", "movie_id":"movie:573a1390f29313caabcd4135", "text":"This is Anat's review", "type":"comment" } |
카우치베이스
|
1 2 3 4 5 6 7 8 9 |
JsonObject doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Anat's review") .put("type", "comment"); // insert() will throw an exception if a document with the specified ID already exists collection.insert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
Document doc = new Document("_id", new ObjectId("5a9427648b0beebeb69579c0")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Anat's review"); comments.insertOne(doc); |
여러 개의 새 문서 삽입
일괄 처리 작업 를 사용하면 네트워크 처리량을 늘리고 지연 시간을 줄임으로써 네트워크 활용도를 높이고 애플리케이션 속도를 높일 수 있습니다. 일괄 처리 작업은 다음과 같이 작동합니다. 파이프라인 요청을 네트워크를 통해 전송합니다. 요청이 파이프라인으로 전송되면 하나의 큰 그룹으로 클러스터로 전송됩니다. 클러스터는 차례로 파이프라인 응답을 클라이언트에 다시 보냅니다.
다음 코드 샘플은 이 접근 방식을 사용하여 sample_mflix 버킷에 두 개의 새 문서를 삽입합니다.
카우치베이스
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Create two JSON documents List<Tuple2<String, JsonObject>> documents = new ArrayList<Tuple2<String, JsonObject>>(); doc = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd42e8") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c1", doc)); JsonObject doc2 = JsonObject.create() .put("name", "Anat Chase") .put("email", "anat_chase@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4323") .put("text", "This is Anat's review") .put("type", "comment"); documents.add(Tuples.of("comment:5a9427648b0beebeb69579c2", doc2)); // Insert the 2 documents in one batch, waiting until the last one is done. // insert() will throw an exception if a document with the specified ID already exists Flux .fromIterable(documents) .parallel().runOn(Schedulers.elastic()) .concatMap(doc3 -> reactiveCollection.insert(doc3.getT1(), doc3.getT2()) .onErrorResume(e -> Mono.error(new Exception(doc3.getT1(), e)))) .sequential().collectList().block(); |
MongoDB
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
List<Document> documents = new ArrayList<Document>(); Document doc1 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c1")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd42e8")) .append("text", "This is Anat's review"); documents.add(doc1); Document doc2 = new Document("_id", new ObjectId("5a9427648b0beebeb69579c2")) .append("name", "Anat Chase") .append("email", "anat_chase@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4323")) .append("text", "This is Anat's review"); documents.add(doc2); comments.insertMany(documents); |
기존 문서 업데이트
사용 Collection.replace() 메서드를 기존 문서 업데이트 가 이미 존재하는 경우에만 지정된 ID를 사용합니다. 카우치베이스 지원 하위 문서 작업 에 효율적으로 액세스하는 데 사용할 수 있습니다. 부품 문서 수를 줄일 수 있습니다. 하위 문서 작업은 다음보다 더 빠르고 네트워크 효율이 높을 수 있습니다. 전체 문서 작업은 네트워크를 통해 문서의 액세스된 부분만 전송하기 때문입니다. 전체 문서 및 하위 문서 작업은 원자적이어서 동시성 제어 기능이 내장된 문서를 안전하게 수정할 수 있습니다.
다음 코드 샘플은 하위 문서 작업을 사용하여 지정된 문서의 텍스트 속성을 업데이트합니다.
카우치베이스
|
1 2 3 4 5 |
// Update a document using the sub-document API to modify the specific attribute(s) // replace() will throw an exception if a document with the specified ID does not exist collection.mutateIn( "comment:5a9427648b0beebeb69579c0", Arrays.asList(replace("text", "This is not Anat's review"))); |
MongoDB
|
1 2 3 |
comments.updateOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), Updates.combine(Updates.set("text", ""))); |
여러 문서 업데이트
키/값 API를 통한 기본 액세스 외에도 다음을 수행할 수 있습니다. N1QL 쿼리 실행 N1QL API를 통해 N1QL 은 JSON 데이터를 쿼리, 변환, 조작하기 위한 선언적 언어입니다(JSON용 SQL이라고 생각하시면 됩니다).
다음 코드 샘플은 N1QL 쿼리를 실행하여 이름이 Anat Chase인 모든 댓글 문서의 이름 및 이메일 속성을 업데이트합니다. 이 쿼리는 idx1 인덱스를 생성합니다.
카우치베이스
|
1 2 3 4 5 6 |
// execute a N1QL UPDATE query via the query API String statement = "UPDATE sample_mflix " + "SET name='Anita Chase', email='anita_chase@fakegmail.com' " + "WHERE type='comment' AND name='Anat Chase'"; QueryResult updateResult = cluster.query(statement); |
MongoDB
|
1 2 3 4 5 |
comments.updateMany( Filters.eq("name", "Anat Chase"), Updates.combine( Updates.set("name", "Anita Chase"), Updates.set("email", "anita_chase@fakegmail.com"))); |
문서 업데이트 또는 삽입
사용 Collection.upsert() 메서드를 문서가 없는 경우 삽입하고, 있는 경우 대체합니다.. 지정된 ID를 가진 문서가 없는 경우 upsert()는 새 문서를 만듭니다. 지정된 ID를 가진 문서가 존재하면 upsert()는 기존 문서를 업데이트합니다. 다음 코드 샘플은 sample_mflix 버킷에 있는 기존 문서를 업데이트합니다.
카우치베이스
|
1 2 3 4 5 6 7 8 9 |
doc = JsonObject.create() .put("name", "Mia Hannas") .put("email", "mia_hannas@fakegmail.com") .put("movie_id", "movie:573a1390f29313caabcd4135") .put("text", "This is Mia's review") .put("type", "comment"); // upsert() will update the document if it exists or insert the document if it does not exist collection.upsert("comment:5a9427648b0beebeb69579c0", doc); |
MongoDB
|
1 2 3 4 5 6 7 |
collection.replaceOne( Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0")), new Document("name", "Mia Hannas") .append("email", "mia_hannas@fakegmail.com") .append("movie_id", new ObjectId("573a1390f29313caabcd4135")) .append("text", "This is Mia's review"), new UpdateOptions().upsert(true)); |
문서 삭제
사용 Collection.remove() 메서드를 전체 문서 제거 버킷에 지정된 ID를 추가합니다. 다음 코드 샘플은 sample_mflix 버킷에서 기존 문서를 삭제합니다.
카우치베이스
|
1 2 |
// remove() will throw an exception if the document does not exist collection.remove("comment:5a9427648b0beebeb69579c0"); |
MongoDB
|
1 |
collection.deleteOne(Filters.eq("_id", new ObjectId("5a9427648b0beebeb69579c0"))); |
여러 문서 삭제
N1QL 쿼리를 사용하여 문서를 삭제할 수도 있습니다. 다음 코드 샘플은 샘플_mflix 버킷에서 여러 문서를 삭제하기 위해 N1QL 쿼리를 실행합니다. 이름이 Anita Chase인 모든 댓글 문서가 삭제됩니다. 이 쿼리는 idx1 인덱스를 생성합니다.
카우치베이스
|
1 2 3 4 5 |
// execute a N1QL DELETE query via the query API String statement = "DELETE FROM sample_mflix " + "WHERE type='comment' AND name='Anita Chase'"; QueryResult deleteResult = cluster.query(statement); |
MongoDB
|
1 |
comments.deleteMany(Filters.eq("name", "Anita Chase")); |
N1QL을 사용한 데이터 액세스
N1QL은 데이터의 보다 복잡한 2차 조회를 수행하는 데에도 사용할 수 있습니다. 다음 코드 샘플은 연도가 1970년에서 1979년 사이인 모든 영화 문서에서 제목, 연도 및 imdb.rating을 선택하기 위해 차단 N1QL 쿼리를 실행합니다(imdb.rating에 따라 정렬). 이 쿼리는 idx2 인덱스를 생성합니다.
다음과 유사 반응형 키/값 작업 일괄 처리, 반응형 및 비동기 쿼리 를 사용하여 성능을 향상시켜야 합니다.
카우치베이스
|
1 2 3 4 5 6 7 8 |
// execute a N1QL SELECT query (blocking) via the query API String selectStatement = "SELECT title, year, imdb.rating FROM sample_mflix " + "WHERE type='movie' AND year BETWEEN 1970 AND 1979 ORDER BY imdb.rating DESC"; final QueryResult selectResult = cluster.query(selectStatement); for (JsonObject row : selectResult.rowsAsObject()) { System.out.println(row.toString()); } |
MongoDB
|
1 2 3 4 5 |
movies.find(Filters.and(Filters.gte("year", 1970), Filters.lte("year", 1979))) .sort(Sorts.descending("imdb.rating")) .projection(Projections.fields( Projections.include("title", "year", "imdb.rating"), Projections.excludeId())); |
다음 단계
다음을 포함한 Couchbase SDK의 다른 기능에 대해 알아보세요. 분석 그리고 전체 텍스트 검색. 다음에서 제공되는 무료 온라인 교육을 활용하세요. https://learn.couchbase.com 를 클릭하여 Couchbase에 대해 자세히 알아보세요.
MongoDB에 비해 Couchbase 데이터 플랫폼의 아키텍처적 장점에 대한 자세한 내용은 이 문서를 참조하세요: 카우치베이스: 모든 면에서 몽고DB보다 나은 카우치베이스.
다른 기업들이 MongoDB 대신 Couchbase를 선택하는 이유를 알아보세요: