Hoje, temos o prazer de anunciar melhorias significativas na Pesquisa de texto completo (FTS) em Servidor Couchbase 4.6. Este blog descreve o que há de novo para a pesquisa na versão 4.6:
- Melhorias no desempenho
- Mapeamento de tipo de índice por chave
- Classificação personalizada
O Couchbase Server FTS é executado perfeitamente em seu cluster e oferece recursos de pesquisa semelhantes aos do Elasticsearch. O FTS "simplesmente funciona" distribuído - Você não precisa fazer nada de especial para executar a pesquisa de vários nós distribuída em seu cluster - você a gerencia da mesma forma que os usuários esperam do Couchbase Server. Por exemplo, você pode adicionar hardware, fazer o rebalanceamento, e o Couchbase Server distribui os índices pelo cluster para que os nós recém-provisionados comecem a lidar com a carga de trabalho de pesquisa. Isso faz parte do objetivo: simplificar a pesquisa, tanto para desenvolvedores quanto para administradores.
Observe que o FTS está na versão prévia para desenvolvedores e permanecerá na versão prévia para desenvolvedores mesmo depois que o Couchbase Server 4.6 for lançado no GA. Convidamos você a experimentá-lo e compartilhar seus comentários.
https://www.couchbase.com/blog/2016/november/introducing-couchbase-server-4.6.0-developer-preview
Pesquisa mais rápida
Você notará que a pesquisa está mais rápida e mais eficiente com os recursos na versão 4.6 em comparação com as versões anteriores. Essa versão traz melhorias em todo o sistema, tanto no próprio FTS quanto no sangrara biblioteca Go de pesquisa e indexação de texto completo que alimenta o FTS.
O maior contribuinte individual para as melhorias de desempenho é o MossStore, o novo mecanismo de armazenamento kv padrão para índices de texto completo no FTS. O MossStore faz parte do Musgo ("Segmentos ordenados orientados à memória"), uma coleção de valores-chave ordenados, simples, rápida e persistente, implementada como uma biblioteca Golang pura. O Moss melhora o desempenho da consulta e, principalmente, da indexação, classificando os segmentos do índice na memória antes de persisti-los. A principal vantagem do MossStore em relação aos armazenamentos genéricos de KV é que os segmentos são sempre ordenados, de modo que o MossStore não precisa ser reordenado. O MossStore é recomendado para todos os casos de uso.
Ainda mais aprimoramentos de desempenho estão a caminho para a próxima versão. Fique ligado!
Mapeamento de tipo de índice por chave
Agora você pode criar mapeamentos de índices personalizados usando a chave do documento para determinar o tipo. O mapeamento de índices é o processo de especificação das regras para tornar os documentos pesquisáveis. Na pesquisa de texto completo, os desenvolvedores geralmente especificam diferentes mapeamentos de índice para diferentes tipos de documentos. Por exemplo, talvez você queira indexar o campo "city" (cidade), mas somente para documentos do tipo "hotel" e não para documentos do tipo "landmark" (ponto de referência). Nas versões anteriores, isso só funcionava se o tipo fosse definido por um atributo no JSON do documento; na versão 4.6, você também pode usar uma parte da chave do documento para determinar o tipo de documento, por exemplo, o prefixo até "::" para chaves como "hotel::1234".
Com esse aprimoramento, é mais fácil oferecer suporte ao estilo comum de modelagem de dados no qual o tipo de documento é indicado por uma parte da chave, por exemplo, "user::will.gardella". De modo geral, esse identificador de tipo será um prefixo da chave, de modo que o FTS oferece uma opção fácil para especificar apenas o prefixo sem mexer com expressões regulares. Por outro lado, você pode usar expressões regulares se tiver um design de chave mais complexo, como um infixo.
Você pode experimentar isso no bucket de amostra de viagem que vem com o Couchbase Server. O modelo de dados da amostra de viagem segue o princípio do cinto e suspensórios: o tipo de documento é indicado de forma redundante em um atributo de tipo JSON E no prefixo da chave do documento.
Aqui está um exemplo passo a passo, supondo que você tenha o bucket travel-sample instalado. Vamos criar um índice que permitirá que nossos usuários pesquisem hotéis e companhias aéreas. Uma coisa um pouco estranha de se fazer, mas vamos em frente.
Primeiro, acesse seu administrador da Web (por exemplo https://localhost:8091/) > índices > índices de texto completo > novo índice de texto completo. Esse URL pode levá-lo diretamente para lá, dependendo de onde você administra seu servidor: https://127.0.0.1:8091/ui/index.html#/fts_new/?indexType=fulltext-index&sourceType=couchbase.
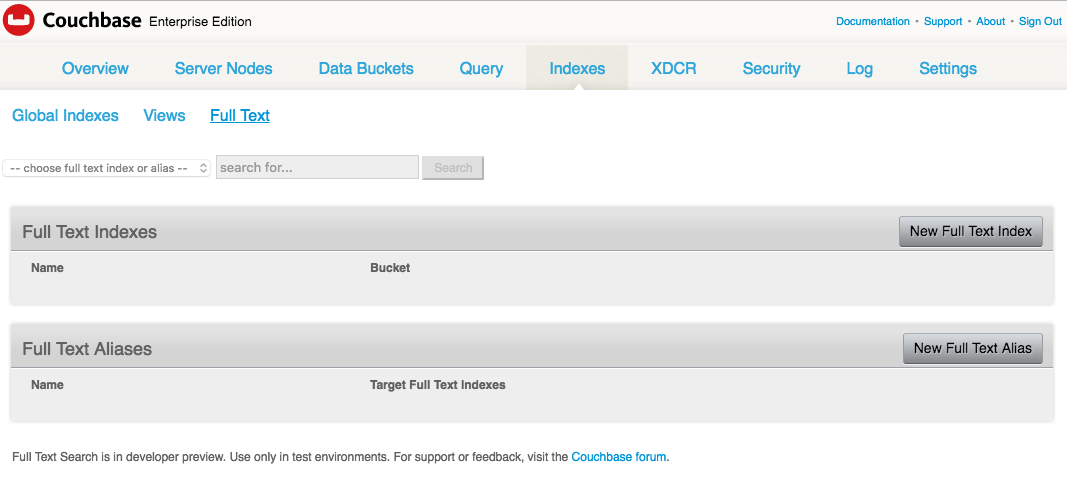
Você verá um novo "Identificador de tipo". O comportamento antigo é o padrão, ou seja, procurar no corpo do documento um campo chamado "type" que indique o tipo de documento. Nesse caso, em vez disso, você usará o id dos metadados do documento.
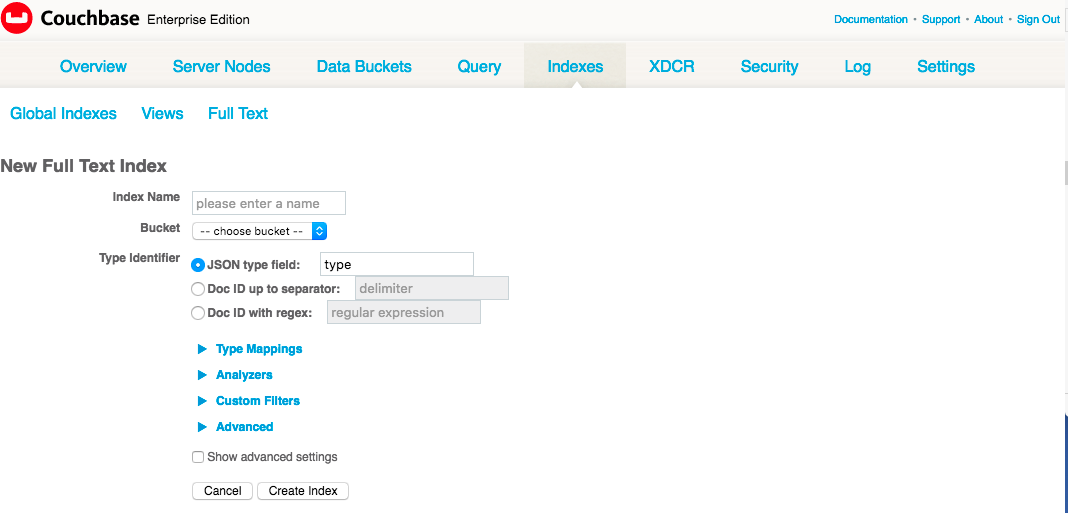
Clique na caixa de seleção ao lado de Doc ID até o separador. Digite o sublinhado "_". Isso instrui o FTS a analisar as chaves do documento até o sublinhado e comparar esses prefixos com as cadeias de caracteres que você inserir em "Type mapping". É importante observar que essa etapa apenas informa ao FTS onde procurar o tipo de documento, mas ainda não declara nenhuma regra de mapeamento de índice. É isso que faremos a seguir.
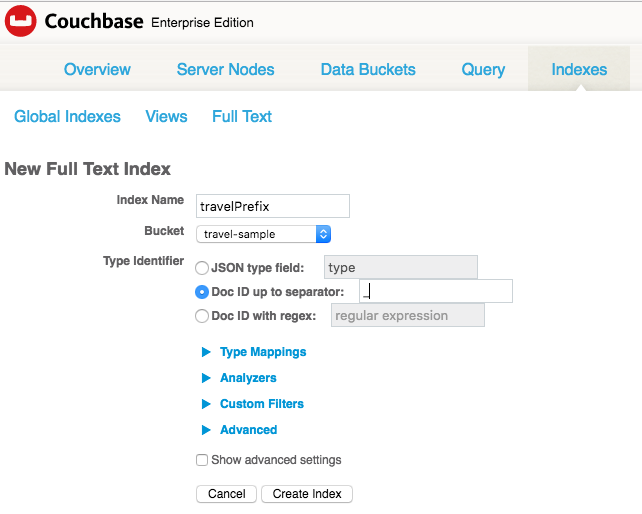
Clique em "Add Type Mapping" (Adicionar mapeamento de tipos). Adicione um tipo "airline" (companhia aérea) e um tipo "hotel" (hotel). Não se esqueça de desativar o mapeamento padrão, caso contrário, você terá tudo em seu índice, não apenas companhias aéreas e hotéis.
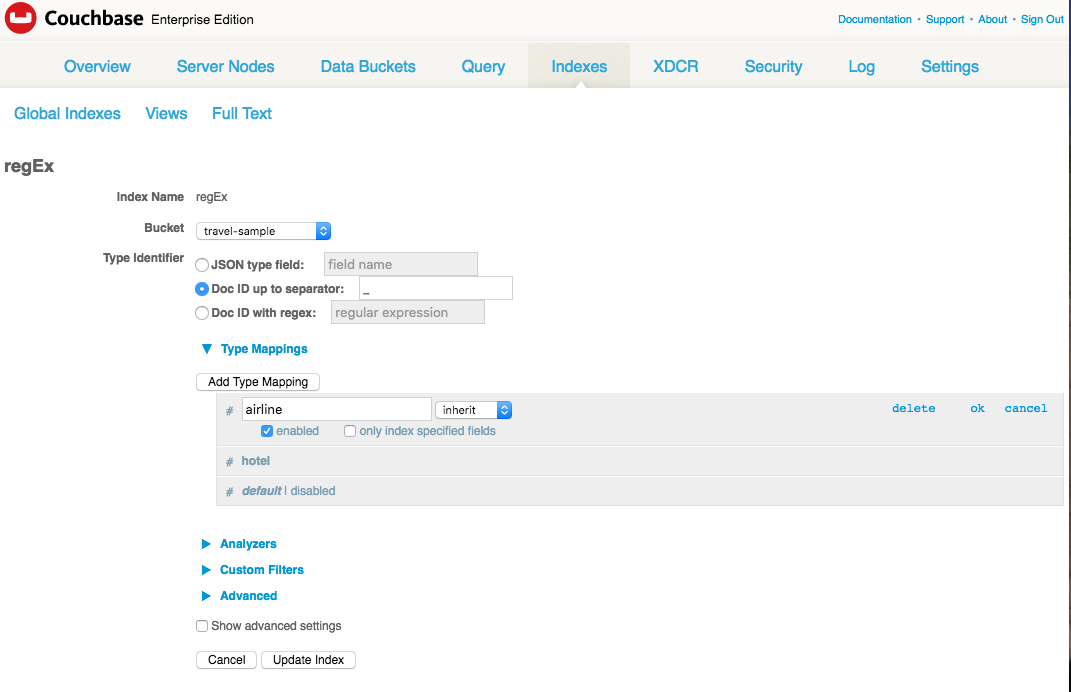
Por fim, como se trata apenas de um teste, desdobre "Advanced" (Avançado) clicando no triângulo e marque "Store Dynamic Fields" (Armazenar campos dinâmicos). Isso não apenas indexará todos os campos de todos os documentos de companhias aéreas e hotéis, mas também armazenará o que for indexado no índice de texto completo para que possa ser destacado e recuperado como snippets. Isso torna a demonstração mais agradável, mas engorda seu índice e torna tudo mais lento. Para esta demonstração, isso não deve fazer muita diferença.
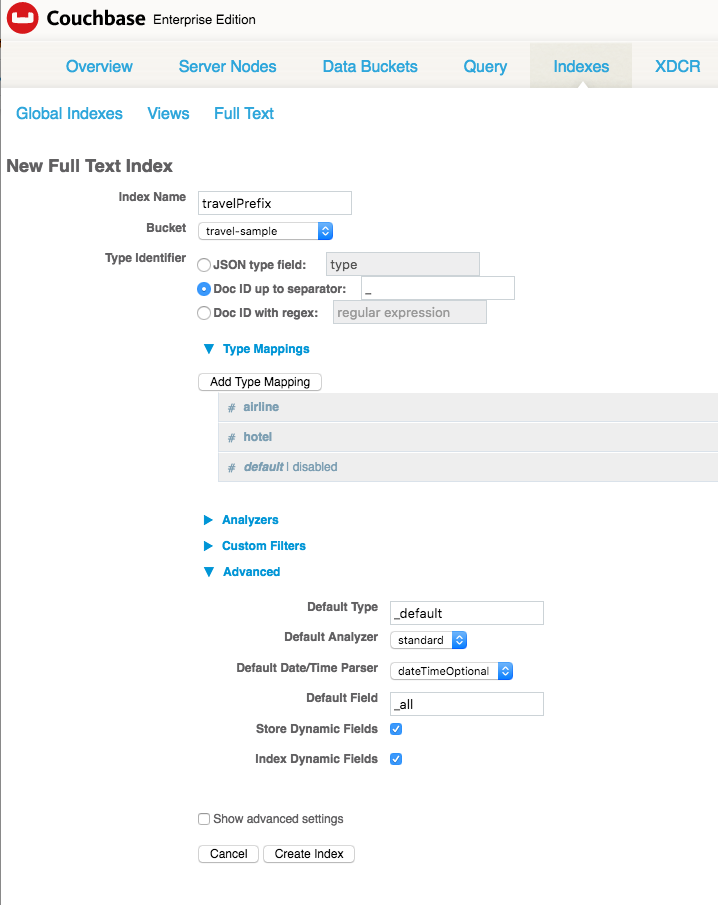
Quando você tiver terminado, a definição do índice terá a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
{ "type": "fulltext-index", "name": "travelPrefix", "sourceType": "couchbase", "sourceName": "travel-sample", "planParams": { "maxPartitionsPerPIndex": 32, "numReplicas": 0, "hierarchyRules": null, "nodePlanParams": null, "pindexWeights": null, "planFrozen": false }, "params": { "doc_config": { "docid_prefix_delim": "_", "mode": "docid_prefix" }, "mapping": { "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "display_order": "2", "dynamic": true, "enabled": false }, "default_type": "_default", "index_dynamic": true, "store_dynamic": true, "type_field": "type", "types": { "airline": { "display_order": "0", "dynamic": true, "enabled": true }, "hotel": { "display_order": "1", "dynamic": true, "enabled": true } } }, "store": { "kvStoreName": "mossStore" } }, "sourceParams": { "clusterManagerBackoffFactor": 0, "clusterManagerSleepInitMS": 0, "clusterManagerSleepMaxMS": 2000, "dataManagerBackoffFactor": 0, "dataManagerSleepInitMS": 0, "dataManagerSleepMaxMS": 2000, "feedBufferAckThreshold": 0, "feedBufferSizeBytes": 0 } } |
Observe que sua definição de índice JSON recém-criada tem um campo no objeto "params" chamado "doc_config", que é novo na versão 4.6. Esse campo, "doc_config", também é um objeto com dois campos "mode" e "type_field" ou "mode", dependendo se você está mapeando com base na ID do documento ou no campo de tipo.
Mapeamento de índices por campo de tipo:
|
1 2 3 4 |
"doc_config": { "mode": "type_field", "type_field": "type" } |
Mapeamento de índices por ID de documento (prefixo até):
|
1 2 3 4 |
"doc_config": { "docid_prefix_delim": "_", "mode": "docid_prefix" } |
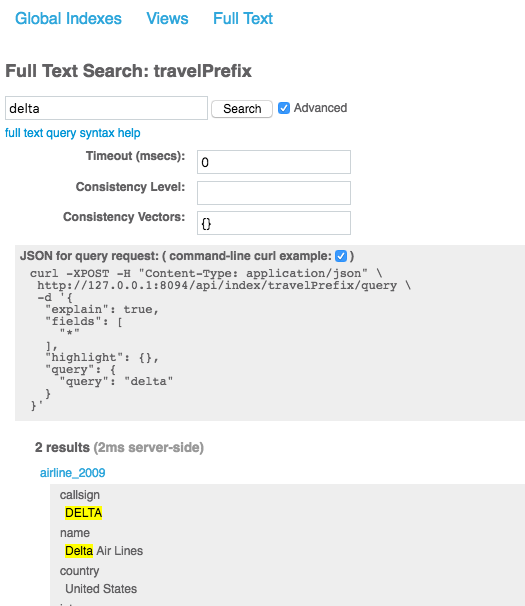
Você pode testar seu novo e brilhante índice executando uma consulta de string de consulta para "delta", que corresponde exatamente a uma companhia aérea e a um hotel. (Eu sei, conveniente, certo?). Seu JSON de consulta terá a seguinte aparência se estiver usando a API REST, ou você pode usar a caixa de pesquisa no Web Admin para fazer a mesma pesquisa.
|
1 2 3 4 5 6 7 8 9 10 |
{ "explain": true, "fields": [ "*" ], "highlight": {}, "query": { "query": "delta" } } |
Dica bônus:
Você pode obter o JSON da consulta no administrador da Web clicando na opção "Advanced" (Avançado) à direita do campo de entrada de pesquisa e, em seguida, clicando na caixa de exemplo de curl de linha de comando.
Classificação
O Couchbase Server 4.6 introduz a capacidade de classificar os resultados da pesquisa por qualquer campo do documento, desde que esse campo também esteja indexado. Em versões anteriores, e por padrão na 4.6, os resultados da pesquisa são classificados por pontuação decrescente para que os resultados mais relevantes sejam listados primeiro.
Para usar a ordem de classificação personalizada, você passa um campo "sort" com uma matriz de cadeias de caracteres em sua consulta, em que cada cadeia de caracteres se refere ao nome de um campo que você deseja classificar. Usando o índice travelPrefix que criamos na etapa anterior, você pode classificar por nome desta forma:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "explain": false, "fields": [ "title" ], "highlight": {}, "sort": ["name"], "query":{ "query": "beautiful pool" } } |
Você pode prefixar qualquer nome de campo com o caractere "-", o que faz com que esse campo seja classificado em ordem decrescente. Portanto, o campo de classificação do exemplo anterior teria a seguinte aparência:
|
1 |
"sort": ["-name"] |
Se você passar uma matriz de nomes de campos, os resultados serão classificados primeiro pelo primeiro campo. Os itens com o mesmo valor para esse campo serão classificados pelo próximo campo, e assim por diante.
Você pode usar dois campos especiais que funcionam para todos os documentos:
'_id' - refere-se à chave do documento
'_score' - refere-se à pontuação de relevância calculada pelo Bleve
Aqui está outro exemplo. Neste exemplo, os documentos são classificados por pontuação, em ordem decrescente, e por id, se houver empate.
|
1 |
"sort": ["-_score",”_id”] |
Aqui está um exemplo mais complexo que você poderia usar para classificar os resultados da pesquisa de hotéis:
|
1 |
"sort": ["country", “state”, "city","-_score"] |
Os resultados serão classificados primeiro por país. Se os documentos tiverem o mesmo valor para país, eles serão classificados por estado e, em seguida, se país e estado forem iguais, as correspondências serão classificadas por cidade. Finalmente, se todos os outros campos forem iguais, os resultados serão classificados de forma decrescente por pontuação. Neste exemplo, você obterá uma lista de resultados agrupados de acordo com a geografia e classificados por pontuação no nível da cidade.
Comentários são bem-vindos
Como sempre, gostamos de ouvir sua opinião. A generosidade da comunidade e dos primeiros usuários tem uma grande influência na direção do produto. Boa pesquisa!