Integral aspect of any distributed system is to seamlessly provide high availability (HA) and load balancing capabilities to its user. With little to no input from user, Couhbase’s Global Secondary Indexes1 (GSI) provides its users with both – HA and Load Balancing within a couchbase cluster.
What is Index Planner
Index Planner is a library used by Couchbase indexing service to determine the optimal placement of the indexes. It seamlessly provides support for HA-aware index placement and load balancing for the Couchbase indexing service. Index planner is used to decide the optimal index placement in two use cases, (1) New Index Creation and (2) Index Service Rebalance i.e. when indexer nodes are added and/or removed from the cluster2.
How Index Planner Works
Given a set of “nodes” hosting the Couchbase indexing service (may be having different hardware configurations), and a set of indexes with their own “load parameters”, Index Planner provides the user with optimal placement3 of these indexes on these indexer nodes. Optimally placing hundreds of indexes – having different values of load parameters – on tens of indexer nodes, requires exploration of a very large solution space. So, deterministically finding “the” optimal solution requires exponential time. Hence, instead of finding “the” optimal solution, Index Planner uses probabilistic simulated annealing method to find approximate globally optimal solution. Experimentally, simulated annealing has been proved to yield good results for the couchbase server’s index placement algorithm.
The load parameters considered by the Index Planner are (1) size of the index (2) memory footprint of the index (3) scan rate for the index (4) data ingestion rate for the index etc., just to name a few. All of these load parameters help Index Planner to calculate the load generated by each index, and in turn calculate the load put on each indexer node by any specific index placement. At the time of index creation, actual values of the load parameters are unknown. So, for the purpose of index creation, Index Planner runs with “estimated values” of these load parameters. During rebalance, the Index Planner gets the values of these load parameters from the index stats.
Example 1:
Let’s consider a Couchbase cluster with 3 identical indexer nodes – “Node 1”, “Node 2” and “Node 3”. Let’s assume that nodes Node 1 and Node 2 are already hosting 1 index each – index1 and index2 respectively. If the user adds a new index “index3”, based on current load distribution, Index Planner will place the new index on Node 3.
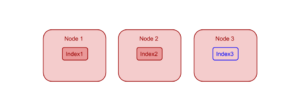
This is how the Index Planner takes care of distributing indexes among all available index nodes in the cluster. To provide further load balancing capabilities and to provide HA, indexing service allows users to create index replicas. In the following sections we will discuss the index replicas.
Index Planner for Index Replica Placement
For high availability, users are always advised to create one or more index replicas (based on their HA requirements). Couchbase indexing service implements master-master replica policy. So, all the replicas in the cluster can serve incoming queries4. Couchbase indexing service makes sure that the scan requests are uniformly distributed across all the index replicas.
Index Planner “always” makes sure that the replicas of the same index will get placed on different indexer nodes. This provides users with High Availability.
Example 2:
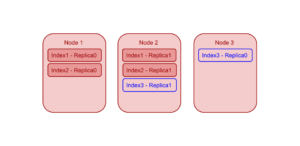
In the same cluster as Example 1, let’s assume that nodes Node 1 and Node 2 are already hosting 2 index replicas each, and Node 3 is not hosting any index replica5. So, if the user adds a new index “index3” with two replicas (replica0 and replica1), based on current load distribution, Index Planner will place the one of the new index replicas on node Node 3, but second replica will NOT be placed on Node 3 – even if it means relatively uneven load distribution across the nodes.
Notes: Each index replica is identified by its id (i.e. replicaId) which starts from zero. Also, user can specify the required number of replicas at the time of index creation using “num_replica” parameter, where “num_replica” = 1 means total 2 index instances (with replicaId 0 and replicaId 1) will be created.
Index Planner for Rack Zone Awareness
Couchbase cluster manager provides users with the ability to group the cluster nodes to form Server Groups. Each server group can be mapped to a failover zone in the data center. For example, all the nodes in a single “rack” in the data center can belong to a single server group.
Index Planner is “rack zone aware” and it always places the replicas of same index in different server groups. If the number of server groups is less than the number of replicas, server groups can host more than 1 replica.
Example 3:
Let’s consider a Couchbase cluster with 4 identical indexer nodes – “Node 1”, “Node 2”, “Node 3” and “Node 4”. Node 1 and Node 2 belong to “Server Group 1” and, Node 3 and Node 4 belong to “Server Group 2”. Let’s assume that nodes Node 1 and Node 2 are already hosting 1 index each: index1 – replica0 and index2 – replica0 respectively. Now, if the user adds a new index “index3” with 2 replicas (replica0 and replica1) to the cluster. So, Index Planner will add one replica to Node 3 or Node 4 distribute the load. But, the second replica has to go Server Group 1, because Node 3 or Node 4 – belonging to Server Group 1 – is already hosting one replica. Index Planner makes this choice even if it means a relatively uneven load distribution across multiple nodes.
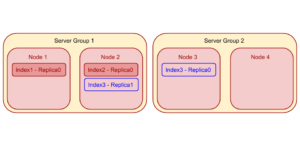
Index Planner for Index Partition Distribution
Couchbase users can create partitioned index to get better load distribution – with respect to index build – and to get faster scan results for large indexes. With the help of partitioned index, index data will be distributed among multiple partitions based on the hash-value of the partition key. Index planner is partition-aware and can distribute index partitions across multiple indexer nodes – based on the index build load and index scan load.
Index Planner distributes partitions of an index amongst as many indexer nodes as possible. This is useful in distributing the index scan load as well as the index build load among those indexer nodes. But Index Planner doesn’t guarantee uniform distribution of partitions among all available indexer nodes. This helps users in getting better distribution of overall load in the cluster, when there are multiple non-partitioned and partitioned indexes with different “load parameters”.
Example 4:
Let’s consider a Couchbase cluster with 4 identical indexer nodes – “Node 1”, “Node 2”, “Node 3” and “Node 4”. Let’s assume that nodes Node 1 is already hosting 2 non-partitioned indexes. Now, if the user adds a partitioned index6 “index3” (with 4 partitions), Index Planner may distribute the 4 partitions of the new index only among Node 2, Node 3 and Node 4. This will ensure overall better load distribution in the cluster.
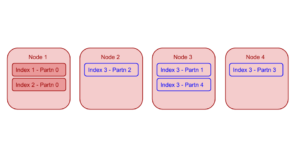
Partitioned indexes can have replicas. Each partition of an index has its own set of partition replicas. Index Planner makes sure that partition replicas are also distributed across indexer nodes and across different server groups to ensure required load distribution and high availability.
In the next part of this blog, we will discuss how couchbase indexing service uses Index Planner for various use cases.
1 In this blogpost, the term “index” will be used only for Couchbase’s Global Secondary Indexes.
2 Indexes residing on the non-removed nodes in the cluster are unaffected by rebalance.
3 Optimal placement means best possible load distribution that adheres to all HA requirements.
4 Global Secondary Index replicas are built and maintained completely independent of each other. The incoming queries – served by these replicas – adhere to the Couchbase GSI consistency model.
5 Users can end up with this kind of index distribution when they start with two nodes in the cluster, create indexes with 2 replicas each and then add a third node to the cluster.
6 For partitioned index, partition ids start from 1. Partition id 0 is used for non-partitioned index.