Um RoSe em qualquer outro caso teria o mesmo cheiro. William Shakespeare
Você deve ter aprendido regras de capitalização em sua escola de gramática, mas a pesquisa no mundo real não é tão sensível à capitalização. Charles de Gaulle usa letra minúscula para o "de" do meio, Tony La Russa usa letra maiúscula para "La" - pode haver razões etimológicas para isso, mas é improvável que seu agente de atendimento ao cliente se lembre. Os bancos de dados têm uma variedade de sensibilidades. O SQL, por padrão, não diferencia maiúsculas de minúsculas para identificadores e palavras-chave, mas diferencia maiúsculas de minúsculas para dados. O JSON diferencia maiúsculas de minúsculas para nomes de campos e dados. O mesmo acontece com o N1QL. O JSON pode ter o seguinte. O N1QL selecionará cada campo e valor como um campo e valor distintos.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT {"City": "San Francisco", "city": "san francisco", "citY": "saN fanciscO"} [ { "$1": { "City": "San Francisco", "citY": "saN fanciscO", "city": "san francisco" } } ] |
Neste artigo, discutiremos como lidar com sensibilidade dos dados a maiúsculas e minúsculas. Suas referências de campo ainda são diferencia maiúsculas de minúsculas. Se você usar a caixa incorreta para o nome do campo, o N1QL assumirá que se trata de um campo ausente e atribuirá o valor MISSING a esse campo.
Vamos considerar um predicado simples no N1QL para pesquisar todas as permutações de casos.
|
1 |
WHERE name in [“joe”, “joE”, “jOe”, “Joe”, “JoE”, “JOe”, “JOE”] |
Isso requer sete pesquisas diferentes no índice. "John" requer mais pesquisas no índice e "Fitzerald" requer ainda mais. Há uma maneira padrão de fazer isso. Basta criar um índice diminuindo o case do campo e o literal.
|
1 |
WHERE LOWER(name) = “joe” |
Essa pesquisa pode ser agilizada com a criação do índice com a expressão correta.
|
1 |
CREATE INDEX i1 ON customer(LOWER(name)); |
Certifique-se de que sua consulta esteja pegando o índice correto e empurre o predicado para a varredura do índice. E essa é a ideia. As consultas que têm predicados enviados para a varredura de índice são executadas muito mais rapidamente do que as consultas que não têm. Isso é verdadeiro para predicados e verdadeiro para pushdown agregado também.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
EXPLAIN SELECT * FROM `customer` WHERE LOWER(name) = "joe"; { "#operator": "IndexScan3", "index": "i1", "index_id": "c117bdf583c2e276", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"joe\"", "inclusion": 3, "low": "\"joe\"" } ] } ], |
Insensibilidade de casos em um cenário de índice composto.
|
1 2 3 4 5 |
WHERE LOWER(name) = “joe” AND zip = 94821 AND salary > 500 AND join_date <= “2017-01-01” AND LOWER(county) LIKE “san%” |
|
1 2 3 4 5 |
CREATE INDEX i2 ON customer(LOWER(name), zip, LOWER(county), join_date, salary) |
Insensibilidade a maiúsculas e minúsculas em funções de matriz.
Funções de cadeia de caracteres como SPLIT(), SUFFIXES(), muitos dos funções de matriz e funções de objeto retornam matrizes. Então, como usá-los de maneira que não diferencie maiúsculas de minúsculas?
Seguimos o mesmo princípio de antes. Crie uma expressão para reduzir os valores a minúsculas antes de processá-los por meio dessas funções.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SPLIT("Good Morning, Joe") as splitresult; "splitresult": [ "Good", "Morning,", "Joe" ] SELECT SPLIT(LOWER(“Good Morning, Joe”)); "splitresult": [ "good", "morning,", "joe" ] |
Agora, o que você realmente deseja é filtrar com base em um valor dentro da cadeia de caracteres.
|
1 |
WHERE LOWER(xyz) LIKE “%good%”; |
Esse é provavelmente o pior predicado do SQL, em termos de desempenho.
|
1 2 |
SELECT * FROM customer WHERE x IN SPLIT(LOWER(xyz)) SATISFIES x = “good” END |
Agora, que índice você criaria para isso? CONSELHO é útil.
|
1 2 |
CREATE INDEX adv_DISTINCT_split_lower_xyz ON `customer` (DISTINCT ARRAY `x` FOR x in split(lower((`xyz`))) END) |
Como sempre, verifique sua explicação.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "index": "adv_DISTINCT_split_lower_xyz", "index_id": "552ab6c643616fbc", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"good\"", "inclusion": 3, "low": "\"good\"" } ] } ], |
Se você quiser fazer UNNEST e tiver uma cláusula WHERE simples, use esta consulta. Sempre verifique sua explicação para garantir que os predicados sejam enviados para a varredura do índice.
|
1 2 3 |
SELECT * FROM customer UNNEST SPLIT(LOWER(xyz)) AS x WHERE x = "good" |
Uso de tokens
A função TOKENS() simplifica a obtenção de letras minúsculas ao usar essa opção como argumento. Consulte o artigo Mais do que LIKE: Pesquisa eficiente de JSON com N1QL para obter detalhes e exemplos
Expressões complexas.
|
1 2 3 4 |
SELECT * FROM customer WHERE lower(fname) || lower(mname) || lower(lname) = “JoeMSmith” |
Como poderíamos otimizar isso? O Index Advisor veio em socorro. Novamente.
|
1 2 |
CREATE INDEX adv_lower_fname_concat_lower_mname_concat_lower_lname ON `customer`(lower((`fname`))||lower((`mname`))||lower((`lname`))) |
Explique para confirmar o plano:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "#operator": "IndexScan3", "index": "adv_lower_fname_concat_lower_mname_concat_lower_lname", "index_id": "aaa14cbdf14e9cd8", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"JoeMSmith\"", "inclusion": 3, "low": "\"JoeMSmith\"" } ] } ], "using": "gsi" }, |
Trazendo as grandes armas: pesquisa de texto completo
Como você percebeu, esse é um problema de processamento e consulta de texto. O FTS pode digitalizar, armazenar e pesquisar textos de várias maneiras. A pesquisa sem distinção entre maiúsculas e minúsculas é uma delas. Vamos ver o plano de uma consulta de pesquisa simples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
select * from customer where search (name, "joe") "~children": [ { "#operator": "PrimaryScan3", "index": "#primary", "index_projection": { "primary_key": true }, "keyspace": "customer", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "keyspace": "customer", "namespace": "default" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "search((`customer`.`name`), \"joe\")" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "self", "star": true } ] } ] } } ] } |
Esse NÃO é o plano que você deseja... Isso é usar um exame primário!
Depois de criar o índice de texto no cliente do balde, as coisas ficaram muito melhores:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
select * from customer where search (name, "joe") { "#operator": "Sequence", "~children": [ { "#operator": "IndexFtsSearch", "index": "trname", "index_id": "3bdb61e5010e8838", "keyspace": "customer", "namespace": "default", "search_info": { "field": "\"`name`\"", "outname": "out", "query": "\"joe\"" }, "using": "fts" }, |
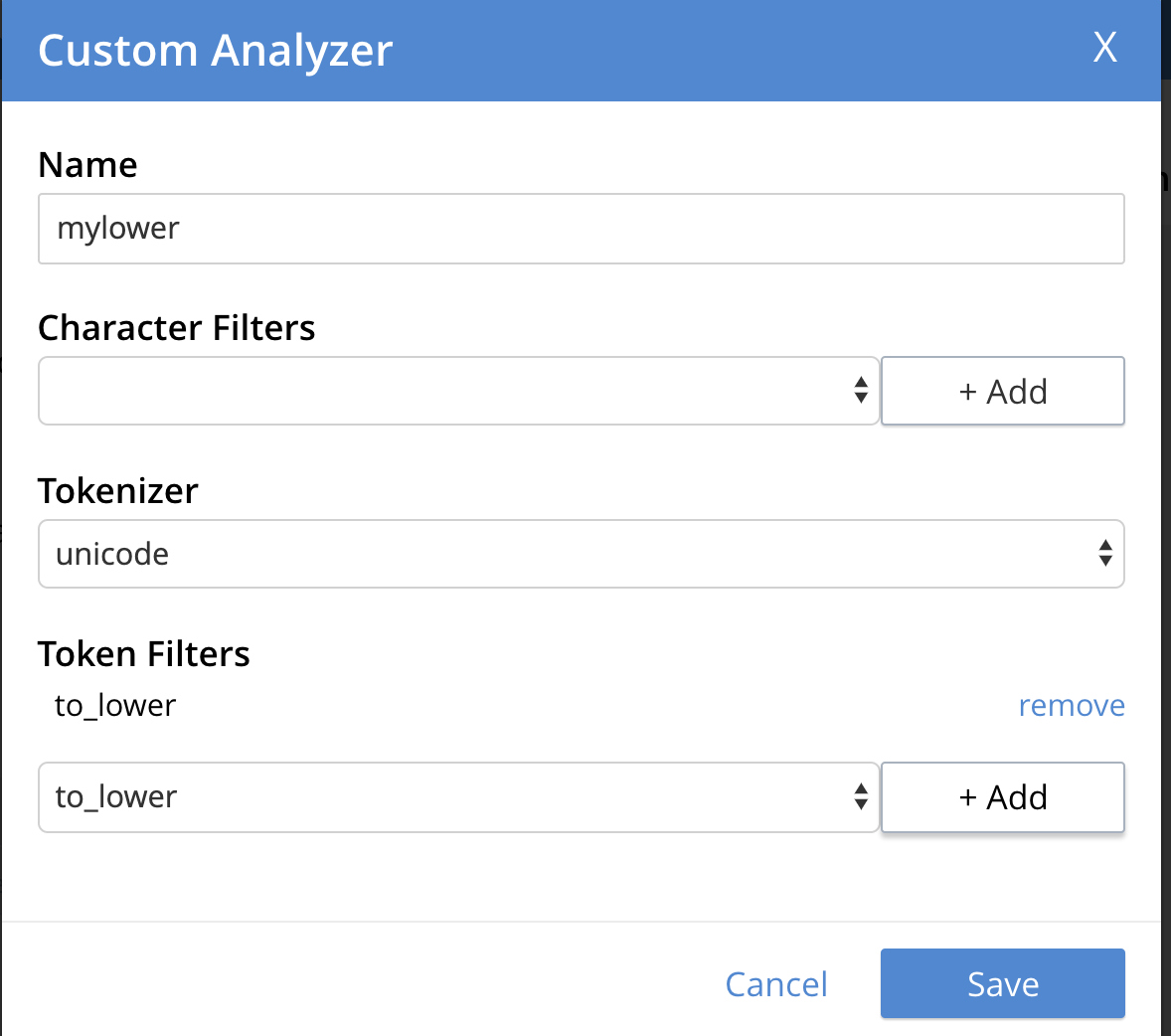
O analisador padrão padrão reduz todos os tokens e, portanto, você encontrará todos os "joe "s : JOE, joe, Joe, JOe, etc. Você pode definir um analisador personalizado e fornecer instruções específicas para reduzir os tokens. Aqui está um exemplo.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"mapping": { "analysis": { "analyzers": { "mylower": { "token_filters": [ "to_lower" ], "tokenizer": "unicode", "type": "custom" } } }, |
Veja como adicioná-lo na interface do usuário. Ver blog fino 8 maneiras de personalizar os índices do Couchbase Full-Text Search para obter detalhes sobre as várias maneiras de personalizar o índice FTS.