Resumo executivo
Industry-standard text-to-SQL benchmarks are designed for relational, structured databases. However, not all real-world data workloads are confined to relational systems. Modern AI-driven query platforms increasingly operate on document-oriented data stores such as Couchbase, where schemas are flexible and data is represented as nested JSON rather than normalized tables. This divergence introduces a fundamental evaluation challenge: how can we rigorously measure the accuracy of an AI query system on a non-relational platform without rewriting the benchmark itself? Evaluating AI query systems built on non-relational platforms – such as Couchbase – against these benchmarks therefore requires non-trivial architectural adaptation. This document presents the approach taken to re-architect the Spider2-Lite benchmark pipeline to run on Couchbase, a document-oriented, non-relational database, while fully preserving the integrity of the evaluation methodology.
Why Spider2 and Spider2-Lite?
Evaluating an AI-powered natural language query system requires a benchmark that is both realistic in query complexity and widely accepted by the research community. For this work, the Spider benchmark family was selected because it is one of the most rigorous and commonly used datasets for evaluating text-to-SQL systems.
Spider introduced a challenging evaluation paradigm in which models must generalize to previously unseen database schemas. Instead of memorizing query templates, systems must interpret a natural language question, understand the provided schema, and generate a correct query dynamically. This property makes Spider particularly well-suited for evaluating production systems such as Couchbase Capella iQ, where queries must operate over arbitrary customer schemas rather than a fixed training dataset.
More recently, Spider2 was introduced to reflect modern data environments and higher query complexity. Spider2 expands beyond simple relational tasks and introduces queries that more closely resemble real analytical workloads. However, the full Spider2 benchmark spans multiple database backends – including BigQuery, Snowflake, and Google Analytics – which require external infrastructure and large-scale data environments.
For this architectural study, the focus was placed on Spider2-Lite, a curated subset of Spider2 designed to preserve the benchmark’s complexity while remaining runnable in a controlled local environment. Spider2-Lite includes a set of SQLite-backed instances that can be executed locally without cloud dependencies, making it feasible to migrate the underlying data and reproduce the evaluation pipeline.
This made Spider2-Lite an ideal candidate for this case study: it maintains the rigor and schema generalization challenges of modern text-to-SQL benchmarks, while allowing the underlying relational datasets to be systematically migrated to Couchbase for evaluation.
The Architectural Problem
Spider2-Lite Assumptions
Spider2-Lite, like virtually all text-to-SQL benchmarks, is built on a set of foundational assumptions rooted in the relational model:
- Data is stored in structured tables with fixed schemas
- Queries are expressed in standard SQL (ANSI-compatible)
- Relationships between entities are expressed through foreign keys and joins
- Results are deterministic, row-ordered tabular outputs
These assumptions are well-suited for databases like SQLite, PostgreSQL, and MySQL. They do not hold, without adaptation, for document-oriented databases such as Couchbase.
Couchbase
Couchbase is a multi-model, non-relational database that organizes data as Documentos JSON within a hierarchy of buckets → scopes → collections, rather than databases and tables. Its query language, SQL++, is a superset of SQL capable of querying JSON structures – but it operates over keyspaces, not tables, and must contend with schema flexibility, mixed types, and nested document structures not present in the relational world.
This mismatch between the benchmark’s assumptions and Couchbase’s actual data model represents the central architectural challenge this work addresses.
Scope and Benchmark Filtering
Before any architectural work could begin, the benchmark was scoped appropriately. The full Spider2-Lite dataset contains 548 instances spanning BigQuery, Snowflake, Google Analytics, and SQLite backends. Only the 135 SQLite-based (“local”) instances were retained – these are the cases for which source data can be migrated to Couchbase, enabling faithful evaluation.
|
1 2 3 |
# Filtering to local instances only filtered = [l for l in lines if json.loads(l).get('instance_id', '').startswith('local')] # Result: 135 instances retained |
Architectural Adaptations
Three categories of architectural change were required to make the benchmark viable on Couchbase.
Relational-to-Document Data Model Transformation
The first challenge was translating the relational schema into Couchbase’s document model without losing the structural information that SQL++ queries depend on.
Design decision: Preserve the relational hierarchy using Couchbase’s native organizational primitives:

We deliberately avoided this, because doing so would invalidate the original benchmark queries. It ensures that SQL++ queries generated by Capella iQ can reference the same logical entities as the original SQL queries – just via a different keyspace syntax (E_commerce.spider2.orders em vez de pedidos).
The migration pipeline is intentionally two-staged:
|
1 2 3 4 5 |
SQLite (.sqlite) ↓ export_sqlite_to_json.py JSON Intermediate (inspectable, auditable) ↓ batch_import_to_couchbase.py Couchbase (bucket.scope.collection) |
The intermediate JSON layer is not merely a technical artifact – it is a critical quality gate. It allows human inspection and programmatic cleaning of the data before it enters Couchbase, which is not possible if migrating directly.
Type System Reconciliation
Relational databases typically enforce column-level type constraints. However, SQLite is a notable exception: its *type affinity* model allows columns declared with types such as NUMÉRICO to store values of different kinds, including strings and integers, within the same column. While this permissive behavior is valid within SQLite, it can introduce ambiguity and inconsistencies when queries are executed in systems that assume stronger typing. As a result, queries derived from SQLite-based benchmarks may surface type-related failures when evaluated on Couchbase SQL++ engine, which expect clearer type semantics at runtime.
When exported naively, these type inconsistencies carry forward into JSON. For example, an era column in a sports statistics table might contain [2.84, “”, 3.12, “”] – a mix of floats and empty strings.
Solução: O find_mixed_type_columns.py utility was built to detect and remediate this class of issue at the JSON layer, before import:
- Scans all JSON exports and classifies each column’s value types
- Identifies columns with incompatible mixing (e.g., empty_string + int)
- Replaces empty strings with nulo in numeric columns, making the data SQL++-compatible
- Generates automatic backups and supports a –dry-run mode for safe preview
Analysis across 30 JSON exports identified 77 columns requiring remediation across seven files. After cleaning, all files imported into Couchbase without type-related errors.
Query Language Adaptation via Capella iQ
The final and most significant adaptation is at the query generation layer. Standard text-to-SQL systems produce ANSI SQL. Capella iQ produces SQL++, which differs in keyspace syntax, some function names, and its ability to navigate nested JSON.
Rather than attempting to transpile existing SQL reference queries into SQL++, the evaluation framework uses Capella iQ itself as the query generation layer – feeding each natural language question directly to Capella iQ and evaluating the result of executing the generated SQL++ against Couchbase. The evaluation thus measures real-world system performance, not the quality of a transpilation layer.
For each benchmark instance, the pipeline:
- Enumerates all available keyspaces (bucket.scope.collection) from Couchbase.
- Provides this keyspace context to Capella iQ.
- Submits the natural language question.
- Receives and executes the generated SQL++.
- Persists results for evaluation.
Preserving Evaluation Integrity
Adapting the data and query layers would be insufficient if the evaluation methodology itself were compromised. Several measures were taken to ensure the evaluation remains faithful to the Spider2-Lite standard.
Result-Level Comparison
Rather than comparing the generated SQL++ text directly against the reference SQL — which would be invalid because the languages themselves differ — evaluation is performed at the **result level**. The output produced by executing the generated SQL++ against Couchbase is compared directly with the pre-computed output obtained by executing the reference SQL against the original SQLite database.
This design choice is critical for several reasons.
First, SQL and SQL++ are not syntactically or semantically identical languages. SQL++ is designed for semi-structured, JSON-based data and introduces constructs for navigating nested objects and arrays that do not exist in traditional SQL. Conversely, SQL assumes a flat relational schema. Because of these structural differences, a valid SQL query cannot simply be translated into an identical SQL++ string representation. Any text-level comparison would therefore penalize correct queries purely because they are written in a different language.
Second, query equivalence in databases is fundamentally semantic, not textual. Two queries can differ substantially in syntax yet produce identical results. For example, the same answer can be derived using joins versus subqueries, different aggregation strategies, or alternative filtering structures. Evaluating queries based on their textual similarity would incorrectly mark many correct solutions as wrong.
By evaluating the result sets produced by execution, the benchmark measures what actually matters: whether the system returns the correct answer. This makes the evaluation both language-agnostic and semantically faithful – a query is judged by what it produces, not by how closely its text resembles a reference query.
Multi-Variant Gold Standards
Some benchmark questions admit multiple equally valid result sets (e.g., different but correct orderings or aggregation groupings). The evaluation framework handles this by comparing the generated result against all available gold variants and taking the maximum score – a query passes if it matches qualquer acceptable answer.
Per-Instance Evaluation Metadata
Each benchmark instance carries evaluation metadata specifying:
- condition_cols – columns to use for sorting and matching
- ignore_order – whether row ordering should be considered
- toks – token complexity reference
This per-instance configuration ensures that numeric tolerance, column alignment, and ordering are applied consistently and correctly across all 135 test cases.
Architectural Summary
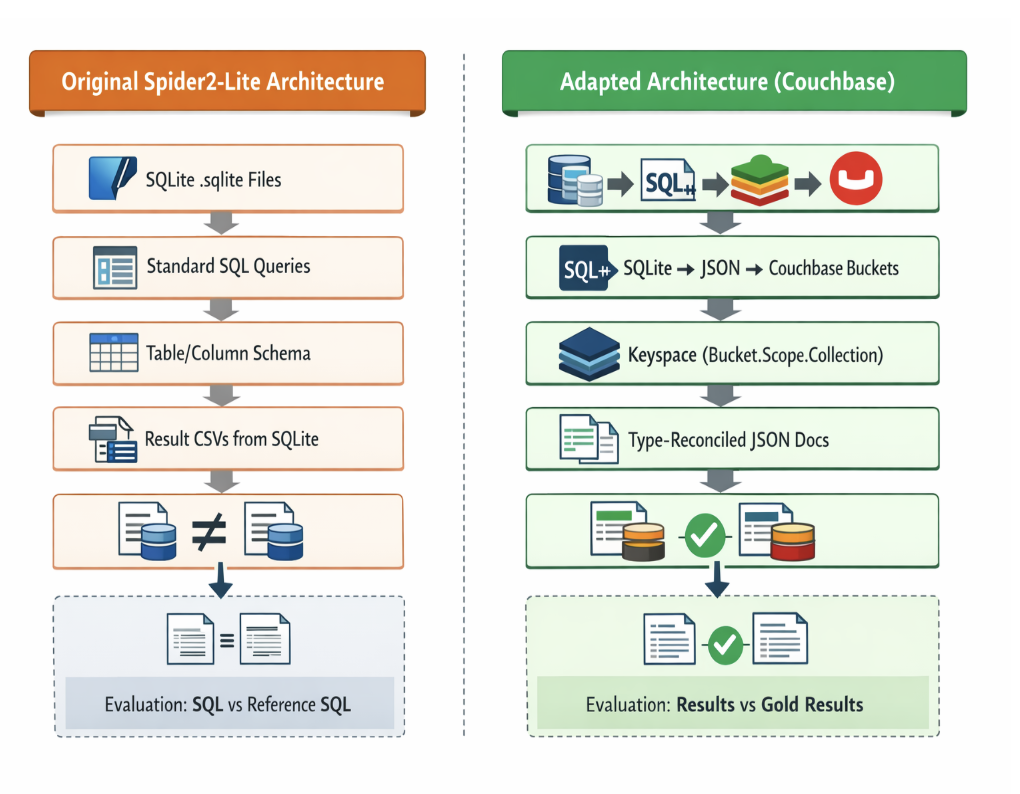
|
1 2 3 4 5 6 7 8 |
ORIGINAL SPIDER2-LITE ARCHITECTURE ADAPTED ARCHITECTURE (COUCHBASE) ───────────────────────────────── ───────────────────────────────────── SQLite .sqlite files SQLite → JSON → Couchbase Buckets Standard SQL reference queries SQL++ generated by Couchbase IQ Table/column schema Keyspace (bucket.scope.collection) Type-enforced columns Type-reconciled JSON documents Result CSVs from SQLite Result CSVs from Couchbase N1QL Evaluation: SQL vs reference SQL Evaluation: Results vs gold results |
The adapted architecture preserves every layer of the evaluation pipeline except the query language itself – which is exactly what is being evaluated.
Conclusão
This work demonstrates that industry-standard text-to-SQL benchmarks can be successfully and rigorously adapted to evaluate AI query systems operating on document-oriented databases. Although benchmarks such as Spider2-Lite were originally designed for relational systems, their underlying goal – measuring the ability of an AI system to translate natural language into correct database queries – remains equally relevant in modern semi-structured data environments.
Through a principled architectural adaptation – including relational-to-document data modeling, type-system reconciliation, and result-level evaluation across different query languages – the benchmark was executed on Couchbase while preserving the methodological integrity of the original evaluation framework. Rather than forcing document databases into a relational mold, this approach respects the native architecture of Couchbase and leverages SQL++ to operate directly on JSON documents and flexible schemas.
The results highlight a broader insight: modern AI query systems benefit significantly from operating on platforms designed for semi-structured data. Couchbase’s document model allows data to be stored in a form that more naturally reflects real-world application structures, while SQL++ provides the expressive power needed to query nested and heterogeneous data without complex relational transformations. When paired with Couchbase Capella iQ, this architecture enables natural language queries to be translated directly into executable SQL++ over native JSON datasets, reducing the impedance mismatch between how data is stored and how it is queried.
Taken together, this case study shows that Couchbase – combined with Capella iQ – provides a powerful foundation for AI-driven data access. By supporting flexible schemas, JSON-native querying, and intelligent query generation, the platform enables natural language interfaces to operate effectively over modern application data. The ability to run established benchmarks like Spider2-Lite on Couchbase further demonstrates that document databases can participate in rigorous evaluation frameworks while preserving the advantages of their native architecture.
Referências:
- Text-to-SQL Research Overview. Surveys and benchmarks evaluating natural language interfaces for databases.
- T. Yu et al., “Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task,” in Proc. EMNLP, 2018.
- “Spider2: A Benchmark for Complex and Realistic Text-to-SQL Tasks,” 2024.
- “Spider2-Lite: Lightweight Subset for Local Evaluation,” 2024. Curated subset designed for local execution and controlled evaluation environments.
- Couchbase Documentation. Couchbase Server Architecture and Data Model. Covers Buckets, Scopes, Collections, and JSON document storage.
- SQL++ (formerly N1QL): Couchbase Query Language Reference. Describes extensions over SQL for querying semi-structured JSON data.
- SQLite Documentation. Datatypes In SQLite Version 3. Explains type affinity and flexible typing behavior.
- Google BigQuery Documentation. Referenced as part of Spider2 backend environments.
- “Semantic Parsing: Concepts and Applications,” 2023.
- “Schema Generalization in Text-to-SQL Systems,” 2023.
