Couchbase Analytics
Unlock the power of real-time insights with Couchbase Analytics, the only JSON-native database for operational analytics and real-time write-back for smarter applications.
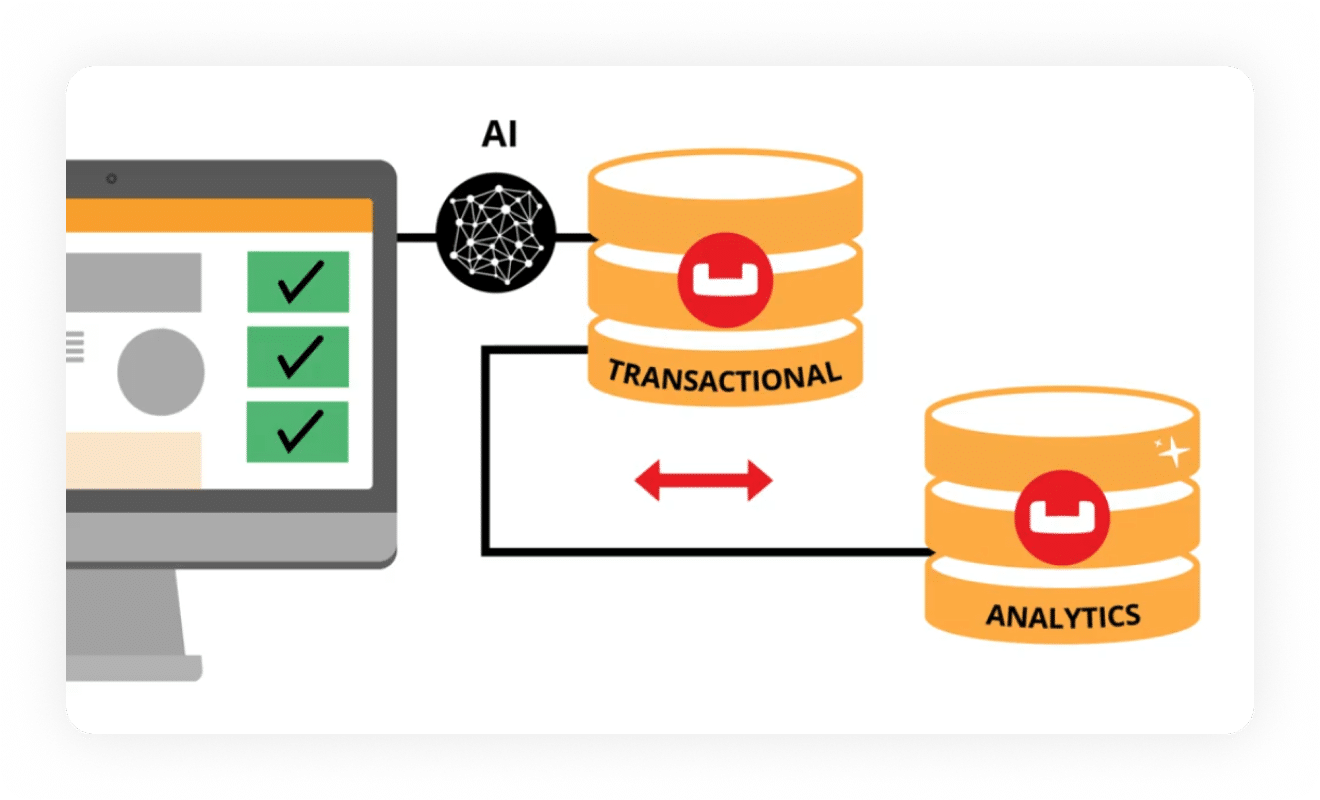



Advantages of Couchbase for real-time analytic solutions
Modern applications rely on operational data to create next-generation experiences, but enhancing them with dynamic analytics data makes them more personalized. Couchbase bridges the difficult data insight gap by converging operational data and real-time analytics in one platform that enables teams to build critical applications that drive real-time experiences, insights, and actions. As part of the operational data platform for AI, Couchbase Analytics brings that intelligence to everyone acting on your data –the people building experiences and the AI agents working alongside them.
Benefits of JSON analytics with Couchbase Analytics
JSON-native
Seamlessly perform real-time analysis on JSON data.
Unified ingestion
Combine data from multiple databases and flat files for broader analysis.
Developer independence
Perform ad hoc analysis faster, without overwhelming the BI team.
Better applications
Enhance experiences via derived data and real-time context for smarter AI responses and the agents acting on them.
Real-time analysis of JSON data
Zero ETL means teams can make informed decisions faster, reacting swiftly to application changes and reducing risk. SQL++ based JSON querying solves the challenges teams have with analytics in relational database management systems.
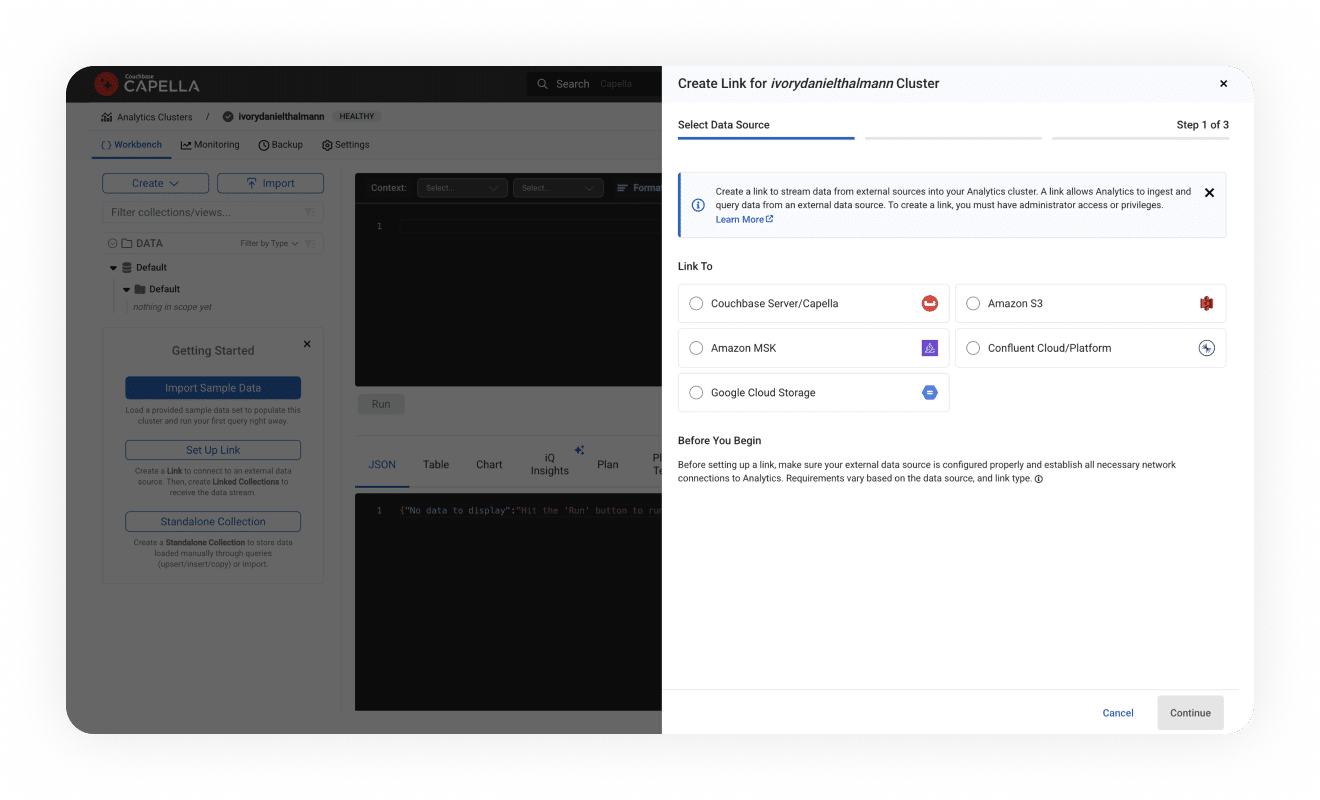
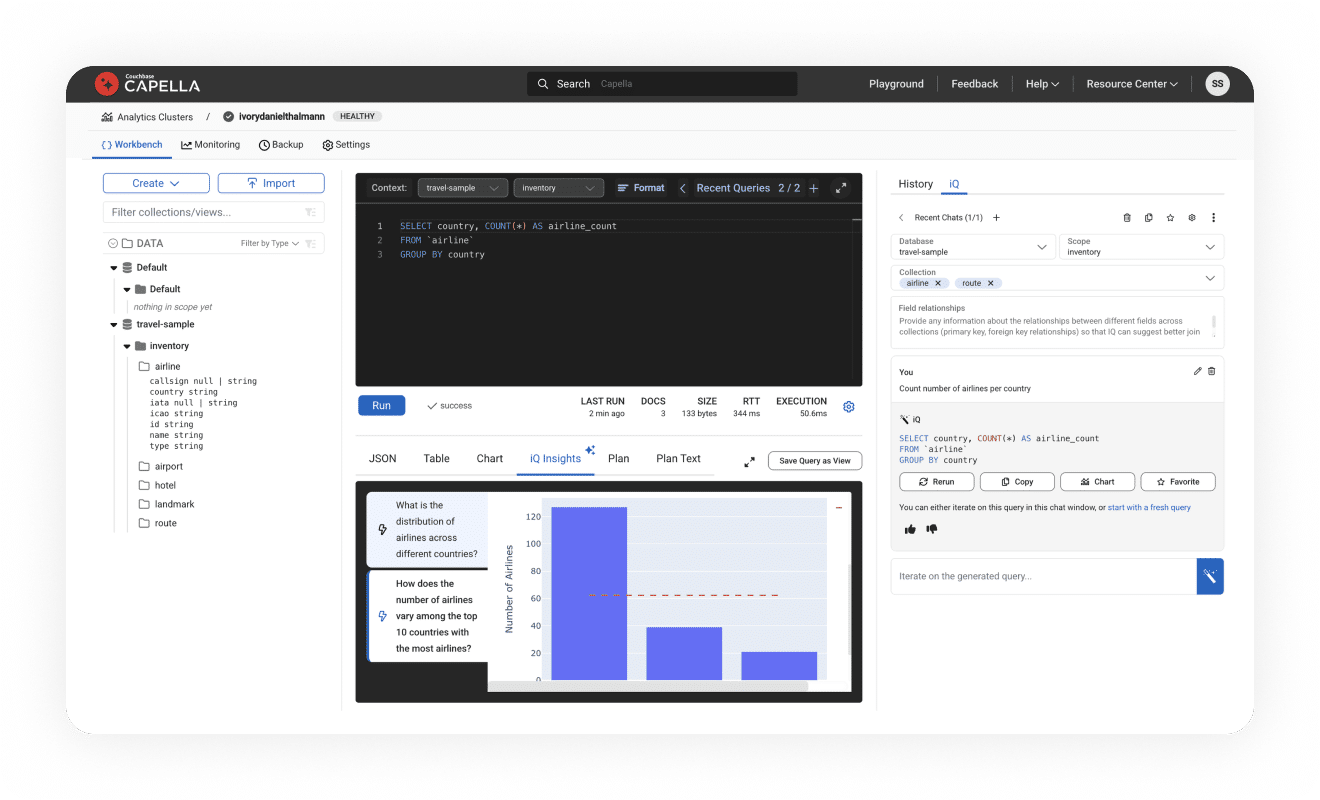
More control and independence
Developers perform ad hoc analysis faster without needing to define schema and in a conversational manner with Capella iQ.
Build critical applications
Utilize real-time metrics to drive action, improve applications, and enhance user experiences.
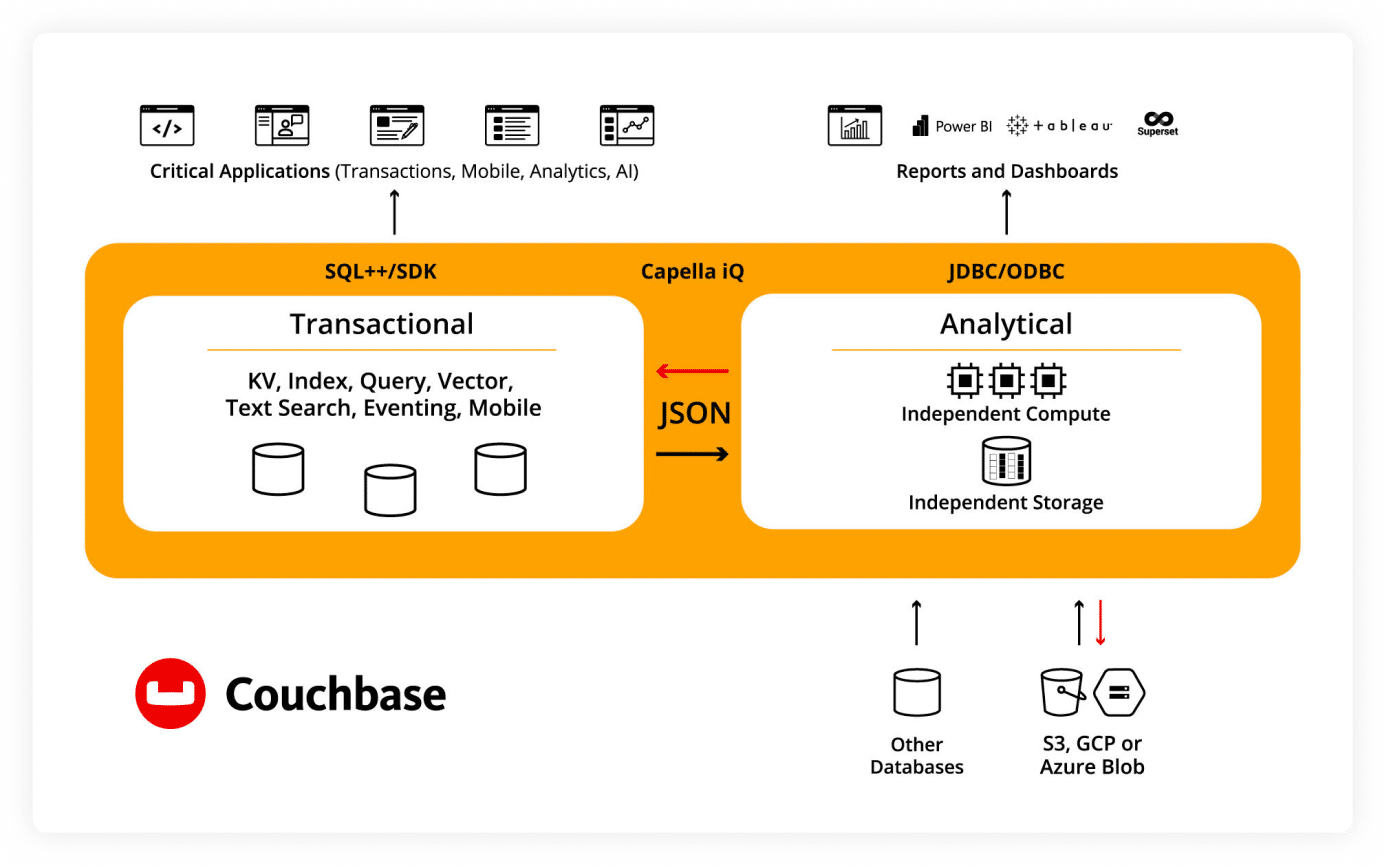
Single JSON-native platform
The only JSON-native data platform for both operations and real-time analytics services. Build robust apps faster, while saving time and costs.
What customers are saying
-


“Couchbase gives us the best of all worlds when it comes to managing customer marketing data.”
Cliff Miller, Enterprise Data Architect, Domino’s18K+
stores
90+
countries
-


“Couchbase is a trifecta of value. We get more features, save time, and spend less money all at once.”
Philip Lupercio, VP of Technology, BroadJump50%
reduction in overall storage needs
500%
improvement in query performance
-


“To set up a resilient implementation of Couchbase, it took us minutes. We stood up three servers, balanced the load, and instantly we were resilient.”
Robert Lawrence, Product Owner of Digital Catalysts Platforms, PG&E16M
customers
70K+
square mile service area
Explore related resources
-

Datasheet
Couchbase Analytics datasheet
-

Download
Get enterprise analytics for self-managed deployments
-

Documentation
Read the docs to learn more about Capella Analytics.
Couchbase Analytics FAQ
Get quick answers to questions about Couchbase’s real-time JSON analytics database.
Couchbase Analytics is a real-time, JSON-native analytics engine built into Couchbase Capella. It queries operational data directly with no ETL pipelines, schemas, or separate infrastructure required.
No. Couchbase Analytics ingests and queries JSON data in real time without ETL pipelines or predefined schemas, making operational data instantly available for analysis.
Yes. Couchbase Analytics supports real-time write-back, allowing analytical findings to flow directly into the operational data store for immediate use in live applications.
Couchbase Analytics connects to Tableau, Power BI, and Looker through native JDBC and ODBC connectors, enabling visualization of operational JSON data in familiar BI tools.
Couchbase Analytics uses columnar storage, massively parallel processing, and compute-storage separation to deliver accelerated query performance across large, complex datasets.
Couchbase Enterprise Analytics (self-managed) queries Apache Iceberg tables. Run SQL++ on lakehouse data in place with zero ETL.