
GenAI technologies are definitely a trending item in 2023 and 2024, and because I work for Tikal, which publishes its own annual technology radar and trends report, LLM and genAI did not escape my attention. As a developer myself, I often consult generative AI chatbots to help me solve all kinds of TypeScript errors and mysterious linting issues, I use genAI assistive tools in my IDE and to improve my PRs. This tech is possibly life changing.
As technical people and definitely us software developers this new trend opens the opportunity to integrate these capabilities into all the projects we work on, and I see my friends and colleagues exploring these options, which led me to the decision – I should do it, too!
And I had just the project:
I am an amateur dancer who dances in an amateur dance troupe, I often wonder how amateur artists can explore the wide world of cultural events locally and worldwide to be able to reach out and maybe get that desired invitation to come perform. We don’t have the resources, connections and knowledge of everything available. Sure, there are search engines, and specialized websites, but you need to know what and how to search for it, so I decided to use genAI to get recommendations.
Step 1 – Can it be done?
Checking the feasibility of a recommendation engine using one of the LLMs, included opening accounts on several genAI chat services and asking them the same question:
We are an amateur Israeli folk dancing group, including dancers in wheelchairs. We are looking for cultural and folklore events and festivals in Europe to reach out to about the option of us getting an invitation to perform, provided we cover our expenses. Can you please recommend a few?
The results in H1 of 2024 varied between the different chat services:
- Directed me to dedicated websites which I could query for results
- Gave me actual results
From those who returned results, I rated the quality of the results by relevance and accuracy, and ended up with OpenAI GPT-3 as the choice.
Step 2 – Is it enough?
Remembering that even one of the chat assistants in Step 1 suggested I check other websites, what if I could embed some of that data in the results?
Considering that I’m also dependent on whomever trained the model and when it was trained, I wanted my recommendations to be based on more data sources and I knew it can be done with RAG. First of all, what is RAG?
Retrieval Augmented Generation (RAG)
RAG is the process of enriching and optimizing the output you receive from LLM by adding “external” data. If I can add results based on the same search on external data sources (from dedicated websites) I can expand the variety of the results my application will provide.
To do that you will need:
- External data sources – For my experiment I created a trial account for predictHQ’s events API
- Store my external data is an engine that allows similarity search and not an exact match
Making the data accessible for RAG
Once you’re done looking into the data, what it looks like, and what features it holds, it is time for you to select the data features you’d like to use, and make them usable for RAG.
To allow a similarity search we would need to transform our data into a format that is searchable and comparable. Because we are not looking for exact matches, but similar matches, there are two very common techniques for that:
| RAG technique | Details |
| Vector search (also known as common RAG) | The pieces of information and the question are transformed to vectors of numbers (floating points).
Mathematical computations are used to determine to similarity between the question and the data |
| GraphRAG | The pieces of information and the question are transformed into graph vertices and edges.
The graph relations are compared for similarity |
The process of creating the representation of the data is called embedding, in this article we will focus on vector search.
Similarity Metric
There are 3 common options (in a nutshell):
- Dot product: Calculating the similarity based on the product of the values in each vector
- Cosine: Based on the angle between the vectors
- L2_norm: Euclidean distance between the vectors, based on the angle between the vectors and the length of each vector
Read more about the vector similarity options.
Step 3 – How do I do this?
Before we dive into how we’re going to this and some actual code and screenshots, let’s look at how such architecture would be built, and how Couchbase comes into the picture:
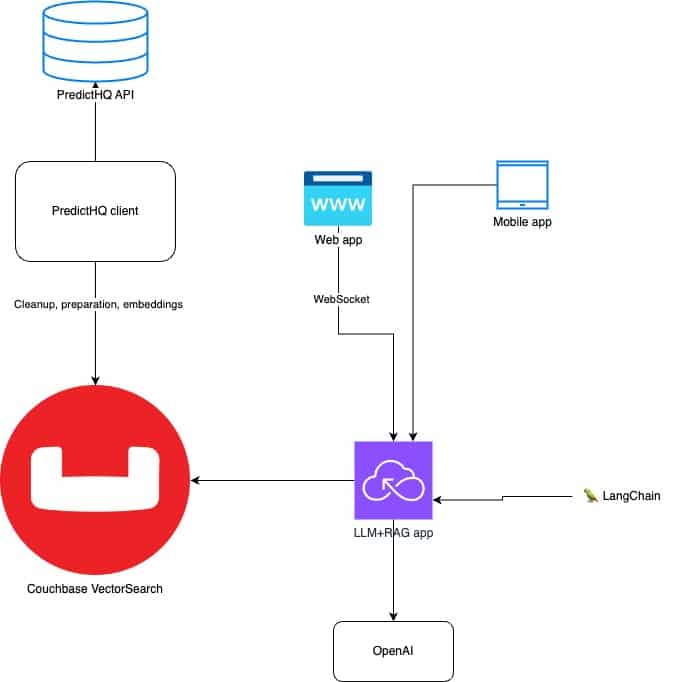
What this means in practice is:
- Ingestion app to:
- Fetch data from the external API
- Create vector embeddings
- Load data into a Couchbase collection
- Create a vector search index in Couchbase
- Prompt application to:
- Ask Couchbase data for results
- Add the vector search results to the LLM prompt as context
- Return the cohesive results to users
Ingestion application
This process was probably the longest, I spent time creating embeddings to different fields and in different formats. For simplicity I eventually chose to only use the geographical information I collected:
|
1 2 3 4 5 |
from langchain_openai import OpenAIEmbeddings embeddings_model = OpenAIEmbeddings(model=“text-embedding-3-small”) text = f“Geo Info: {row[‘geo_info’]}” embedding = embeddings_model.embed_query(text) |
To create the embedding I chose to use textual embeddings as a start, meaning “comparing” text representation to text representation. The embedding itself includes roughly 1500 numbers (that is the small one).
The code itself is not extremely complex, however it can be time consuming, to create 1 embedding for 5000 events took approximately 1 hour on my M1 16 GB MacBook pro.
The full code using pandas2 can be found in this repository.
Couchbase collection and search index
To be able to search for similar data between the question and the results we’ve prepared based on an external API, we will-
- Create a Couchbase collection
- Upload the prepared data to a Couchbase collection including the embeddings
- Create a search index on the embeddings fields choosing the vector similarity algorithm to compare vectors
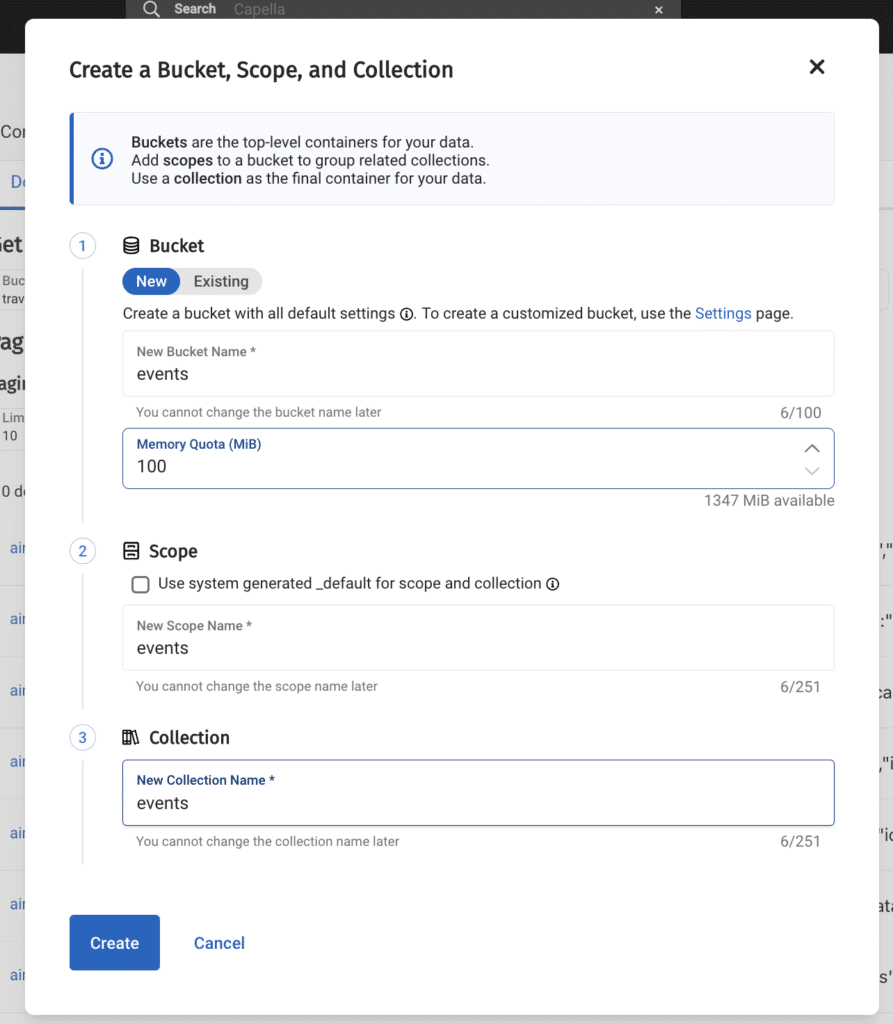
New Couchbase collection
For my application I chose to use the hosted Couchbase service – Capella, the setup is very easy. I signed up, chose the Cloud service and created a new project.

Clicking on my project and navigating to the Data tools tab, I can now create a new collection for the data I prepared:
To upload the data I prepared there are several options: since the size of the file was rather large I chose to use the cbimport utility to do so.
|
1 |
./cbimport json —cluster couchbases://<yourcluster> –username <your user> –password <your password> –bucket <bucket> –scope-collection-exp “<scope>.<collection>” –dataset for_collection.json –generate-key ‘%id%’ –cacert <path to couchbase certificate> –format lines |
Notice that I chose the ID field from the JSON documents to be the document key in the collection.
Remember that prior to doing so, you need to:
- Create database access user/password with write privilege as a minimum
- Open the cluster for calls from your host
- Download a certificate for the cluster
The inferred document schema shows that the embedding field as been created with the type of array of numbers:

To allow vector similarity search, let us create the search index by navigating to the Search tab.
We should obviously select the embedding field for the search index, but notice there are more parameters to set:
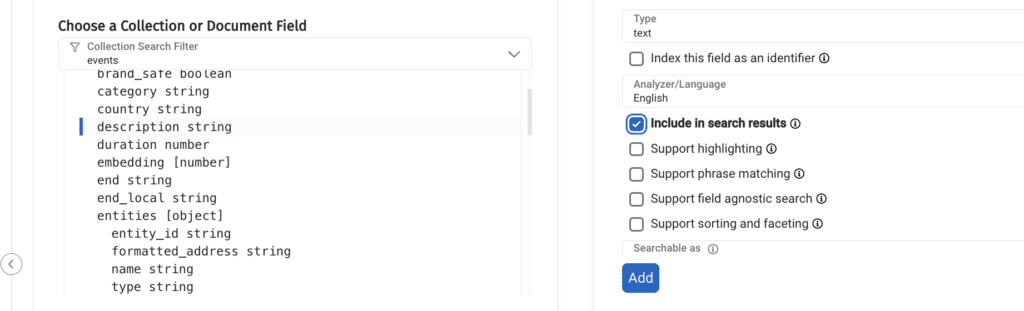
We have already discussed what the similarity metric is, just note that Couchbase support l2_norm (i.e. Euclidean distance) and dot product, I chose “dot product”, which may be more beneficial for my recommendation system.
The next step is choosing additional fields from the documents that would be returned whenever a vector is dimmed similar to the question:

If you will not add at least one field, your application will fail because there will not be any returned data.
There it is, the index fields selection:
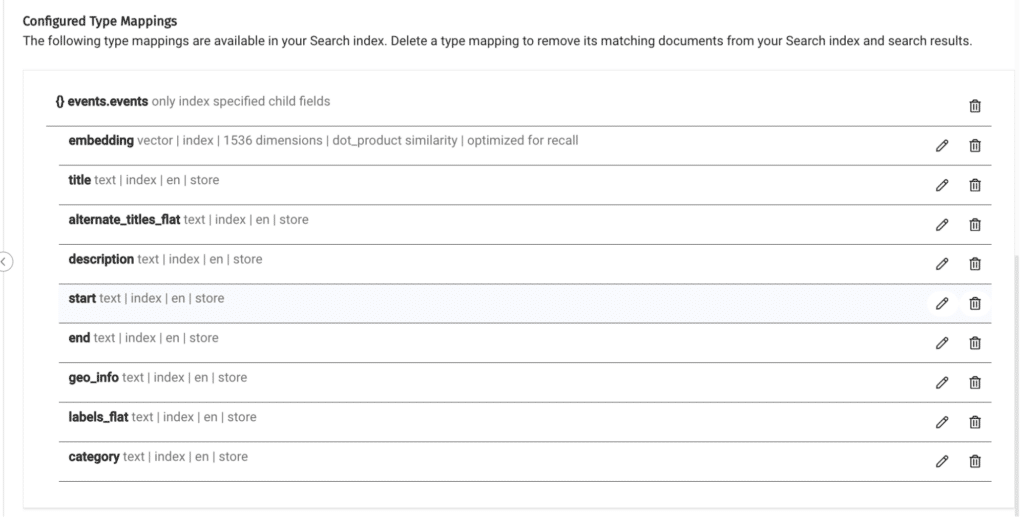
We have reached a crucial point in our project, we can now start running similarity search on the data we prepared, but you may not have a working similarity search at your first attempt. I will outline a few tips to get results from your similarity search or to check why you are not getting results:
- Make sure your embeddings technique, when creating the data and preparing a search are identical
- Start with a simple and predictable format for the information you want to compare. For example <City>, <State>, <Country>
- Make sure you don’t have extra information that is accidentally appended to the data you’re creating embeddings for (for example I had line breaks)
- Make sure exact match search works by:
- Searching for the exact data you created embeddings for
- Compare the embedding vector to make sure that identical embeddings are created in the generation and search part (debugging will be useful here). If there is a difference go back to steps 1-3
Once you have a working similarity search, gradually add more fields, change formats, embeddings and anything else you feel is missing.
Remember any change to the embeddings means:
- Recreating the embeddings
- Loading the changes data to a truncated collection
- Changing the search index if needed
- Changing the code is needed
These steps may be time consuming, especially the embeddings creation, so you may want to start with:
- A small portion of your documents
- A small/fast embedding technique
LLM and RAG application
What our application needs to do is:
- Ask Couchbase to find results similar to the user question
- Add the results to the context to the prompt question to the LLM
- Ask the LLM a question
For simplicity I created this code in Python as a Jupyter notebook which you can find in this repository. I used the following libraries to accomplish this:
- Couchbase: Connect and authenticate to my Capella cluster
- LangChain: a framework for developing applications powered by large language models (LLMs), for:
- Embeddings
- Using Couchbase as a vector store
- “Chatting” with OpenAI
- LangGraph: A framework to building a stateful, multi-actor LLM applications, for creating a flow of the LLM application
If you’ve been reading about, and even trying to build your own LLM application you’re probably somewhat familiar with LangChain, it is a set of libraries that allows you to write, build, deploy and monitor an application, it has many agents and extensions that allow you to integrate different parts into your code, such as a 3rd party API, a database, a web search and many more.
Lately, I also learned about LangGraph from the home of LangChain, which allows you as a developer to build more complex topologies of the LLM application with conditions, loops (the graph doesn’t have to be a DAG!), user interaction, and perhaps the most sought out feature: Keeping state.
Before we look at the code let’s take a look at the environment file (.env) to see what credentials and other confidential data we need:
|
1 2 3 4 5 6 7 8 9 10 11 |
LANGSMITH_KEY=langsmithkey OPENAI_API_KEY=openaikey LANGCHAIN_PROJECT=myproject COUCHBASE_CONNECTION_STRING=couchbase://mycluster.com COUCHBASE_USER=myuser COUCHBASE_PASS=mypass COUCHBASE_BUCKET=mybucket COUCHBASE_SCOPE=myscope COUCHBASE_COLLECTION=mycollection COUCHBASE_SEARCH_INDEX=mysearchindex LANGCHAIN_API_KEY=langchainapikey |
The state for each graph node is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from langgraph.graph import add_messages, StateGraph from typing_extensions import TypedDict from typing import Annotated from langgraph.checkpoint.sqlite import SqliteSaver class State(TypedDict): # Messages have the type “list”. The `add_messages` function # in the annotation defines how this state key should be updated # (in this case, it appends messages to the list, rather than overwriting them) messages: Annotated[list, add_messages] event_type: str location: str labels: str graph_builder = StateGraph(State) |
It is important to note unless you define a reducer the state will be overwritten between each graph node, the messages member in the state class has a reducer which will append the new messages to the list.
To connect to Couchbase and use it as a vector store for the LLM application, we authenticate to the cluster, and pass the cluster connection to the LangChain object for vector store:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from langchain_openai import OpenAIEmbeddings import os from couchbase.cluster import Cluster from couchbase.options import ClusterOptions from couchbase.auth import PasswordAuthenticator from langchain_couchbase import CouchbaseVectorStore COUCHBASE_CONNECTION_STRING = os.environ[“COUCHBASE_CONNECTION_STRING”] COUCH_USER = os.environ[“COUCHBASE_USER”] COUCH_PASS = os.environ[“COUCHBASE_PASS”] BUCKET_NAME = os.environ[“COUCHBASE_BUCKET”] SCOPE_NAME = os.environ[“COUCHBASE_SCOPE”] COLLECTION_NAME = os.environ[“COUCHBASE_COLLECTION”] SEARCH_INDEX_NAME = os.environ[“COUCHBASE_SEARCH_INDEX”] auth = PasswordAuthenticator(COUCH_USER, COUCH_PASS) options = ClusterOptions(auth) cluster = Cluster(COUCHBASE_CONNECTION_STRING, options) embedding = OpenAIEmbeddings(model=“text-embedding-3-small”) vector_store = CouchbaseVectorStore( cluster=cluster, bucket_name=BUCKET_NAME, scope_name=SCOPE_NAME, collection_name=COLLECTION_NAME, embedding=embedding, index_name=SEARCH_INDEX_NAME, ) |
There are two important details to keep in mind:
- The embedding in the application must be identical to the one used in the ingestion part
- The default embedding field name is ‘embedding’, if the name of the respective field is different in your search index you need to set it during the instantiation of CouchbaseVectorStore (embedding_key)
Right now, you are ready to write your LangGraph application and to use Couchbase as a vector store. Let’s put it together: each graph needs nodes, start point and directed edges.
Our graph will fetch data from the vector store and continue to add this information into the LLM prompt context.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI llm = ChatOpenAI(model=“gpt-3.5-turbo”) template = “”“You are a helpful bot that serves the purpose of finding events for artists looking for venues in the USA. If you cannot answer based on the context provided, respond with a generic answer. Answer the question as truthfully as possible using the context below: {context} Please also format the result in Markdown format. Question: {question}”“” prompt = ChatPromptTemplate.from_template(template) generation_chain = prompt | llm | StrOutputParser() def chatbot(state: State): response = generation_chain.invoke({“context”: state[‘messages’], “question”: f“We are a {state[‘event_type’]} amateur group looking for {state[‘labels’]} festivals in {state[‘location’]}, can you please recommend some for us to reach out to?”}) state[‘messages’].append(response) return state def search_couchbase(state: State): query = f“Geo Info: {state[‘location’]}” retriever = vector_store.as_retriever() results = retriever.invoke(query) for result in results: text = f“Title: {result.metadata[‘title’]}/{result.metadata[‘alternate_titles_flat’]} – {result.metadata[‘description’]} from {result.metadata[‘start’]} to {result.metadata[‘end’]}, location {result.metadata[‘geo_info’]}. Labels {result.metadata[‘labels_flat’]}, category {result.metadata[‘category’]}” state[‘messages’].append(text) return state graph_builder.add_node(“vector_search”, search_couchbase) graph_builder.add_node(“chatbot”, chatbot) graph_builder.set_entry_point(“vector_search”) graph_builder.add_edge(“vector_search”, “chatbot”) graph_builder.set_finish_point(“chatbot”) memory = SqliteSaver.from_conn_string(“:memory:”) graph = graph_builder.compile(checkpointer=memory) |
It translates in the code above to two nodes:
- vector_search (entry point)
- chatbot (finish point)
Since a picture is worth a thousand words, I used the following code to visualize the graph for you:
|
1 2 3 4 5 6 7 8 9 10 |
from IPython.display import Image, display from langchain_core.runnables.graph import CurveStyle, MermaidDrawMethod, NodeStyles display( Image( graph.get_graph().draw_mermaid_png( draw_method=MermaidDrawMethod.API, ) ) ) |
Which resulted in the following drawing:
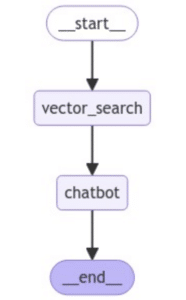
For more visualization options in langGraph, see this Jupyter notebook by LangGraph.
Asking the vector store means searching for data with similar location, you may notice that the format of the query is the same as in the embedded text, the results are added to the state to be used in the next node.
The chatbot node takes the information from the messages and embeds it into the prompt question to the LLM.
Note that the state is kept in the in-memory database sqlite. To use the graph feel free to use the following sample:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from random import randint from IPython.core.display import Markdown session_id = randint(1, 10000) config = {“configurable”: {“thread_id”: session_id}} input_location = “kansas” input_category = “jaz” input_labels = “grange” # Stream the graph, each output will be printed when ready for event in graph.stream({“event_type”: input_category, “location”: input_location, “labels”: input_labels}, config): for value in event.values(): if len(value[‘messages’]) > 0: display(Markdown(value[‘messages’][–1])) |
And there you are, you’ve created an LLM application to recommend culture events for amateur groups to reach out to asking for invitations.
Summary
Getting started with LLM applications is exciting and in my humble opinion, as a fun, exciting and doable ramp-up due to its prompt nature, however, making our application better and more robust hides more challenges.
In this article, I focused on the challenge of leveraging the knowledge of our mode with external data via the technique or RAG and how you can leverage Couchbase to do so.
It is important to remember that creating embeddings that the LLM application will find in the vector search, may not work at your first attempt. Check for formatting, try to start with simple embeddings and use debugging as much as possible.
I also demonstrated the capabilities of LangChain’s LangGraph which allows you to create complex decisions and flows in the LLM application.
Enjoy your journey with LLM applications.
댓글 남기기
댓글을 달기 위해서는 로그인해야합니다.