What is a vector database?
At a high level, a vector database is a specialized system for storing, managing, and querying data as high-dimensional vectors. Unlike traditional relational databases that store structured data in rows and columns, or NoSQL databases that only handle JSON documents, vector databases are built to handle mathematical representations of data.
In this context, data, whether it’s text, an image, or an audio file, is converted into a list of numbers called a vector. These numbers represent the semantic meaning of the content. For example, in a vector space, the words “king” and “queen” would be positioned closer together mathematically than “king” and “apple,” because they share similar contexts.
Positioning vector databases within your architecture is a strategic move. They sit alongside your existing transactional and analytical databases to provide the long-term memory and contextual retrieval capabilities required by AI models. They bridge the gap between your raw enterprise data and the cognitive capabilities of modern AI.
How vector databases work
To understand the value of vector databases, we need to look under the hood at two core concepts: embeddings and similarity search.
Overview of embeddings and similarity search
Embeddings are the vector representations mentioned earlier. They’re generated by AI models (like OpenAI’s GPT or open-source equivalents) that process data and transform it into a dense array of floating-point numbers. These embeddings capture the essence of the data.
Once data is stored as vectors, the database doesn’t just look for exact matches. Instead, it performs a similarity search by calculating the distance between the query vector (what the user is looking for) and the stored vectors. The closer the vectors are in their multidimensional space, the more relevant the results.
Indexing and nearest-neighbor search
Searching through millions or billions of vectors linearly would be incredibly slow and computationally expensive. To solve this, vector databases use specialized indexing algorithms, such as Hierarchical Navigable Small World (HNSW) or Inverted File Index (IVF). The resulting indices organize vectors so the database can perform ANN searches. These searches allow the system to find the most relevant results with extreme speed and high accuracy, even at a massive scale.
Contrast with traditional keyword-based search
Traditional search relies on lexical matching. If a user searches for “automobile,” a keyword engine looks for the exact string “automobile.” It might miss documents containing “car,” “vehicle,” or “sedan” unless complex synonym lists are manually maintained.
Vector search, by contrast, understands that “automobile” and “car” are semantically identical. It retrieves results based on meaning, not just spelling. This shift from what the user typed to what the user meant allows organizations to drastically improve the user experience and the utility of their internal knowledge bases.
Why vector databases are critical for AI applications
For IT leaders, adopting vector databases is often driven by the limitations of existing stacks for handling AI workloads.
Semantic understanding vs. lexical matching
As noted, lexical matching fails when intent is ambiguous or when vocabulary differs between the query and the source data. In a customer support scenario, for instance, a user might describe a problem using nontechnical language. A keyword search fails, but a vector search succeeds because it matches the problem description to the technical solution based on semantic similarity. This leads to faster resolution times and higher customer satisfaction.
Scalability, performance, and real-time inference
AI applications, especially customer-facing ones, demand low latency. When a user interacts with a chatbot or a search bar, they expect instant results. Traditional databases often struggle to perform complex similarity calculations in real time, but vector databases are engineered specifically for this query pattern and provide the high throughput and low latency required for production AI workloads.
Connecting to production AI workloads
Vector databases serve as the connective tissue between your proprietary data and general-purpose LLMs. An LLM might be smart, but it doesn’t know your company’s private data, latest product specs, or customer history. By storing your proprietary data in a vector database, you can provide the AI model with relevant context in real time. This capability is essential for deploying AI that’s specific to your business needs.
Vector database use cases
Here are some examples of how vector databases are used across industries:
Semantic search
This is the most direct application. Organizations can upgrade their internal search engines to support natural language queries for purposes such as employee knowledge bases, legal document discovery, and e-commerce product catalogs.
- Benefit: Employees increase efficiency by finding information faster. Customers find products more easily, which increases conversion rates.
RAG
RAG is currently the primary driver for enterprise vector database adoption. In a RAG architecture, when a user asks an AI model a question, the system first queries the vector database to find relevant company documents. It then sends both the question and the documents to the LLM.
- Benefit: The AI generates an answer based on your own trusted data, significantly reducing the risk of hallucinations and ensuring compliance.
Recommendation systems
Vector databases excel at finding “items like this.” By representing user behavior and product attributes as vectors, systems can instantly recommend content, products, or media that align with a user’s interests.
- Benefit: Highly personalized experiences drive engagement and revenue without the need for complex, predefined rules engines.
Chatbots and virtual assistants
Chatbots need context to be effective. Vector databases allow virtual assistants to recall past conversations or pull relevant support articles instantly.
- Benefit: Automated support actually feels helpful, while deflecting tickets from human agents and lowering support costs.
Anomaly and similarity detection
Because vector databases measure distance, they’re excellent at spotting outliers. If a new data point (like a financial transaction or network login pattern) is vectorially distant from established normal clusters, it can be flagged as an anomaly. Conversely, vector databases can identify duplicates or near-duplicates in massive datasets.
- Benefit: Enhanced security and fraud detection capabilities evolve as attack patterns change.
Image, audio, and multimodal search
Vectors aren’t limited to text. You can also generate embeddings for images, audio, and video. This allows users to search for an image by describing it (“show me a red sports car on a beach”) or by uploading a similar image.
- Benefit: Opens up new avenues for digital asset management and rich media discovery.
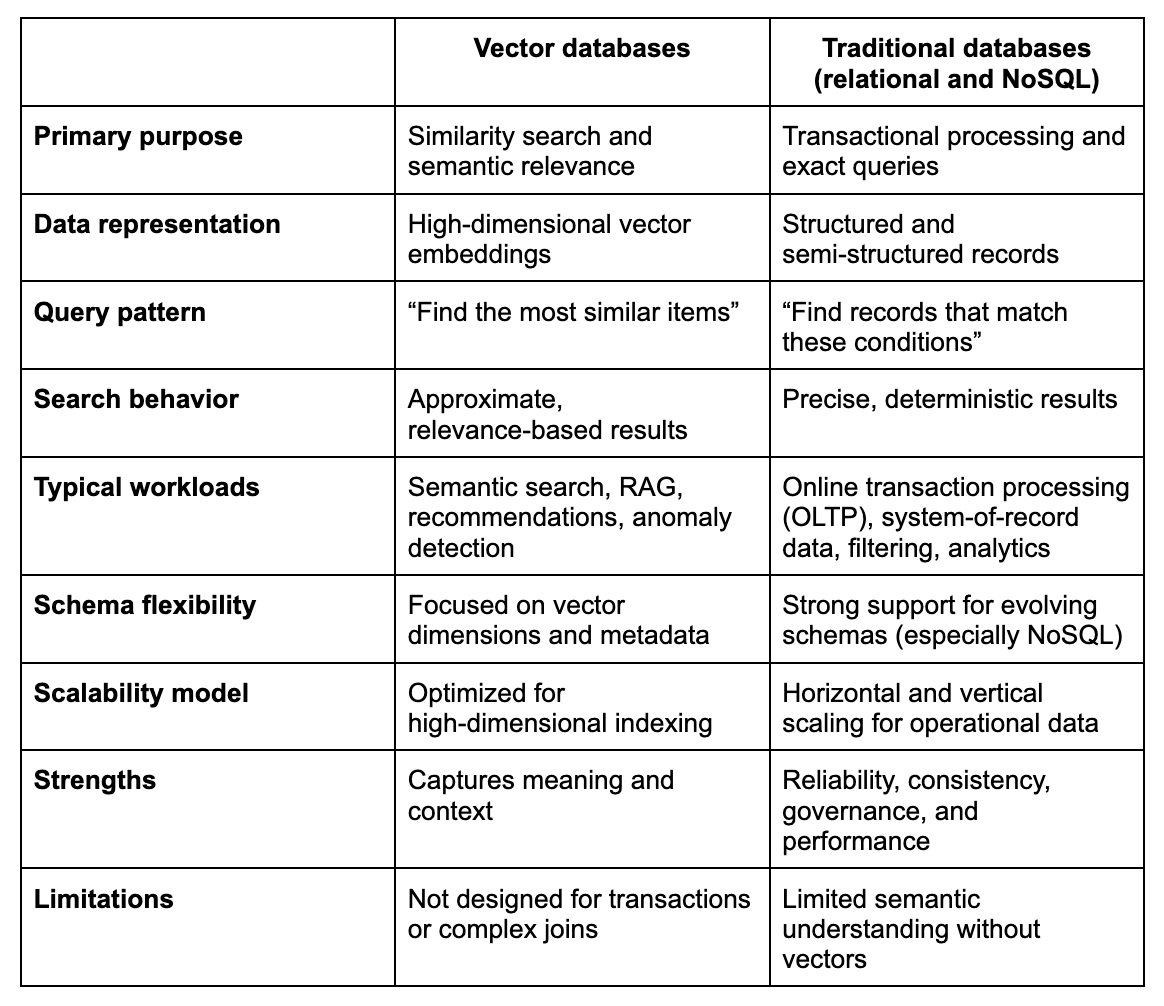
Vector databases vs. traditional databases
It’s important to understand how vector databases differ from traditional databases, and where each fits in a modern architecture. Each is optimized for different types of workloads, and the most effective architectures often use them together rather than choosing one over the other. This chart summarizes their key differences, including strengths and weaknesses:
When to use vector databases, traditional databases, or both
Use a vector database when your primary requirement is semantic similarity, such as powering natural-language search, recommendations, or RAG. These use cases depend on understanding meaning and context rather than exact matches.
Use a traditional database when your application depends on transactional integrity, structured queries, access control, and predictable performance. Relational and NoSQL databases remain the backbone for operational systems and systems of record.
Use both when building production AI applications. In these architectures, traditional databases store authoritative application data, while vector search enables intelligent, context-aware experiences on top of it. For NoSQL platforms like Couchbase, combining flexible data models with vector capabilities allows IT teams to support AI workloads without fragmenting their data stack or compromising governance and scalability.
Architectural considerations for vector search
Deploying a vector database requires careful planning to ensure it integrates seamlessly with your existing cloud and data infrastructure.
Data ingestion and embedding pipelines
You need a robust pipeline to convert your raw data into vectors. This involves selecting an embedding model (such as an OpenAI, Cohere, or Hugging Face model) and automating the process so that as new data enters your system, it’s vectorized and indexed.
Latency, scale, and consistency requirements
Consider the scale of your dataset. Indexing millions of vectors requires significant memory and compute resources. You must evaluate whether you need a fully managed cloud database-as-a-service (DBaaS) solution to handle this scaling overhead, or whether an on-premises deployment is required for regulatory compliance.
Integration with application and AI stacks
Your vector database must play nice with your orchestration frameworks (like LangChain or LlamaIndex) and your API layer. Ensure the solution you choose has robust SDKs and integrates easily with the languages your development teams already use, such as Python or JavaScript.
Key takeaways and related resources
Vector databases are the engine room of the generative AI revolution, changing how enterprises store, search for, and use their data. By moving from keyword matching to semantic understanding, IT leaders can unlock use cases that drive efficiency, innovation, and competitive advantage.
Key takeaways
- Context over keywords: Vector databases enable systems to understand the intent and meaning behind data, not just the text itself.
- RAG is the killer app: Retrieval-augmented generation uses your data to empower LLMs with domain-specific knowledge.
- Scalability is key: Vector databases are architected to handle the massive computational load of similarity search at production speeds.
- Beyond text: Vector search applies equally to images, audio, and video, enabling multimodal applications.
- Complementary tech: Vector databases sit alongside, not in place of, your existing databases.
- Real-time value: Vector databases enable real-time personalization and inference, which is critical for modern customer experiences.
- Future-proofing: Adopting vector search now prepares your infrastructure for the next wave of AI advancements.
To learn more about vector databases, you can visit the following resources:
Related resources
- Get Started With Couchbase Vector Search in 5 Minutes – Blog
- Vector Search Database – Scalable, Enterprise-Level Solutions – Products
- Supercharge Your RAG Application With Couchbase Vector Search and Unstructured.io – Blog
- Single Platform, Multi-Purpose Couchbase: Vector Search, Geospatial, SQL++, and More – Blog
- Building Smarter Agents: How Vector Search Drives Semantic Intelligence – Blog
- Vector Database vs. Graph Database: Differences & Similarities – Blog
FAQs
When should an organization add a vector database to its existing data stack? You should consider adding a vector database when you’re building AI features (such as semantic search, recommendation engines, or LLM-powered chatbots) that require handling unstructured data or retrieving context based on meaning rather than exact keywords.
What are the most common enterprise use cases for vector databases in production? The most common use cases are RAG for powering internal knowledge bots and customer support agents, followed closely by semantic search for e-commerce and content platforms.
How do performance and latency requirements vary across vector database use cases? User-facing applications like search bars and chatbots require extremely low latency (often under 100 ms) to maintain a good user experience. Background processes like duplicate detection or offline recommendations can tolerate higher latency but often require higher throughput.
How do data freshness and update frequency impact vector-based applications? High-frequency updates can challenge vector indexes, which often need to be rebuilt or optimized to incorporate new data. If your application relies on real-time news or stock data, you need a vector database optimized for real-time ingestion and indexing.
Can vector databases support enterprise requirements like filtering, security, and access control? Yes. Enterprise-grade vector databases now support filtered search, allowing you to combine semantic queries with metadata filters (e.g., “Find contracts similar to this one, but only from 2025”). They also offer role-based access control (RBAC) and encryption to meet security standards.
What metrics should teams use to measure the success of vector database use cases? Key metrics include Recall@K (how often the relevant item appears in the top K results) and query latency (response time). For business outcomes, success is measured by the click-through rate (CTR) for search results or the deflection rate for support chatbots.
댓글 남기기
댓글을 달기 위해서는 로그인해야합니다.