El objetivo de la informática es el conocimiento, no los números. - Richard Hamming
La espiral de dirigir el negocio, analizar qué cambiar y a qué cambiar, y luego cambiar el negocio es eterna. Si haces el análisis correcto, tu espiral aumentará. Si no, caerás en espiral.
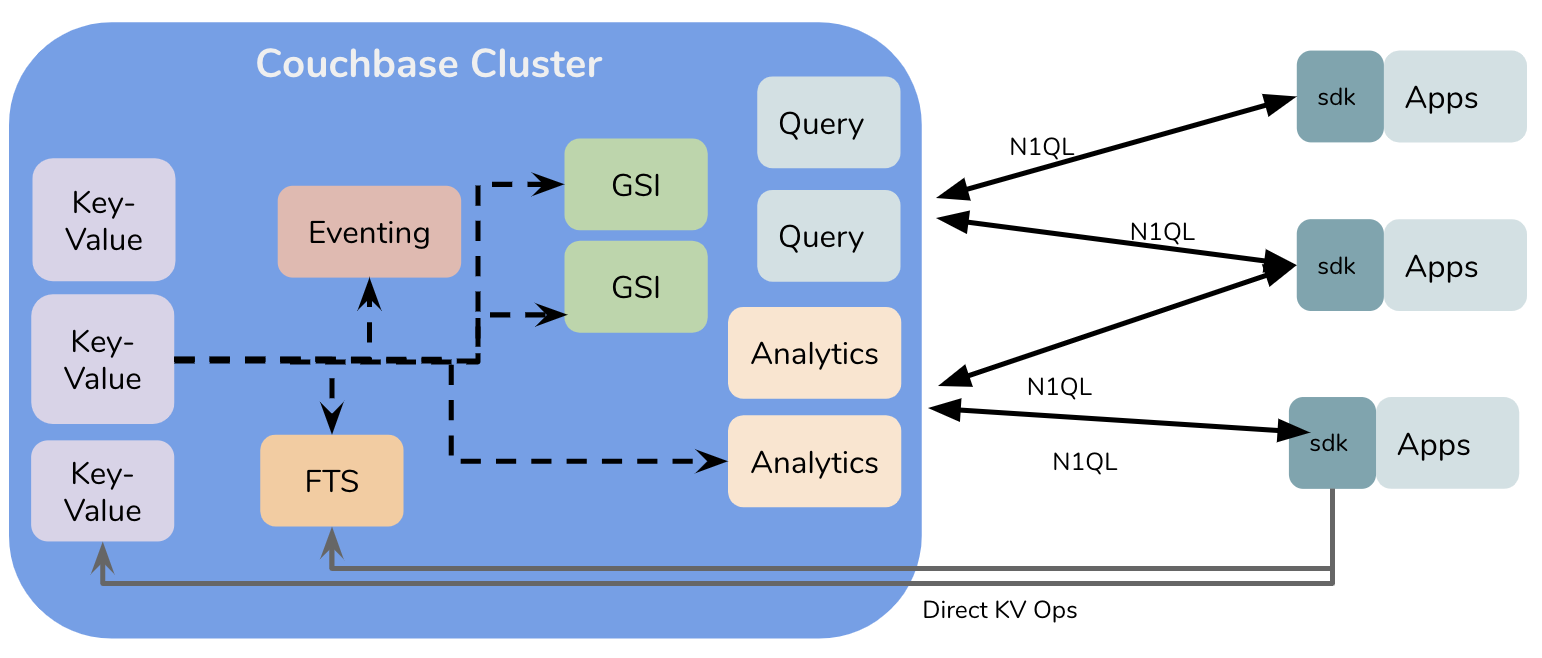
CouchbaseCouchbase, al igual que otros pioneros de los sistemas NoSQL, se creó para dar respuesta a los requisitos extremos de escala, rendimiento y disponibilidad del mundo web 2.0. De la simple clave-valor, Couchbase ha evolucionado para manejar consulta, busque en y análisis - a escala. Cada uno de ellos son motores creados específicamente e integrados a través de la plataforma de Couchbase multidimensional arquitectura. Tanto el servicio de consulta como el de análisis hablan N1QL. ¿Por qué construir dos motores distintos que hablan el mismo idioma? Porque...
Talla única: Una idea cuyo tiempo ha llegado y se ha ido. - Michael Stonebraker
El motor de consulta se creó para la carga de trabajo operativa y el motor de análisis para la carga de trabajo analítica. Hemos en comparación con los dos motores y dado el orientación. MongoDB ha seguido un camino similar, pasando de ser una base de datos en clúster que gestionaba cargas de trabajo sencillas a cargas de trabajo complejas para análisis y consultas en lagos de datos.
El año pasado, MongoDB anunció nodos analíticos en sus clústeres para el procesamiento analítico. En este blog, comparamos y contrastamos los dos motores para el caso de uso analítico.
Couchbase: Arquitectura de alto nivel
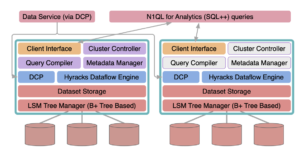
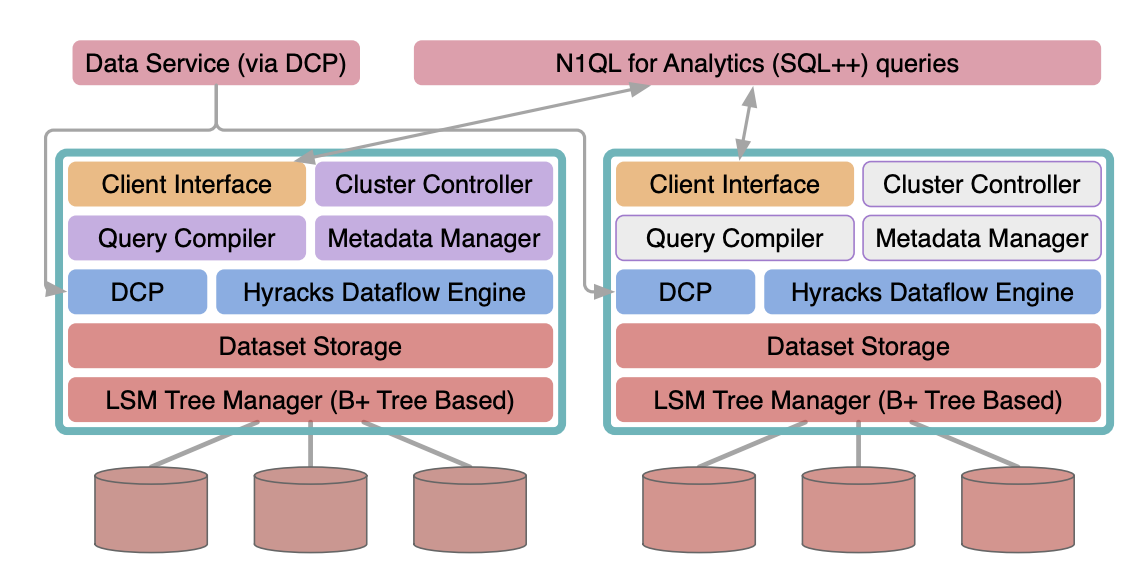
Dentro de Couchbase Analytics: Arquitectura de alto nivel
Nodos de análisis MongoDB: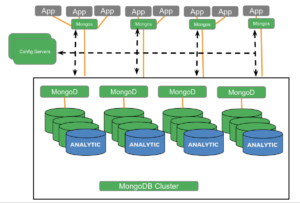
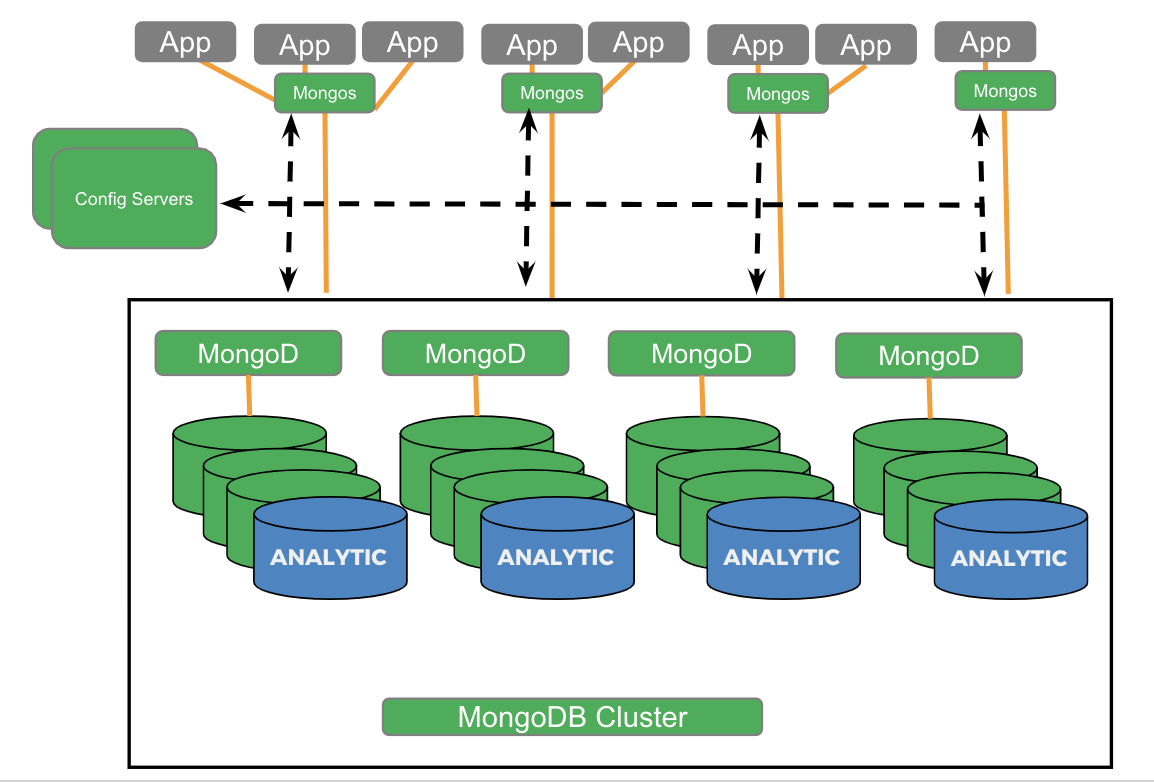
Vamos a comparar y contrastar el soporte analítico en los nodos MongoDB Analytic y Couchbase Analytics.
| Nodos analíticos MongoDB | Análisis de Couchbase | |
| Docs | https://docs.atlas.mongodb.com/reference/replica-set-tags/ | https://docs.couchbase.com/server/6.5/analytics/introduction.html |
| Arquitectura | Utilizar un conjunto de nodos réplica secundarios con una copia completa de los datos operativos. El lenguaje de consulta es el mismo (MQL); el procesamiento de las consultas es el mismo que el de la carga de trabajo operativa. | Distintos nodos de análisis que disponen de un subconjunto de datos operativos definido por el usuario. El lenguaje de consulta es el mismo (N1QL); el procesamiento de consultas está diseñado para conjuntos de datos más grandes (véase más adelante). |
| Detalles de la arquitectura | Nodos analíticos mapeados de Atlas | Couchbase Analytics: NoETL para el análisis escalable de datos NoSQL |
| Modelo de datos | BSON | JSON |
| Lenguaje de consulta | MQL - Lenguaje de consulta de MongoDB | N1QL - Lenguaje de consulta de forma normal no 1; SQL para JSON |
| Página de consulta | Consulta MongoDB | Consulta analítica |
| Tratamiento de consultas | Igual que el procesamiento de consultas operativas, utilizando mongos y mongod para el procesamiento de consultas distribuidas. | Motor de análisis diseñado para el procesamiento paralelo masivo (MPP) de los datos. Cada N1QL |
| Optimizador de consultas | Optimizador basado en formas; Requiere gestión de planes. | Optimizador basado en reglas. No requiere gestión de planes. |
| Explique | Texto y gráficos. | Texto y gráficos. |
| Indexación | Hay que crear el índice en el operativo y hacer que se copie. | Sólo análisis Indexación |
| Procesamiento paralelo | Cada nodo Mongod ejecuta las operaciones básicas y los mongos las combinan (por ejemplo, el grupo final y la agregación). | Gestionar consultas analíticas complejas de forma eficaz y ofrecer
las propiedades de escalado y aceleración deseadas, el Servicio de Análisis emplea los mismos tipos de MPP de última generación y no comparte nada (procesamiento paralelo masivo) basadas en estrategias de procesamiento de consultas [Del documento de VLDB] |
| Indexación | Indexación local | Indexación local |
| Uniones - Lengua | 1TP4Búsqueda admite uniones de igualdad simple entre dos colecciones; sólo se permiten campos escalares simples. Las matrices deben desenrollarse antes de unirse.
|
Operaciones INNER JOIN, LEFT OUTER JOIN, NEST y UNNEST.
|
| Tratamiento de consultas: tamaño de los datos | Las etapas intermedias de la canalización de aggregate() no pueden ser superiores a 100 MB en tamaño. Los escritores/usuarios de consultas deben utilizar un indicador especial para permitirlo. | Sin limitaciones; Cuando los datos intermedios (por ejemplo, tabla hash, datos de ordenación) se hacen más grandes, se vuelcan al disco. |
| Procesamiento de consultas: Tipo de unión | (aproximadamente) LEFT OUTER JOIN | INNER JOIN
LEFT OUTER JOIN |
| Buscar en | Admite la búsqueda dentro de la consulta. Utiliza la búsqueda Atlas en la nube y la búsqueda básica basada en el árbol B en las instalaciones. | El servicio Analytics no tiene una búsqueda integrada. Tenemos que utilizar el servicio de consulta con FTS para combinar la búsqueda dentro de una consulta. |
| Consultas admitidas | find() y aggregate() | Sentencia SELECT (de SQL y SQL++) |
| Tipos de JOIN (Idioma) | $lookup - esto es aproximadamente LEFT OUTER JOIN a través de | INNER JOIN
LEFT OUTER JOIN |
| Tipos de JOIN (Aplicación) |
|
|
| Agregación | Admite la agrupación y agregación común mediante el método aggregate(). | Admite la agrupación y agregación común mediante GROUP BY y las respectivas agregaciones. Consulte a continuación los agregados con ventanas. |
| Funciones agregadas en ventana: Probablemente, la función SQL más interesante. | No disponible. | Completamente compatible.
RANGO() PERCENT_RANK() DENSERANK() ROW_NUMBER() CUME_DIST() PRIMER_VALOR() ÚLTIMO_VALOR() NTH_VALUE() LEAD() NTILE() RATIO_TO_REPORT() |
| Análisis de datos de clústeres múltiples | Todos los datos analizados proceden de un único clúster MongoDB. | 6.5: Todos los datos analizados proceden de un único clúster Couchbase.
6.6: Puede ingerir y analizar los datos de múltiples clusters Couchbase. |
| Datos externos | Admite el procesamiento de consultas sobre datos S3. Admite los formatos BSON, CSV, TSV, Avro y Parquet. | 6.6: Soporta datos externos JSON, CSV y TSV en S3 |
| Fuentes de datos externas | Admite fuentes de datos adicionales a través del controlador JDBC. Integrado con la tubería de agregación a través de, tienes que esperar para ello, Operador $sql. | Ninguna, excepto las mencionadas anteriormente. |
| Subconsultas | Subconsultas a través del canal de agregación. | Subconsultas SQL estándar. |
| Plan de consulta | 1TP4Explicar | EXPLICAR |
| DataViz | Gráficos MongoDB integrados | Sin DataViz integrado |
| Inteligencia empresarial | Knowi
Tableau y otros motores de BI compatibles con ODBC y JDBC. |
Knowi
Tableau y otros motores de BI compatibles con ODBC y JDBC. |
Referencias:
- Comparación de dos enfoques basados en SQL para consultar JSON: SQL++ y SQL:2016
- De SQL a NoSQL - 7 métricas para comparar lenguajes de consulta
- Couchbase Analytics: NoETL para el análisis escalable de datos NoSQL