O ajuste do desempenho da consulta de pesquisa é um aspecto muito importante do Pesquisa de texto completo pois ajuda os aplicativos essenciais aos negócios a atender aos requisitos de SLA de latência e taxa de transferência. Sem muitos preâmbulos, gostaria de compartilhar algumas recomendações úteis para solucionar problemas de desempenho de pesquisa. Todas essas sugestões são independentes de qualquer configuração de hardware, topologias de cluster e são aplicáveis à maioria dos casos de uso de pesquisa genéricos.
Pesquise o menor número possível de campos
Isso é particularmente aplicável a certos tipos de consultas compostas em que o usuário tenta pesquisar um texto de consulta de pesquisa comum em vários campos indexados.
Vamos nos aprofundar em um exemplo de consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
"query": { "conjuncts": [ { "field": "UserName", "match": "searchText", "fuzziness": 1 }, { "field": "Department.Name", "match": "searchText", "fuzziness": 1 }, { "field": "SecondName", "match": "searchText", "fuzziness": 1 }, { "field": "ConsumerName", "match": "searchText" "fuzziness": 1 } ]} |
Se observarmos, há 4 cláusulas de consulta de correspondência na consulta composta conjunta, todas com o mesmo texto de pesquisa. Isso é altamente ineficiente, já que, em segundo plano, o sistema de pesquisa precisa pesquisar muitos dados indexados em campos diferentes para o mesmo texto de pesquisa. Essa sobrecarga é agravada pelo grande número de estruturas de consulta em tempo de execução criadas e pelo lixo coletado entre os campos.
O FTS tem um recurso para dar suporte a isso de uma maneira muito eficiente. Ele permite que os usuários indexem vários campos de documentos de origem em relação a um campo configurável genérico. Quando o usuário faz isso durante o tempo de definição do índice, ele pode executar pesquisas nesse único campo comum.
Para aproveitar esse recurso, o usuário precisa habilitar o Tudo em relação a todos os campos múltiplos no mapeamento de campo durante a indexação.
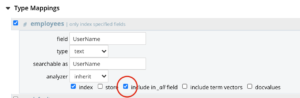
Com isso, todo o conteúdo desses campos também será indexado em relação ao padrão Tudo no índice. Isso tem um aspecto de armazenamento adicional para o tamanho do índice.
Agora o usuário deve ser capaz de emitir consultas sem especificar explicitamente o campo de destino. E sempre que os campos de destino não forem especificados na consulta, a Full-Text Search fará a pesquisa no campo comum padrão Tudo.
Portanto, com a otimização acima, a consulta anterior se tornaria mais simples, como abaixo,
|
1 2 3 4 5 6 7 8 |
"query": { "conjuncts": [ { "match": "searchText" “fuzziness” : 1, } ] } |
O desempenho dessa consulta de pesquisa deve ser muito mais leve e rápido em comparação com a consulta original.
Observação: Isso é aplicável se não houver aumento da pontuação usado na consulta original para as cláusulas filho.
Especificar prefix_length Para consultas de correspondência difusa
Os usuários escolhem o fuzzy consultas de correspondência para ajudar a evitar possíveis erros de ortografia nos textos de pesquisa. Com o fator de imprecisão, eles ainda receberiam do sistema de pesquisa os resultados pretendidos para o documento. Mas os usuários difusos precisam ter em mente que as consultas difusas são consultas que consomem muitos recursos.
Como - Em um índice FTS suficientemente grande, haverá muitos tokens candidatos que estão a uma determinada distância de fuzziness/edição do texto da consulta. Portanto, essencialmente, uma única consulta fuzzy se tornará uma consulta disjunta/OR para todos os tokens candidatos presentes no índice. Isso resulta em uma grande dispersão interna das operações de pesquisa rudimentares, o que é um recurso incômodo.
Vamos dar uma olhada em um exemplo mais simples para o fan-out da consulta aqui.
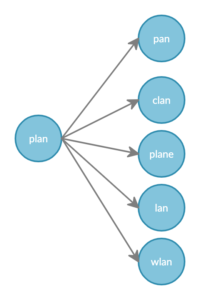
Uma consulta fuzzy de correspondência com uma fuzziness de 1 para o texto de consulta "plan" resultaria em um total de 6 termos sendo pesquisados, como neste exemplo. (considerando que apenas os 5 termos estão presentes no conteúdo indexado que estão na distância de edição solicitada ou na imprecisão de 1)
Uma ideia importante de otimização ao se proteger contra possíveis erros de ortografia é que a maioria dos erros de ortografia ocorre no final, e não no início do texto. Os usuários podem aproveitar esse fato e utilizar a função prefix_length em consultas difusas. Uma vez que o prefix_length é fornecido, então a imprecisão só será considerada para o texto após o prefix_length.
Normalmente, um prefix_length de 2 ou 3 deve ser bom. Mas, certamente, esse é um aplicativo ou caso de uso específico.
Exemplo:
|
1 2 3 4 5 6 7 |
{ "match": "beautiful", => "autiful" is only considered for fuzziness "field": "reviews.content", "analyzer": "standard", "fuzziness": 1, "prefix_length": 2 } |
Isso reduz drasticamente o escopo/número de tokens pesquisados no índice para uma determinada consulta difusa. E o desempenho da consulta de pesquisa pode ser significativamente aprimorado especificando-se um comprimento do prefixo por causa da imprecisão.
Ignore a pontuação quando a relevância do texto não for importante
Muitas vezes, observa-se que os usuários estão usando a Pesquisa de texto completo para as consultas de correspondência exata com um pouco de imprecisão ou outros recursos específicos de pesquisa, como geo. A pontuação de relevância do texto não importa quando o usuário está procurando por pesquisas exatas ou mais direcionadas com muitos predicados.
Em situações semelhantes, em que o usuário não está interessado no padrão tf-idf os usuários podem otimizar o desempenho da consulta ignorando completamente a pontuação. Os usuários podem ignorar a pontuação passando uma opção "score": "none" na solicitação de pesquisa.
Exemplo:
|
1 2 3 4 5 6 |
{ "query": {}, "score": "none", "size": 10, "from": 0 } |
Isso melhora significativamente o desempenho da consulta de pesquisa em muitos casos, especialmente para consultas compostas com muitas cláusulas de pesquisa secundárias.
Esse recurso está disponível desde a versão do servidor Couchbase - 6.6.1
Paginação de conjunto de teclas para pesquisas mais profundas na página
Como você deve saber, a paginação dos resultados de pesquisa pode ser feita usando o de e tamanho na solicitação de pesquisa. No entanto, à medida que a pesquisa entra em páginas mais profundas, ela se torna altamente exigente em termos de recursos. O principal motivo é que os resultados da pesquisa são, por padrão, classificados por seus tf-idf e o Full-Text Search tem requisitos de memória heap proporcionais ao deslocamento e ao tamanho da página solicitada. de+tamanho por manter essa classificação.
Para nos protegermos de qualquer requisito arbitrário de memória mais alta, temos um limite configurável janela bleveMaxResultWindow (padrão 10000) nos deslocamentos de página máximos permitidos. Mas aumentar esse limite para níveis mais altos não é uma solução escalonável.
Para contornar esse problema, introduzimos o conceito de paginação de conjunto de chaves no FTS.
Em vez de fornecer de como um número de resultados de pesquisa a serem ignorados, o usuário fornecerá o valor de classificação de um resultado de pesquisa visto anteriormente (geralmente, o último resultado mostrado na página atual). A ideia é que, para mostrar a próxima página dos resultados, queremos apenas os N primeiros resultados dessa classificação após o último resultado da página anterior.
Essa solução requer o cumprimento de algumas condições prévias:
- A solicitação de pesquisa deve especificar uma ordem de classificação.
- A ordem de classificação deve impor uma ordem total aos resultados. Sem isso, qualquer resultado que compartilhe o mesmo valor de classificação pode ser deixado de fora ao lidar com os limites de navegação da página. Uma solução comum para isso é sempre incluir o ID do documento como critério de classificação final. Por exemplo, se você quiser classificar por ["name", "-age"], em vez de classificar por ["name", "-age", "_id"].
Exemplo:
O usuário procura por descrição:light e classifica por ["name", "_id"]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "query": { "query": "description:light" }, "sort": [ "name", "_id" ], "search_after": [ "Anchor Summer Beer", "anchor_brewing-anchor_summer_beer" ] } |
Há um parâmetro semelhante chamado search_before para navegar até a página anterior de resultados. Em vez de fornecer o valor de classificação do último resultado, o aplicativo fornece o valor de classificação do primeiro resultado da página atual. Em todos os outros aspectos, o comportamento é o mesmo.
Com as paginações search_after/search_before, o requisito de memória heap das pesquisas de páginas mais profundas é proporcional apenas ao tamanho da página solicitada. Portanto, isso reduz significativamente o requisito de memória heap das pesquisas de páginas mais profundas em relação aos valores de offset+from.
Esse recurso está disponível desde a versão do servidor Couchbase - 6.6.1
Evite cláusulas de pesquisa duplicadas em consultas compostas
Sabemos que essa parece ser uma sugestão ingênua. Mas, algumas vezes, observamos que os aplicativos do cliente, ao converterem as consultas de pesquisa do usuário final em uma solicitação de pesquisa de back-end do FTS, acabam tendo muitas cláusulas de pesquisa secundárias duplicadas em suas consultas compostas.
Exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
"disjuncts": [ { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" }, { "field": "merchantID", "match": "9447611071-0" } ] |
Isso resultaria em muito trabalho redundante no backend do servidor Full-Text Search devido à duplicação do conteúdo da consulta.
Os usuários precisam estar cientes de que o serviço Search não realizará nenhuma deduplicação das consultas fornecidas. Ele respeita e executa a solicitação de consulta completa no backend. Portanto, os usuários precisam exercer a devida diligência para garantir que as consultas ideais sejam formadas antes de chegar ao serviço de pesquisa.
Fique atento a este espaço para obter mais dicas de ajuste de desempenho de consultas de pesquisa e gerenciamento de índices para o serviço Full-Text Search.
Outra leitura interessante sobre análise de texto para iniciantes em FTS aqui
Análise de texto em um mecanismo de pesquisa de texto completo