N1QL에서 '무언가'를 수행하는 방법은 무엇인가요?
우선 N1QL에 익숙하지 않다면 몇 분만 투자하여 무료 N1QL 교육을 수강하는 것을 적극 권장합니다. 여기또는 그냥 가지고 놀기 여기.
둘째, 광범위한 질문이므로 몇 가지 일반적인 시나리오를 살펴보겠습니다:
문서의 ID와 모든 속성을 선택합니다:
|
1 |
Select meta(t).id as id, t.* from `myBucket` t where type = 'someType' |
JOIN을 작성하는 방법:
여행 샘플을 사용하여 샌프란시스코 공항(SFO)에서 전 세계 어디로 가는 항공편을 운항하는 회사를 조회해 보겠습니다:
|
1 2 3 4 5 6 7 |
SELECT airline.name, airline.callsign, route.destinationairport, route.stops, route.airline FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND airline.type = "airline" AND route.sourceairport = "SFO" AND route.stops = 0 ORDER BY airline.name |
그리고 JOIN 절은 표준 SQL 조인처럼 보이지만, 여기서 유일한 차이점은 온키즈 키워드에 대해 자세히 알아보려면 N1QL 조인을 시각적으로 설명하는 이 문서를 확인하세요.. 카우치베이스 5.5는 다음에 대한 지원도 추가됩니다. ANSI 조인
배열의 항목을 선택하는 방법
다음과 같은 문서가 주어집니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ type: “person”, name: “John”, children: [ { “name”: “Pedro”, “age”: 8 }, { “name”: “George”, “age”: 11 } ] } |
10세 이상의 모든 어린이를 선택하려면 다음을 사용할 수 있습니다. UNNEST 키워드를 입력합니다:
|
1 |
SELECT c.* FROM tutorial t UNNEST t.children c WHERE c.age > 10 |
쿼리가 느린 이유는 무엇인가요?
아마도 쿼리가 인덱스에 닿지 않는 것 같습니다. 쿼리를 실행하여 확인할 수 있습니다. 설명 키워드로 설정할 수 있습니다:
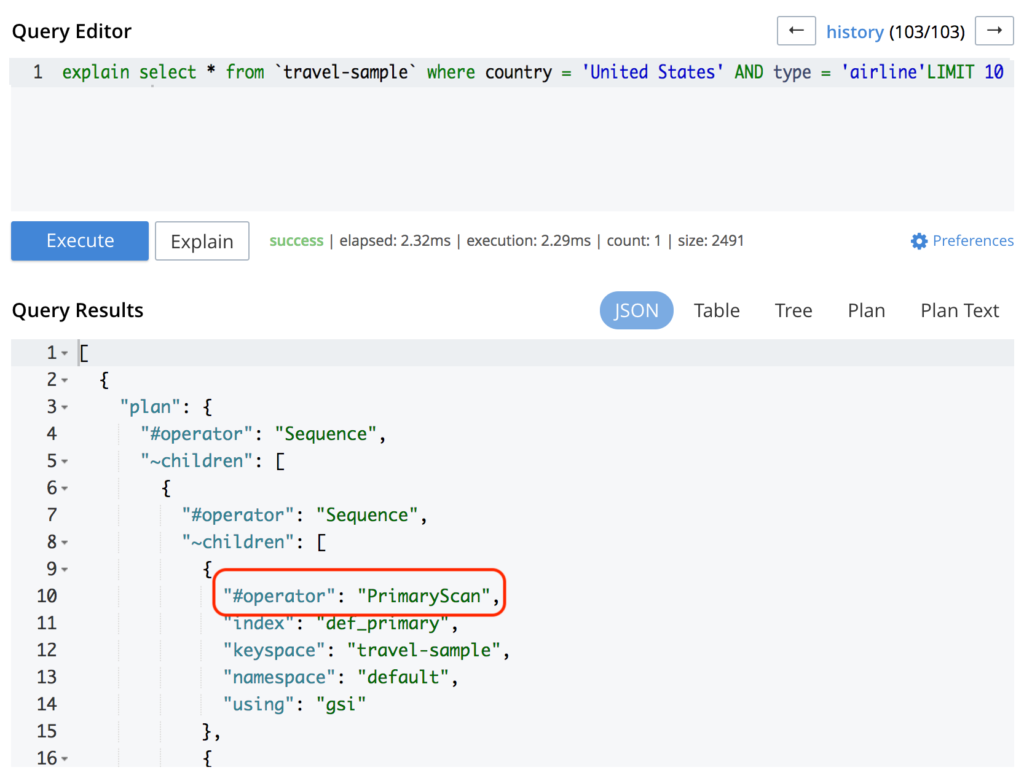
위 이미지에서 볼 수 있듯이 쿼리는 다음과 같이 기본 스캔 즉, 기본 인덱스를 사용하고 있다는 뜻입니다. 보조 인덱스를 생성하면 문제가 해결될 수 있습니다:
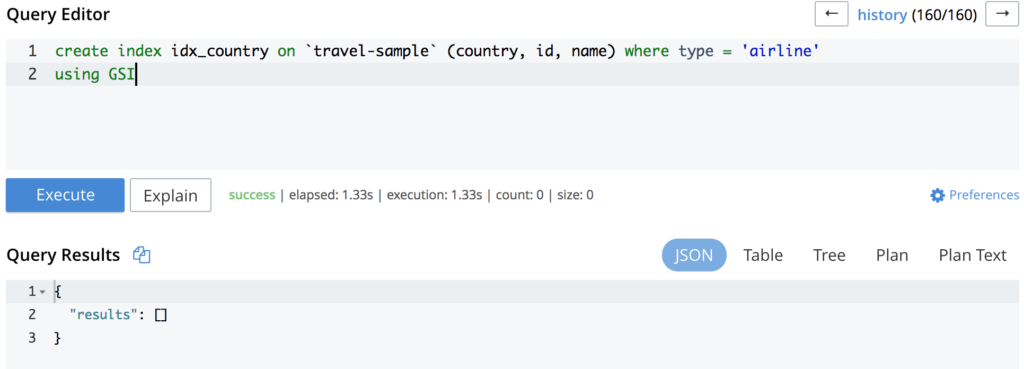
동일한 쿼리를 다시 실행하면 다음과 같은 내용이 출력됩니다:
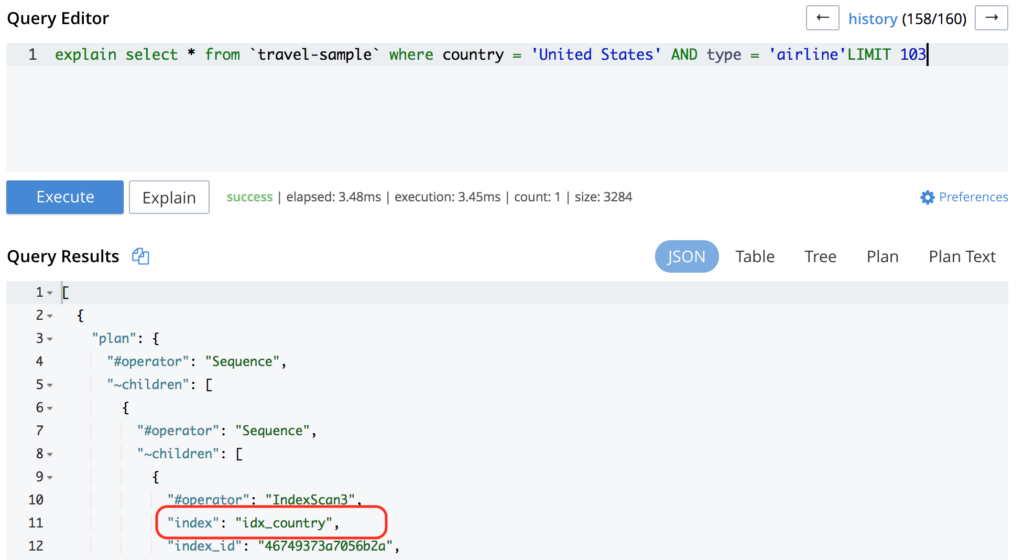
쿼리가 이미 인덱스에 도달했지만 여전히 성능이 좋지 않은 경우 보다 최적화된 인덱스를 추가할 수 있습니다(이 예제에서와 같이). 익숙하지 않은 경우 인덱스를 만드는 방법, 이 블로그 게시물을 확인하세요.
N1QL에서 결과를 페이지 매김하는 방법은 무엇인가요?
다음을 사용할 수 있습니다. LIMIT 그리고 오프셋:
|
1 |
select * from `travel-sample` where country = 'United States' OFFSET 10 LIMIT 10 |
확인 이 튜토리얼 를 클릭해 자세히 알아보세요. 또한 Spring 데이터를 사용하는 경우 다음과 같이 페이지 가능 객체를 메서드 정의의 끝에 추가하세요:

그런 다음 서비스에서 다음을 사용할 수 있습니다. 페이지 요청 객체입니다:
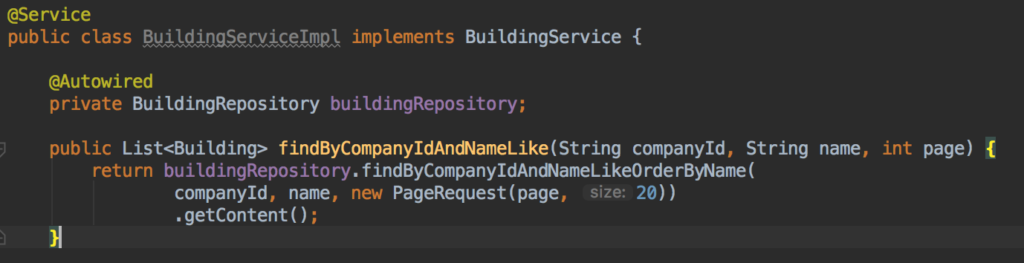
내 쿼리에 누락된 결과/잘못된 결과가 있습니다.
기본적으로 카우치베이스는 다음을 지원합니다. 읽기 후 쓰기 키로 문서를 가져올 때마다 인덱스와 보기는 데이터 변경 프로토콜(DCP)을 통해 비동기적으로 업데이트됩니다. 따라서 쓰기 직후에 쿼리를 실행하는 경우 뷰/색인이 업데이트되기 전에 쿼리가 실행될 수 있습니다.
카우치베이스는 속도를 중시하며, 모든 인덱스와 뷰가 업데이트되어 클라이언트에 쓰기가 성공적으로 실행되었다는 응답을 다시 보낼 때까지 기다릴 시간이 없습니다.
그러나 쓰기와 쿼리 간에 강력한 일관성이 실제로 필요한 시나리오는 거의 없으며, 이러한 경우에는 사용 중인 인덱스/뷰가 업데이트될 때까지 실제로 기다리도록 SDK를 통해 지정할 수 있습니다:

스캔 일관성에 대해 자세히 알아보려면 다음을 참조하세요. 공식 문서.
제 개인적인 경험상 쓰기와 쿼리 간에 일관성이 필요한 유일한 시나리오는 통합 테스트 단계, 즉 실제로 데이터를 삽입하고 그 직후에 쿼리하는 단계입니다.
배열 인덱스 생성/사용 방법.
이는 흥미로운 주제입니다. 배열 인덱싱 를 사용하면 성능이 크게 향상될 수 있습니다. 다음과 같은 문서 구조가 있다고 가정해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
{ "address": "Capstone Road, ME7 3JE", "alias": null, "city": "Medway", "country": "United Kingdom", "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "directions": null, "email": null, "fax": null, … "id": 10025, "name": "Medway Youth Hostel", "pets_ok": true, "phone": "+44 870 770 5964", "price": null, "reviews": [ { "author": "Ozella Sipes", "content": "Some review here…”, "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } } ] } |
이제 호텔 리뷰를 조회해야 한다면 다음과 같은 작업을 수행할 수 있습니다:
|
1 |
SELECT c.* FROM `travel-sample` t UNNEST t.reviews c where t.type == "hotel" limit 100 |
따라서 가장 간단한 인덱스는 리뷰 배열 will 는 다음과 같이 보입니다:
|
1 |
CREATE INDEX idx ON `travel-sample` (reviews) WHERE type = "hotel"; |
그런 다음 쿼리를 실행하면 짜잔:
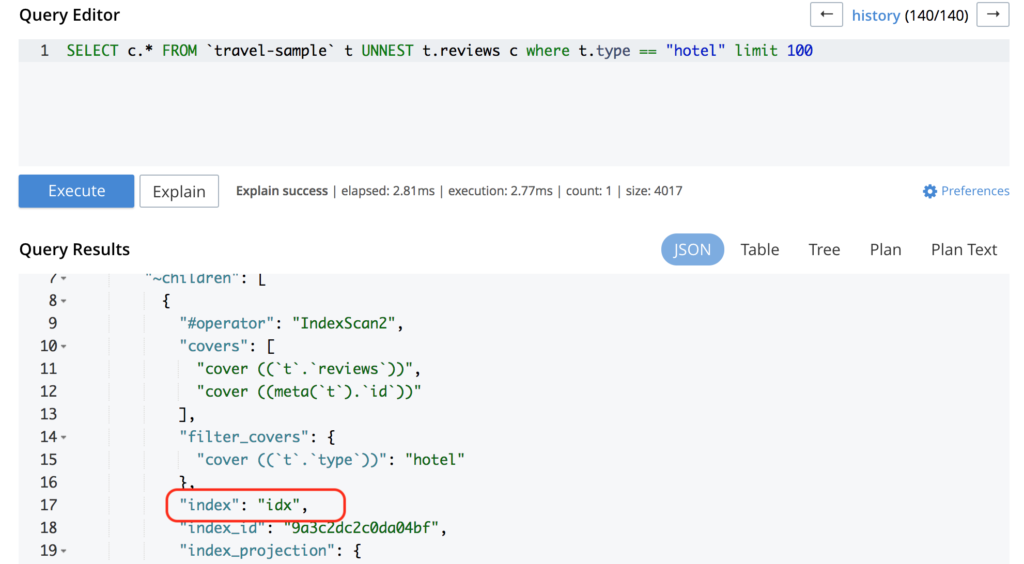
최근에 생성된 인덱스를 사용하고 있습니다.
더 많은 예제를 보려면 공식 문서 또는 읽기 이 훌륭한 기사 배열 인덱스를 최적화하는 방법에 대해 설명합니다.