Podría decirse que el método más popular de extracción, transformación y carga (ETL) es el uso de Kafka. Configurar Kafka para ETL, canalización de datos o transmisión de eventos puede resultar complicado, pero existen herramientas mejores.
Confluent ofrece la distribución más completa de Kafka, mejorándola con funciones comunitarias y comerciales adicionales diseñadas para mejorar la experiencia de streaming tanto de operadores como de desarrolladores en producción y a escala masiva. Couchbase, como plataforma de datos distribuida de alta disponibilidad y altamente escalable, y Confluent parecen una pareja perfecta. Pero, ¿cómo se mueven los datos dentro y fuera de Couchbase a través de Confluent?
Couchbase admite un conector de origen/sumidero Kafka/Confluent que puede gestionarse desde el panel de control de Confluent.
Habilitar el conector Couchbase Sink
Añadir el conector Couchbase se puede realizar de varias formas desde una instalación local de Confluent así como desde la descarga de Confluent Hub. See el documentación para instalar y configurar los enlaces de conexión.
Una vez añadido el conector en el panel de control de Confluent, la función Conectar debería tener este aspecto:
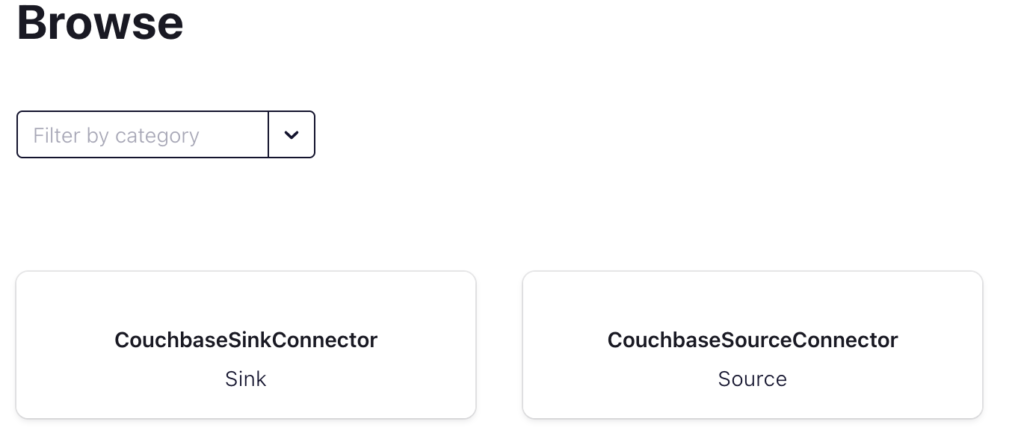
Confluent Connect con el conector Couchbase Sink y Source
Haciendo clic en CouchbaseSinkConnector muestra el siguiente cuadro de diálogo:
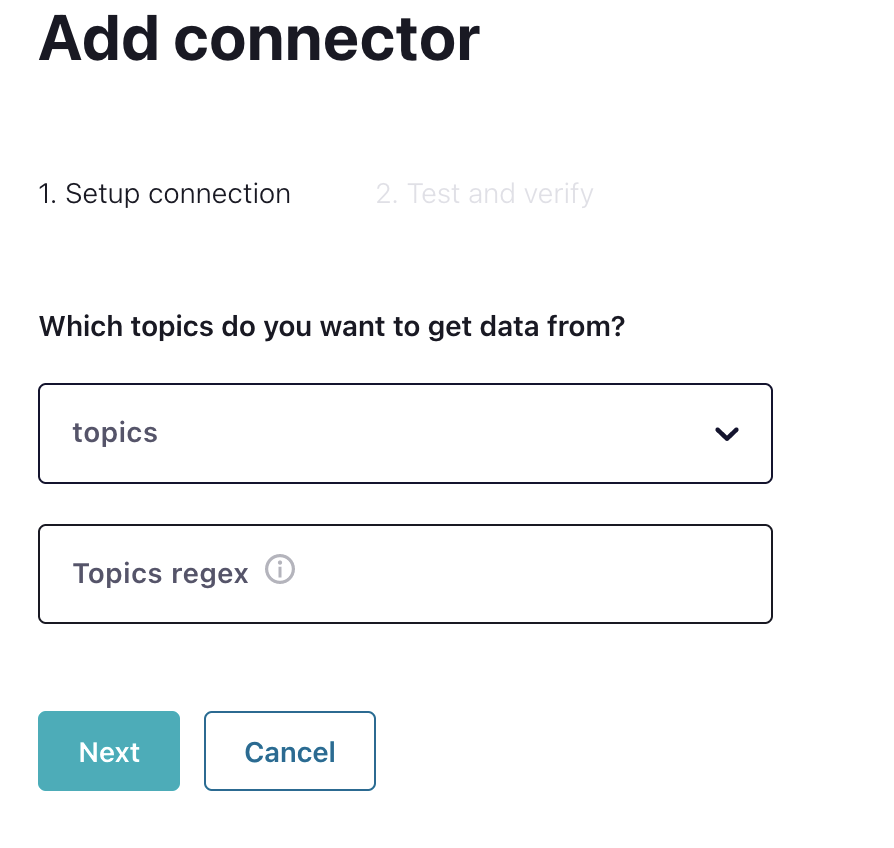
Al seleccionar el tema configurado en Confluent se rellenarán todos los campos para configurar el conector. Los campos son específicos de Couchbase para asignar temas a Couchbase. Fundamentalmente, Couchbase almacena datos en buckets, ámbitos y colecciones.
Establecer tema para el flujo
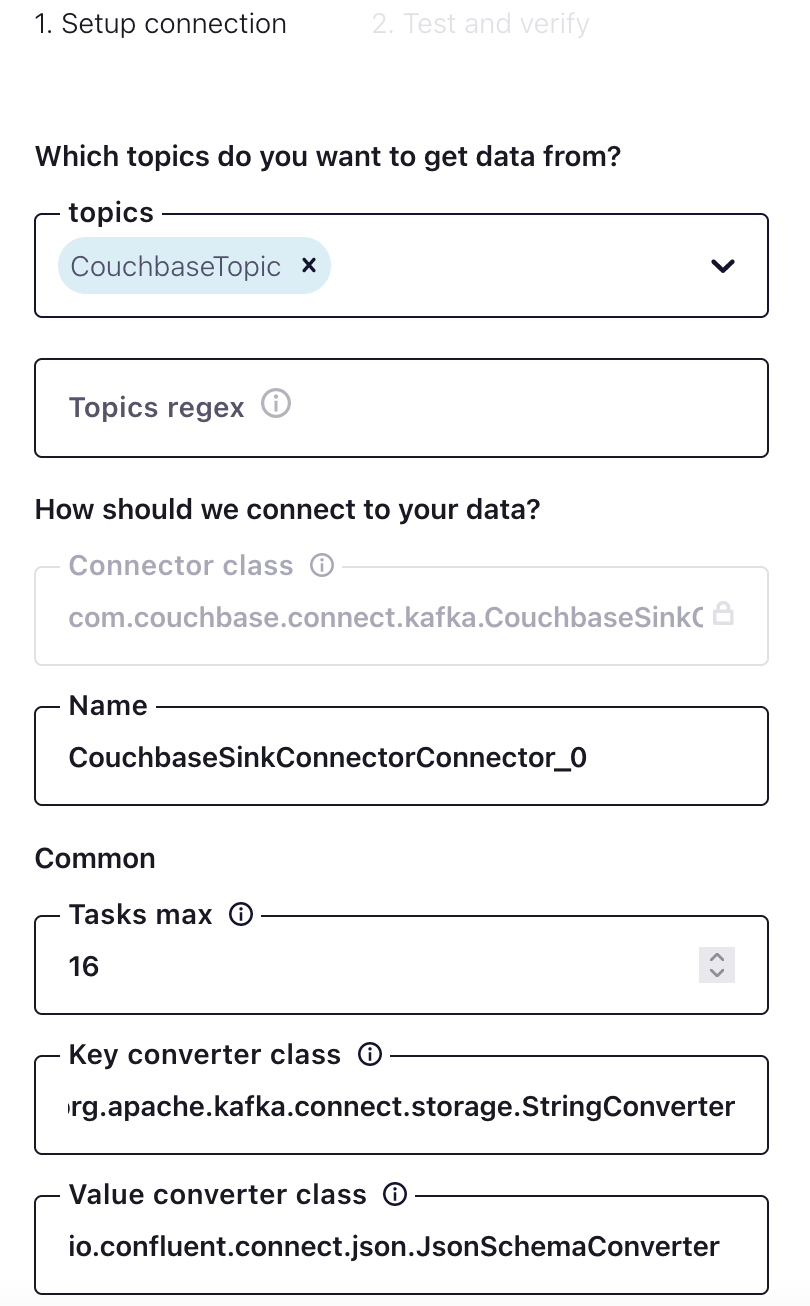
CouchbaseTopic se creó en Confluent con 16 particiones. Bajo el Común sección para Tareas máx.se puede pensar en ellas como hilos para el conector, por ejemplo, 16 tareas. En este caso, hay un mapeo uno a uno entre particiones y tareas para un alto rendimiento. Este valor no es un requisito, por ejemplo, podría haber 16 particiones y 32 tareas, pero hay que tener en cuenta los recursos de la máquina anfitriona.
Selección de un bucket Couchbase como sumidero
El siguiente paso es la conexión a Couchbase, que es sencilla.
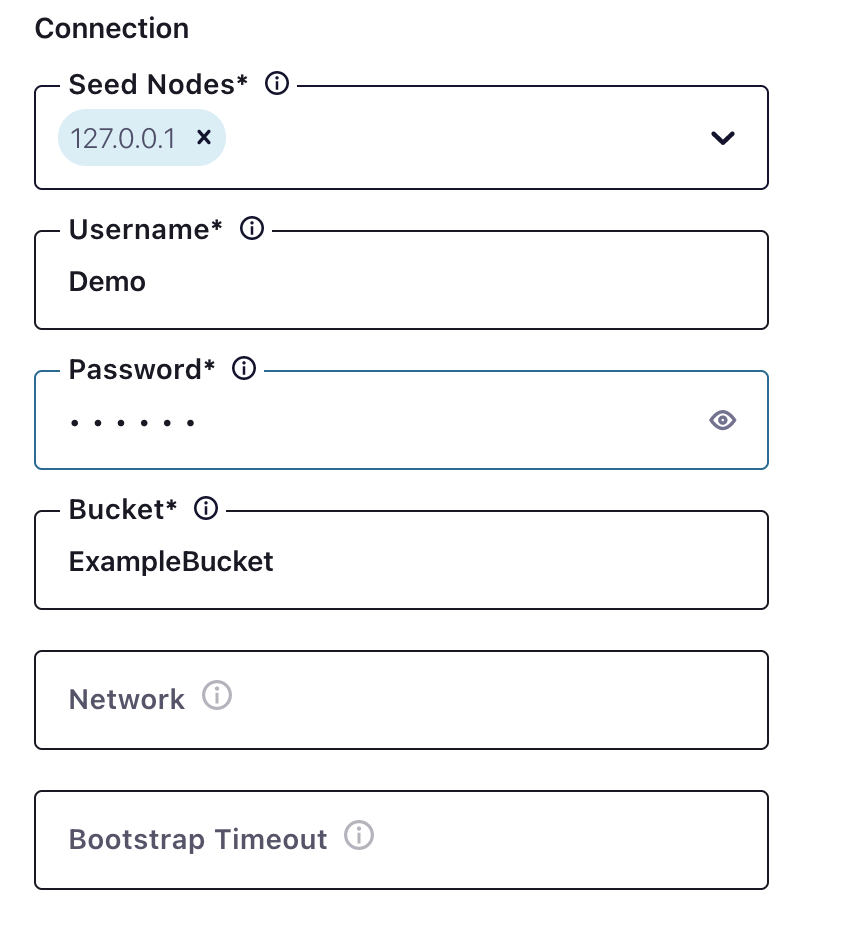
En este caso, el nodo semilla es localhost, pero puede ser un nombre de host o una IP.
Recuerda... el usuario del bucket debe tener derechos de acceso en Couchbase para el bucket, los ámbitos y las colecciones.
Después de configurar la conexión, veamos los ámbitos y las colecciones.
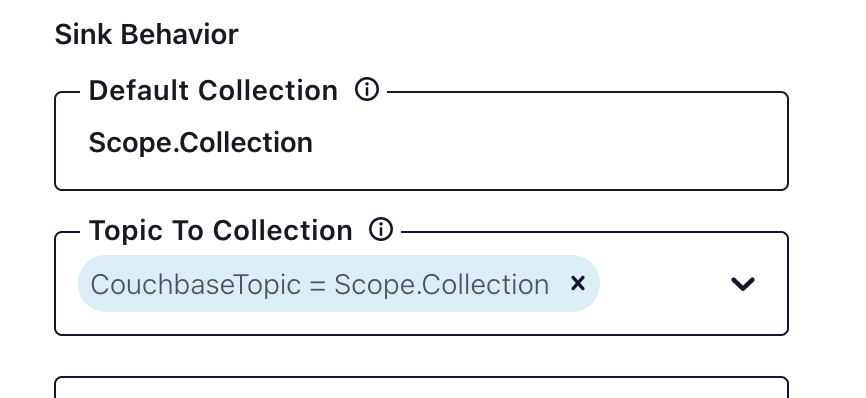
Arriba hay un ejemplo de cómo configurar ámbitos y colecciones. Es importante asegurarse de que el ámbito y la colección existen en Couchbase con los permisos adecuados.
Al crear los temas en Confluent, tenga en cuenta lo siguiente cubo->ámbito-->colección Asignación: cada tema se asignará a un ámbito/colección. Si se asigna más de un ámbito y colección, deben crearse temas específicos para la asignación.
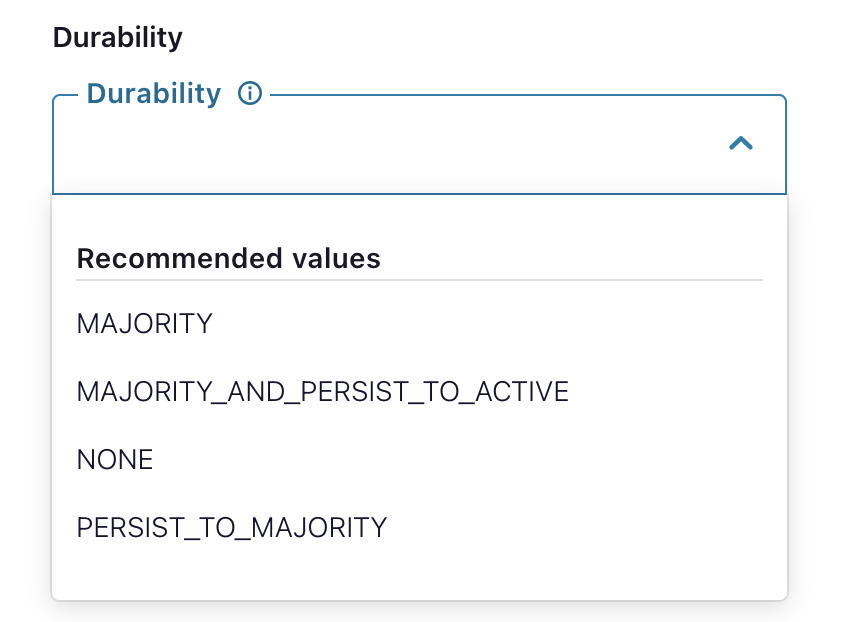
Ajustes específicos de durabilidad de Couchbase
Las escrituras duraderas pueden configurarse para el conector Couchbase como se indica a continuación:
Couchbase Connector puede ser configurado para diferentes tipos de serialización y deserialización de datos, como JSON o binario AVRO. Veamos la compresión binaria AVRO.
La compresión AVRO es una compresión binaria que puede deserializarse en JSON utilizando un esquema. Este esquema mapea el binario a una estructura JSON. El conector Couchbase puede deserializar con un esquema configurado en Confluent. Confluent realizará la serialización y deserialización, y luego el tema se rellenará con el resultado de la serialización. Confluent puede admitir un esquema de forma nativa a través de Control Center. Si hay varios pasos en la serialización, es necesario crear un registro de esquemas para almacenar los esquemas y los pasos ordenados en los que se van a utilizar los esquemas.
Por último, se configura el conector.
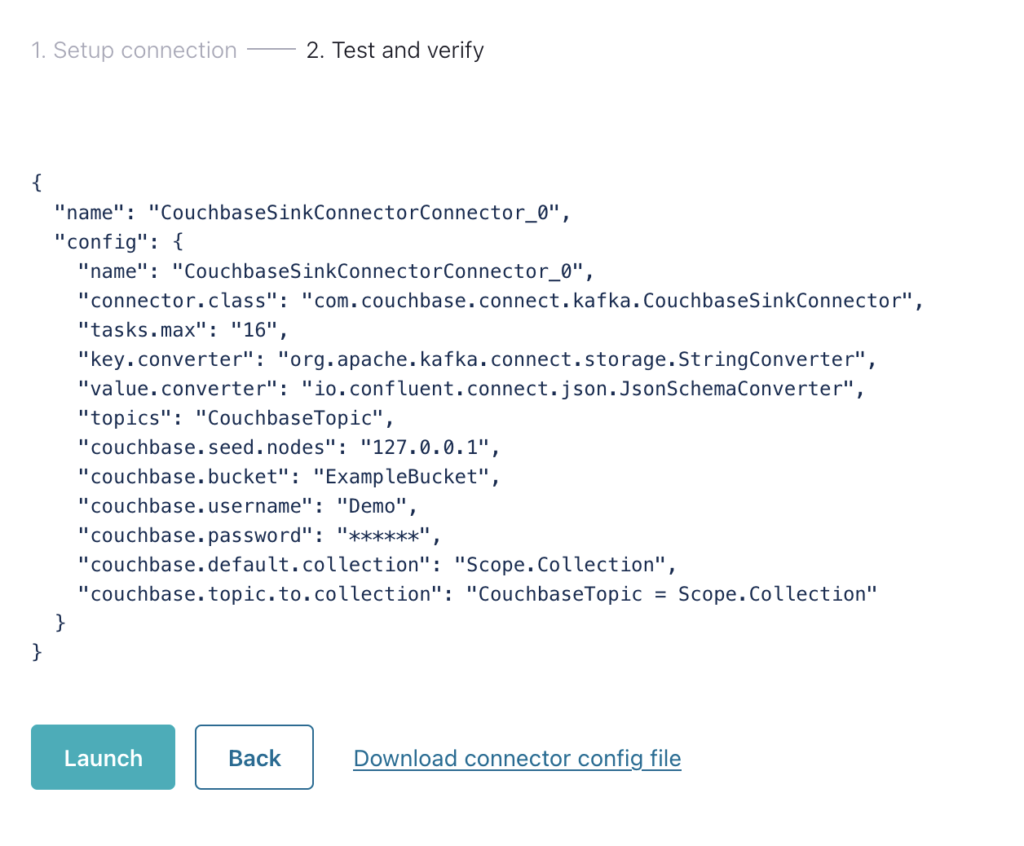
Si es necesario configurar varios conectores (por ejemplo, distintos temas para distintos ámbitos y colecciones), el archivo de configuración puede descargarse y añadirse al clúster predefinido.
Couchbase Kafka Connector con Confluent es un camino fácil para ETL y streaming de datos desde y hacia Couchbase. El conector de origen es más fácil de configurar, ya que se trata de la misma conexión configurada pero con una asignación de cubo -> ámbito -> colección a un tema Kafka.
Una vez que el conector esté en marcha, recogerá los mensajes de la cola de temas y los migrará automáticamente a Couchbase a medida que lleguen. Cada tarea tomará el último mensaje de la cola y lo eliminará de la cola, no hay necesidad de gestionar la cola más allá de cuánto tiempo se guardan los mensajes en la cola como se muestra a continuación:
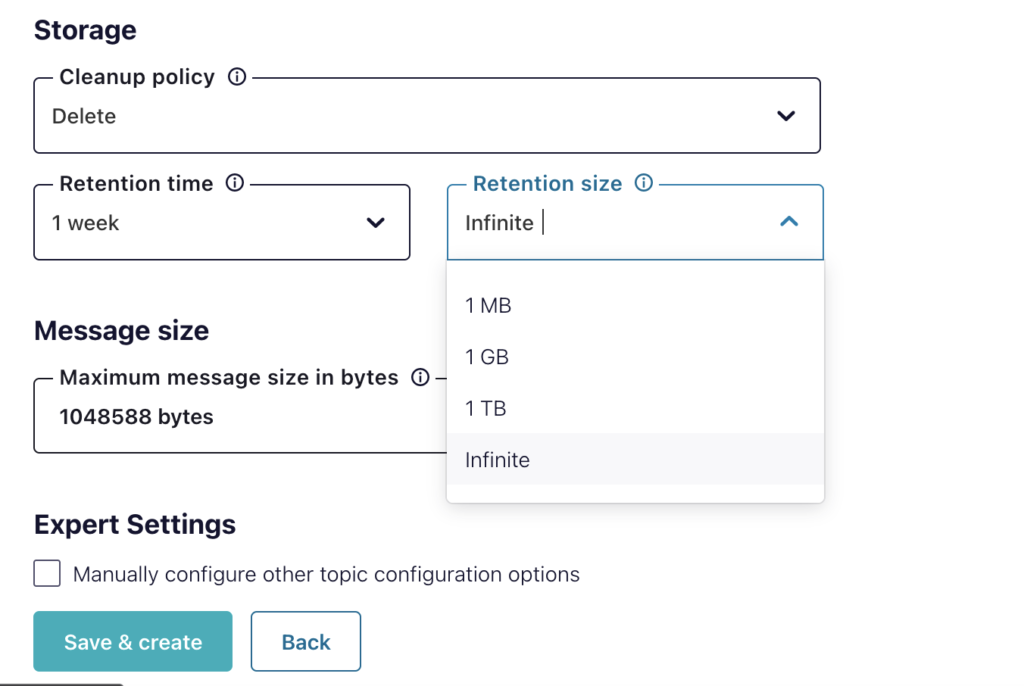
Próximos pasos y recursos
-
- Inicio rápido para Couchbase Kafka Connector
- Repositorio GIT de ejemplos de Kafka/Couchbasecon profundas inmersiones en la integración de SQL++, así como en las personalizaciones.
- Conector Confluent Couchbasechbase/kafka-connect-couchbase
- Integración de Couchbase Capella Data con Confluent Cloud (Vídeo a continuación)
