Data Validation is an interesting topic to cover for a NoSQL technology, purely down to the fact that the core principles of the system revolve around a “schema-less” architecture. For many years, SQL and schemas have controlled application data, ensuring the conformity of information inside the database. These restrictions prevented the modernization of most applications by slowing down development time.
Regardless, you still need to govern and validate the information underneath your applications. With that in mind, how do we achieve this with Couchbase?
The flexibility of a schema-less architecture makes it harder to enforce the structure of information coming from multiple sources, such as sensor and edge device interaction, where the number of communication points is vast. There are ways to achieve data validation within the database itself, using the Couchbase Eventing service. The service, on its own, is extremely powerful and flexible, giving the administrator control over the specifics of the validation on the documents and resulting actions to take.
The blog post will walk you an example of using the eventing service to validate the information living in your cluster. As you will see, there are many different ways to build this, but let’s just focus on one to begin with.
NoSQL Fundamentals
At the center of any database is the data – the actual information that we wish to store. Before adopting NoSQL, we would insert the data into our system, but it had to adhere to the structure developers or DBAs defined. DBAs would spend time normalizing the information up to the 6th normal form to reduce data redundancy. This whole structure was commonly known as a schema and was great for validating the integrity of information, ensuring the system of record quality, and becoming a source of truth.
Despite the benefits, the schema-based architecture presented some disadvantages, mainly introduced when applications started operating on a higher level and companies started innovating faster. The structured approach to storing data began to slow down development, and schema changes became a nuisance.
This is where the schema-lass approach started to take precedence—allowing users to store any information they wished to and allowing the acceleration of innovative development to flourish.
SQL but NoSQL
Despite the move to a more flexible and agile database, some attributes of the old model are desired with the new approach; Data Validation is one of those topics. Couchbase has made considerable changes in the recent releases to bridge the gap between SQL and NoSQL technologies.
Scopes and Collections were released in Couchbase Server 7.0 and opened the door to greater logical organization and multi-tenancy use cases. It allowed us to map data from schema to schema-less while still holding the flexible development practices at the core.
Providing ACID guarantees from a distributed system was another big step, ensuring all-or-nothing semantics across unrelated data for transactional workloads back in v6.5.1.
Data Validation is another topic that comes through alongside these. How do I evaluate the information in my database when there is no schema to enforce it? Like the previous features that complemented the schema approach, the ability to choose whether you have this or not is beneficial. Although, it isn’t necessary to incorporate this into the fundamentals of the application itself.
With the proliferation of the 5G network and Mobile/Edge devices, the chances are, the requirement of data governance and management may still be there. Utilizing tools in the Couchbase arsenal can provide you with an easy and fully controlled method of applying this validation without affecting the performance of either the application or database nodes.
Edge Computing with Multiple Application Sources
Before we dive into the fun ways of validating on the server, let’s discuss the other option available. Validation at the application level will probably be the first thought that comes to mind. If we want to ensure that information is suitable for storing, why don’t we check it before inserting the documents into the database? Applying application logic on the data before ingestion by the system would guarantee that no document would get anywhere near the database unless the system had already validated it.
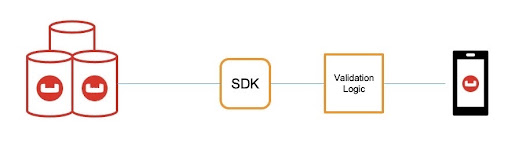
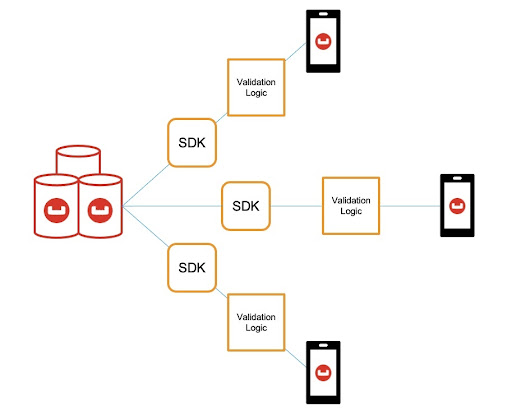
Theoretically, this sounds like a good idea…. for a single application talking to a single dataset. However, when you start to look at the mobile application space, where we could be talking to several edge devices, all talking to multiple datasets, in a single database, the maintainability will suffer. All teams writing to the database would need to maintain and share the validation logic consistently, and you start to lose the guarantees which were there for the single app scenario.
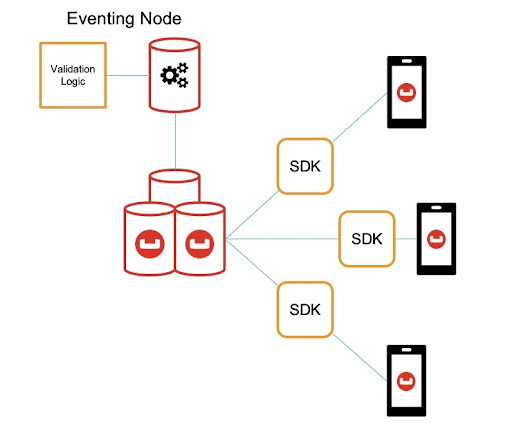
Eventing Service
Considering the application validation problems, we need a way to achieve the same result but at a different point; this is where the eventing service comes in. For those that don’t know about it, the eventing service allows you to act on data mutations in the database programmatically. These actions are defined within JavaScript event handlers and are triggered on any updates or deletes to the data.
| function OnUpdate(doc, meta) { log(‘docId’, meta.id); } function OnDelete(meta, options) { } |
Since the eventing service can run this logic after the data has come into the database, nothing stops us from incorporating the application logic into these functions. We will pass the responsibility over to the eventing service to check the information whenever it is inserted or modified.
This does two things:
- Removes the duplication of validation logic across multiple applications
- Centralizing configuration and maintainability of what is considered ‘valid’ data
Now we can use the eventing service to check document fields and values within a bucket, regardless of where the data came from. But there is still one consideration, what do we do with documents if we decide they are invalid? At the application level, an invalid document would not pass the checks and would throw an error or exception telling you, which you could then handle in whichever way was necessary.
Because the information is already in the bucket, we need to flag the document’s validity without tarnishing the integrity of the data. It’s up to you how you decide to handle this part, but in my example, we can keep a record of the invalid documents in a separate collection, and we can remove the record when it has been cleaned into a valid state.
Implementation
First, we need to build an eventing function on the target dataset. For this example, I have chosen the Users collection. We will also need to specify a location for the eventing metadata to be stored (see the eventing documentation here).
Finally, I will need to define an alias for the location of the invalid data, which I can reference; for this, we have the Users_Invalid collection.
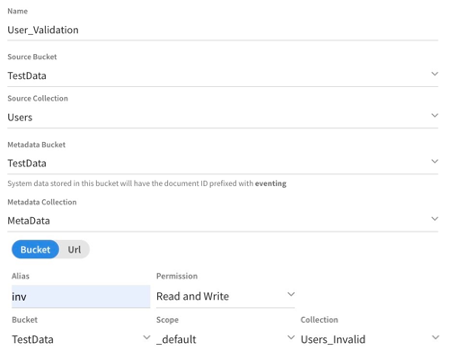
Once the structure has been created, we need to create something that represents a valid document. This way, we can check all the new documents against this one to guarantee the information is correct. In this instance, I will create a document that lists all of the required fields and types they should contain. If you wanted to, you could correlate this to the schema we discussed before, hence I will call this the Users_Schema.
| { “fields”: [ { “name”: “Name”, “type”: “string” }, { “name”: “Age”, “type”: “number” }, { “name”: “Subscriber”, “type”: “boolean” } ] } |
The next thing to create is the validation logic. Eventing will execute the logic every time there is a document mutation in the source collection, Users. It will check to see whether the document has a related schema document associated. If so, check all the field and value types and compare them to the document being referenced. If any of the fields don’t exist, or any of the types don’t match what is expected, then we create a record in the Invalid_Users collection.
There is a condition at the bottom of the script that attempts to delete the record if the logic returns a valid result. It is removed from the invalid records when the document has been cleaned or fixed into a valid state.
| function OnUpdate(doc, meta) { log(‘docId’, meta.id); var schema, valid, reason //Grab the schema document schema = inv[doc.type + ‘_schema’] reason = ” valid = true //Iterate through fields for(const field of schema.fields) { //Check if field exists if (field.name in doc) { //Check if field type is correct if (typeof doc[field.name] == field.type) { valid = true } else { reason = ‘Incorrect Type for Field: ‘ + field.name + ‘. Expected: ‘ + field.type + ‘. Actual: ‘ + typeof doc[field.name] valid = false break } } else { reason = ‘Field: ‘ + field.name + ‘ does not exist’ valid = false break } } if (valid == true){ delete inv[meta.id] } else { var docContent = { “id”: meta.id, “reason”: reason } inv[meta.id] = docContent } } |
All there is to do now is test it out, insert a User document with invalid fields/types and check that a record is created in the Invalid_Users collection’. Attempt to fix the invalid documents and check that the record is removed. Overall, this allows you to achieve asynchronous data validation after the point of save, in 3 easy steps.
Taking it further…
Now as you can probably tell, this is a very simple example, and I have no doubt that I could have written JavaScript more efficiently. However, I was still able to validate all the information within a bucket against what we could call a schema, while maintaining the integrity of the information and ensuring there was no data lost in the process.
This approach was the one that I wanted to follow, but could be modified and extended in several different ways…
- Validating actual values of the fields (e.g. Age must be in range 1-100 etc…)
- Removing the documents entirely from the collection
- Moving the entire document out of the collection
- Sending notifications via cURL to an external service (Email response perhaps?)
- Writing extra logic to autonomously fix the invalid data with enrichment
This blog post has demonstrated a couple of things:
- Asynchronous data validation after the point of save
- The power of the eventing service as a whole
Returning to the original points, bridging the gap between SQL and NoSQL technologies is becoming more and more common, not as architectural changes, but as tools to achieve what was once a fundamental implementation.
