Introduction
This blog is meant for users who are familiar with the basics of Couchbase Server and Views. Novice users should start here to gain basic understanding of Couchbase Server and then continue here to get acquainted with Views.
Views were added in Couchbase Server nearly nine years ago to support secondary key access on the stored json data. They have served us well, but now we have better alternatives, namely Global Secondary Indexing and N1QL querying, Full Text Search and Analytics. In this blog we will try to gain basic understanding of Views, the common use cases they support and their limitations. Later, in a second blog, we will take a look at the aforementioned better alternatives.
What is a Couchbase view?
First, let’s learn what a Couchbase view is and how it works. A view is basically a materialized version of selected portions of a dataset. Its definition is stored in a design document that comprises a ‘Map’ function operating on the Key-Value data that is then fed to an (optional) subsequent “Reduce” phase that further summarizes the data. Both outputs are materialized on disk under the “views” directory on each Data node in the cluster.
How does a view work?
Couchbase views are eventually consistent with their source data. Each view is updated at frequent intervals, by default every 5 seconds or 5000 mutations, whichever comes first. They are similar to Oracle’s materialized views that are local to data partitions and are refreshed using a set of rules at some predefined intervals.
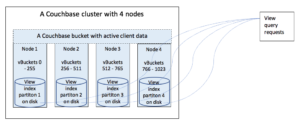
View replicas and compaction is very easy to configure. Replicas can be enabled easily on per bucket basis. Compaction can be configured equally easily alongside the compaction policy for buckets.
Views use map and reduce functions to pre-calculate and store their results, hence minimizing the need for just in time calculations. View functions are written in JavaScript. Hence, you can express fairly complex logic in a view definition without having to suffer long latencies at querying time. A map function is the most critical part of any view as it creates a logical mapping between the source dataset and its subset that is held by the view. Each map function is supplied a ‘doc’ and a ‘meta’ argument giving the function access to each stored item and its metadata.
Basic form of a map function looks like this:
|
1 2 3 4 5 6 |
function(doc, meta) { if (doc.attribute){ emit(doc.attribute); } } |
This function returns rows containing keys and doc.attribute’s values.
Couchbase provides a few built-in reduce functions namely _count (provides a simple count of the rows that are output by the map function), _sum (provides a sum of the values output by the map function as long as they are numeric; supports group level summation) and _stats (provides count, min, max, sum and sum square of the values output by the map function as long as they are numeric).
Writing of custom reduce functions is supported as well as overriding of the built-in reduce functions is supported.
Querying a view
View queries can be based on a single key, set of keys or key ranges with specified start and end. A view query can be targeted to any Data node which spreads it to the rest of the Data nodes in the cluster and gathers results from them, collates the results and responds to the query. This approach is called “scatter and gather”.
Views offer three levels of consistency at querying time through the use of a parameter named ‘stale’. Stale value ‘update_after’ is the default. It returns the view query results and then triggers an index update. It offers fast responses but the query results have the potential for being stale. Stale value ‘ok’ means that the query results are returned without triggering an index update. Obviously, it gives fast responses but they carry the potential for being stale. Stale value ‘false’ means that the view index is updated before executing the query, hence the response may be delayed.
Common use cases for views
Views easily support common use cases such as:
- generating lists of data on specific object types
- generating tables and lists of information based on your stored data
- extracting or filtering information from the database
- returning pre-calculated aggregations or reductions on collections of stored data
- multi-level group by aggregations
- querying geo spatial data
- pagination
Now let’s create and query a view to see how a map and built reduce functions work together to give us statistical aggregations of geographical altitude of all airports in the travel-sample dataset. This screenshot of Couchbase Administrator Console UI shows how a view can be created there.
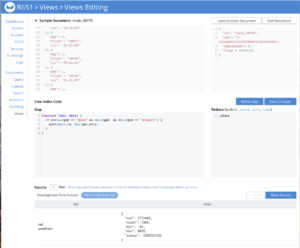
Impressive stuff!
No doubt, Views are easy to create and easy to use. However, they do have their drawbacks and limitations. Let’s take a look at how the above example can be easily served by using modern and better Couchbase features; Global Secondary Indexing and N1QL.
First load travel-sample bucket and create a secondary index with the following definition.
|
1 |
CREATE INDEX geo_altitude_idx ON `travel-sample`(geo.alt); |
Then, execute the following N1QL query.
|
1 |
SELECT SUM(geo.alt) as sum, COUNT (geo.alt) as count, MIN(geo.alt) as min, MAX(geo.alt) as mix, SUM(POWER(geo.alt,2)) as sumsqr FROM `travel-sample`; |
This query returns the following result set.
|
1 2 3 4 5 6 7 |
{ "count": 1968, "min": -54, "mix": 9078, "sum": 1712485, "sumsqr": 5303561573 } |
That’s how easy it is!
Limitations of Views
While Views offer great ease and flexibility in expressing the indexing and querying logic, they have their weaknesses and disadvantages such as:
- They are not easy to scale because they are tied with data partitions. Hence, they can’t benefit from Couchbase’s multi-dimensional scaling.
- It is not possible to achieve workload isolation with Views for the aforementioned reason.
- They can’t deliver throughput higher than a few thousand QPS due to dependence on disk persistence and the scatter gather overhead.
- Storing view indexes on disk along with data partitions increases the overall amount of data on each Data node’s disk. This results in longer rebalance times. Likewise, storing, updating and compacting of view indexes increases disk IO utilization.
- No memory quota is set aside for caching of view indexes. Hence, they can’t deliver the best performance.
- Views don’t offer strong error checking; hence it is easy to make mistakes in their definitions. For example, one can easily attempt to parse a json attribute that may exist only in a subset of documents. The map function for such a view logs parse errors for documents where that attribute doesn’t exist.
- View updates often take a long time because they are disk bound. Modifying an existing view definition or executing a full build on a dev view, causes the entire view to be recreated. The issue gets amplified when a single design document has multiple views.
- Ephemeral buckets offer low latency and consistent high throughput reads and writes, but no views can be created on them because these buckets have no disk persistence.
- Views are eventually consistent compared to the underlying stored documents.
Conclusion
Couchbase Views have had a good run, but now we have better alternatives that offer far better manageability, scalability, performance and throughput. Given the expressive power of N1QL queries, the ease of scaling offered by multidimensional scaling, much higher performance and throughout delivered by Global Secondary Indexing and Full Text Search, it is very likely that Views will get deprecated soon. Users are encouraged to learn the new alternatives and start planning a migration. More will be said about those alternatives in the next blog.