Databases play a crucial role in storing, organizing, and retrieving information. Two main types of databases are relational (SQL) and non-relational (NoSQL) databases. Both have unique features and benefits, so choosing the right type of database is essential for building efficient and scalable applications.
In this article, we’ll explore the differences between relational and non-relational databases, their features, and their benefits. We’ll also discuss common use cases for each type of database and help you decide which one is the best fit for your application.
What is a Relational Database?
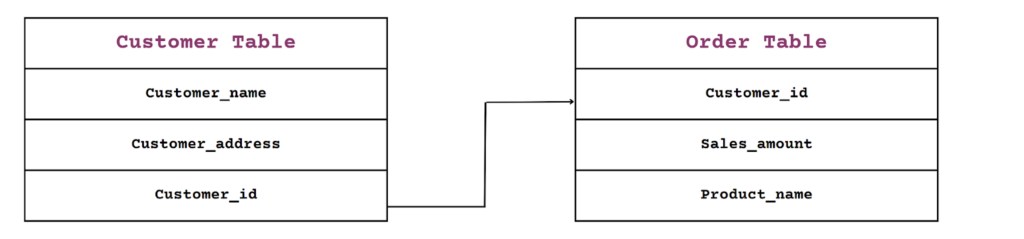
A relational database, also known as a SQL database, is a database that organizes data into tables, with each table containing unique records represented as rows and attributes or properties represented as columns. These tables are related to each other through primary and foreign keys. A primary key is a unique identifier for a record in a table, while a foreign key is a column in one table that refers to the primary key of another table, establishing a link between the two tables.
With the use of primary and foreign keys, tables can be linked together to create relationships between them. For example, a customer table and an order table can be linked through a customer ID primary key in the customer table and a customer ID foreign key in the order table. This allows for easy information retrieval across multiple tables, making relational databases ideal for managing complex data.
Relational databases are used in a wide range of applications, from small-scale systems to large enterprise-level applications. They are popular because they can handle various data types and can be easily modified to fit changing needs.
What is a Non-Relational Database?
Non-relational databases, or NoSQL databases, are becoming increasingly popular due to their ability to handle unstructured or semi-structured data. This type of data can be difficult to store and analyze in a traditional relational database, which relies on a fixed schema to organize and manage data.
Unstructured data refers to data that does not conform to a specific data model or schema. This type of data is often generated by humans, such as social media posts, and can be difficult to analyze using traditional SQL queries. Semi-structured data, on the other hand, has some structure but does not conform to a rigid schema. Examples of semi-structured data include sensor data and machine logs.
Non-relational databases are designed to handle unstructured and semi-structured data. They do not rely on a fixed schema, allowing data to be added or removed without defining a schema first. Instead, they use a variety of data models to accommodate diverse data types and structures. This makes them well-suited for handling large, complex datasets that may evolve.
Types of Non-Relational Databases
In this section, we’ll explore types of non-relational databases such as graph, document, columnar, and key-value databases. We’ll discuss their characteristics, benefits, and use cases to help you understand which type of non-relational database may best fit your specific needs.
Graph Databases
A graph database is a type of database that uses graph structures to represent and store data. It is designed to handle complex data relationships and is optimized for querying and analyzing them. In a graph database, data is represented as nodes (vertices) and edges. Nodes represent entities or concepts, such as people, places, or things, and edges represent their relationships. For example, in a social network, a person would be represented as a node, and a friendship between two people would be represented as an edge connecting their nodes.
Each node and edge can have properties that describe their characteristics and attributes. For example, a person node may have properties such as name, age, and location, while an edge representing a friendship may have a property such as the date the friendship was established.
Graph databases are well-suited for scenarios where relationships between data points are important, such as social networks, recommendation engines, and fraud detection systems.
Document Databases
A document database is a type of NoSQL database that stores and retrieves data in the form of documents. Each document represents a single record or entity, can contain nested data structures and arrays, and can have a unique schema that evolves over time, making them highly scalable and flexible.
Document databases are designed to handle unstructured or semi-structured data, making them ideal for modern web applications that deal with various data types. They use a document-based format, such as JSON or BSON, and provide support for indexing and aggregation.
Document databases allow for the easy addition or removal of fields and documents without the need to define a schema and can handle large amounts of data and complex queries. In addition, document databases are easily scalable and can be distributed across multiple servers for better performance.
Columnar Databases
A columnar database is a type of database that stores and retrieves data by column rather than by row. In a columnar database, each column represents a specific attribute or property of the data, and each row contains values for all columns.
Here’s an example to help illustrate how columnar databases work:
Let’s say you have a large dataset with millions of rows and several columns, such as a customer database for an e-commerce website. The columns might include attributes like customer name, address, date of birth, and purchase history.
In a columnar database, each column is stored separately from the others. This means that when you query the database for customer data, the database only needs to read the columns that contain the attributes you’re interested in.
This makes columnar databases ideal for analytical queries, such as those used in data warehousing and business intelligence applications. They can quickly filter and aggregate large amounts of data and process complex queries more efficiently than row-based databases.
Key-Value Databases
A key-value database is a type of NoSQL database that stores and retrieves data as a collection of key-value pairs. Each key-value pair represents a piece of data, with the key acting as a unique identifier for the data.
Let’s say you are building a web application that requires fast and efficient access to user data, such as user profiles and preferences. A key-value database would be a good choice for storing this data because it can provide fast read and write access to the data, with minimal configuration required.
In a key-value database, each user profile would be stored as a key-value pair, where the key is a unique identifier for the user (such as a user ID), and the value is the user’s profile data (such as name, email address, and preferences). When the application needs to retrieve a user’s profile data, it can simply look up the key in the database and retrieve the corresponding value.
Key-value databases are also well-suited for caching data, such as frequently accessed data that is expensive to compute or retrieve.
When To Use Relational vs. Non-Relational Databases
The choice between using a relational database or a non-relational database depends on several factors, including the type of data, the size and complexity of the data, and the needs of your application.
Relational databases are a good choice when data has a well-defined schema, you need to ensure data consistency, and you need to support complex queries. They are designed to store structured data that adheres to a fixed schema, support transactions to maintain data consistency, and handle complex SQL queries involving multiple tables and joins.
Non-relational databases are a good choice when data is unstructured or semi-structured, you need to handle large volumes of data, and you need to support high throughput and low latency. They are designed to store data that does not adhere to a fixed schema, can scale horizontally to handle large amounts of data, and are optimized for fast read and write performance.
Relational databases:
- An e-commerce website that needs to store and manage transactional data, such as orders, payments, and inventory
- A financial application that requires strong data consistency and integrity, such as a banking system
- An enterprise application that requires complex querying and analysis of structured data, such as a CRM or ERP system
Non-relational databases:
- A social media platform that needs to store and retrieve user-generated content, such as posts, comments, and likes
- A real-time analytics application that requires fast and efficient data access, such as a recommendation engine or fraud detection system
- A content management system that needs to handle a large volume of unstructured content, such as images, video, and audio files
This blog post discusses additional scenarios in which you might choose one type of database over the other: Why Choose a NoSQL Database? There Are Many Great Reasons.
Features of Relational (SQL) Databases
Relational databases have several key features that make them popular for storing and managing data. We’ll explain in detail below.
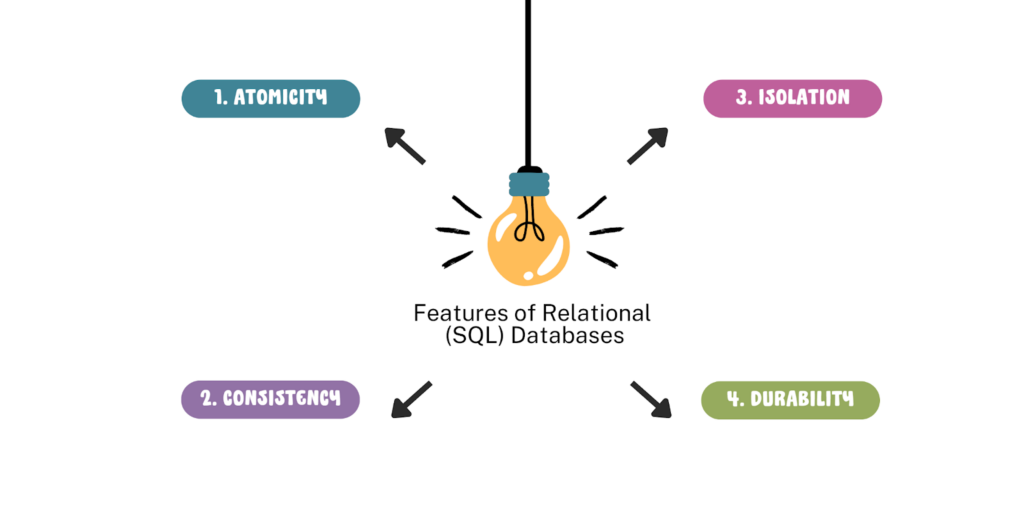
- Atomicity: Atomicity ensures that a transaction is treated as a single, indivisible unit of work. This means that a transaction must either be executed in its entirety or not at all. If any part of a transaction fails, the entire transaction is rolled back to its previous state.
- Consistency: Consistency ensures that the database remains in a valid state at all times. This means that any changes made to the database must adhere to a set of predefined rules or constraints.
- Isolation: Isolation ensures that multiple transactions can be executed concurrently without interfering with each other. This means that each transaction sees the database as the only one interacting with it, even though other transactions may be in progress simultaneously.
- Durability: Durability ensures that once a transaction has been committed to the database, it will remain there permanently, even in the event of a system failure or other disruption.
Pros and Cons of Relational (SQL) Databases
Relational databases have several advantages and disadvantages. Here are some of the key pros and cons of using a relational database:
Pros
- Data consistency: Relational databases use a structured approach to storing and managing data, which helps ensure data accuracy and consistency.
- Flexibility: SQL databases allow for complex queries and analysis of large datasets, making them useful for a wide range of applications.
- Security: SQL databases offer a range of security features, such as user authentication and access controls, to protect sensitive data.
- Strong data integrity: Relational databases enforce strict rules and constraints on data entry, which helps ensure that data remains consistent and accurate over time.
Cons
- Complexity: Setting up and managing a relational database can be complex and may require specialized knowledge.
- Cost: Relational databases can be expensive to set up and maintain, particularly for large-scale applications.
- Limited scalability: Although relational databases can scale well, they may not be suitable for extremely large or rapidly changing datasets.
- Performance: Relational databases can be slower than other types of databases when processing large numbers of transactions or complex queries.
Features of Non-Relational (NoSQL) Databases
Non-relational databases are designed to handle large amounts of unstructured or semi-structured data. We’ll explain in detail below.
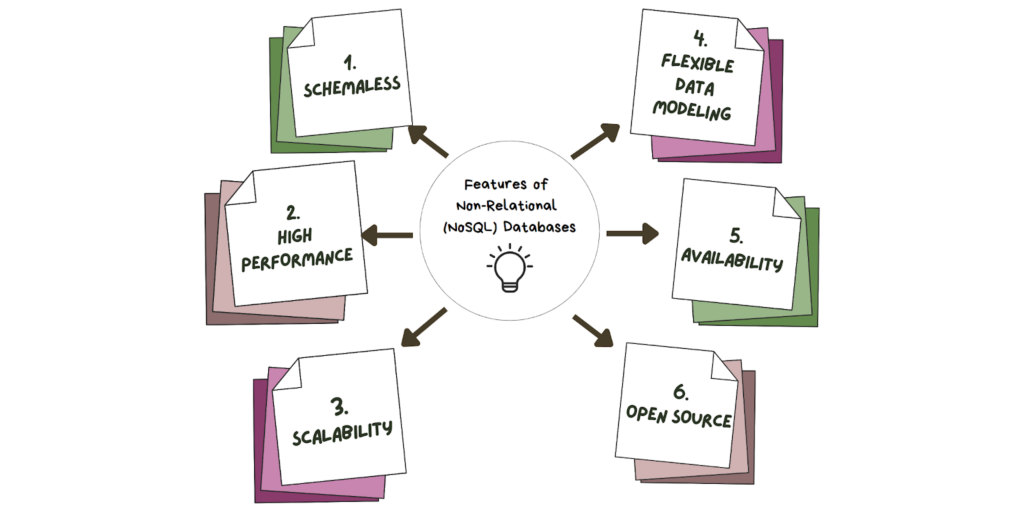
- Schemaless: NoSQL databases are schemaless, meaning they do not have a fixed structure or schema. Data can be stored in a flexible format.
- High performance: NoSQL databases are optimized for high performance and can handle large volumes of data and high traffic loads. They use distributed processing and caching to ensure fast response times, even with large amounts of data.
- Scalability: NoSQL databases are designed to scale horizontally, meaning they can easily handle large volumes of data by adding more servers to the database cluster.
- Flexible data modeling: NoSQL databases offer a flexible data model that can handle various data types, including structured, semi-structured, and unstructured data.
- Availability and fault tolerance: NoSQL databases are designed to be highly available and fault-tolerant. They use replication and sharding to ensure that data is always available, even if one or more servers fail.
- Open source: Many NoSQL databases are open source, meaning that their source code is freely available for developers to modify and enhance.
Pros and Cons of Non-Relational (NoSQL) Databases
Non-relational databases have several advantages and disadvantages. Here are some key pros and cons of using a non-relational database.
Pros
- Flexibility: Non-relational databases can handle unstructured or semi-structured data, making them well-suited for modern web applications and big data environments.
- Scalability: Non-relational databases are designed to be highly scalable, with the ability to handle large amounts of data and high levels of read and write traffic.
- Performance: Non-relational databases can provide high performance when handling complex queries and large amounts of data.
- Distributed architecture: Non-relational databases can be distributed across multiple servers, allowing for easy horizontal scaling and improved performance.
- Agile development: Non-relational databases allow for easy addition or removal of fields and documents without the need for schema modifications, making them well-suited for agile development methodologies.
- Cost-effective: Non-relational databases can be more cost-effective than traditional databases, especially for large-scale applications.
Cons
- Limited query support: NoSQL databases do not offer the same level of query support as relational databases. This can make it more difficult to perform complex queries and data analysis.
- Lack of standardization: NoSQL databases do not have a standardized query language like SQL, which can make it more difficult to develop and maintain applications that use these databases.
- Data consistency: NoSQL databases may sacrifice consistency for high scalability and performance. This means that data might not always be accurate or up-to-date.
- Learning curve: Since NoSQL databases use different data models and APIs than traditional databases, there can be a learning curve for developers who are used to working with SQL-based databases. This can require additional training and development time to become proficient.
- Limited tooling: Because NoSQL databases are relatively new, there may be limited tooling and community support compared to relational databases.
- Data security: NoSQL databases may not provide the same level of data security features as relational databases, such as access control and encryption.
Examples of Relational (SQL) Databases
There are several popular relational databases available in the market. Here are some examples of relational databases:
- MySQL: MySQL is an open-source relational database management system widely used in web applications. It is known for its speed, scalability, and ease of use.
- Oracle Database: Oracle Database is a proprietary relational database management system commonly used in enterprise-level applications. It provides strong support for ACID compliance, high availability, and scalability.
- Microsoft SQL Server: Microsoft SQL Server is a relational database management system commonly used in Windows-based environments. It provides strong support for enterprise-level applications, including business intelligence and data warehousing.
- PostgreSQL: PostgreSQL is an open-source relational database management system known for its robustness, flexibility, and support for advanced features such as full-text search and geospatial data.
- SQLite: SQLite is a lightweight, file-based relational database management system widely used in mobile and desktop applications. It is known for its simplicity, reliability, and portability.
Examples of Non-Relational (NoSQL) Databases
There are several popular non-relational databases available in the market. Here are some examples:
- Couchbase: Couchbase is a distributed database that supports both key-value and document data models. It is designed for high scalability, performance, and availability and supports features such as auto-sharding, in-memory caching, and full-text search. Couchbase is well-suited for handling large datasets and high write-throughput, making it popular for e-commerce, gaming, and social media applications.
- MongoDB: A document-oriented database that stores data in JSON-like documents.
- Apache Cassandra: A distributed database that stores data in a column-family format.
- Redis: A key-value store that can be used as a database, cache, and message broker.
- Amazon DynamoDB: A managed NoSQL database service provided by Amazon Web Services (AWS).
- Neo4j: A graph database that stores data in nodes and edges.
Conclusion
Databases are an essential component of modern software applications, providing a means of storing and managing data efficiently and securely. Relational databases, also known as SQL databases, are well-suited for applications with structured data and complex queries, while non-relational databases, also known as NoSQL databases, excel in applications with unstructured or semi-structured data and high scalability requirements. Both types of databases have their strengths and weaknesses, and the choice of relational vs. non-relational database will depend on the specific needs of the application and the available resources.
Check out these resources to continue learning about relational and non-relational databases and to discover how Couchbase can assist you in your journey.
Leave a comment
You must be logged in to post a comment.