On behalf of the Couchbase team, I’m absolutely thrilled to announce the General Availability of Ottoman 2.0.
Ottoman is an Object Document Mapper (ODM) library for Couchbase and Node.js that maps JSON documents stored in Couchbase to native JavaScript objects. Ottoman is powered by the Couchbase Node.js SDK and has built-in support for JavaScript and TypeScript.
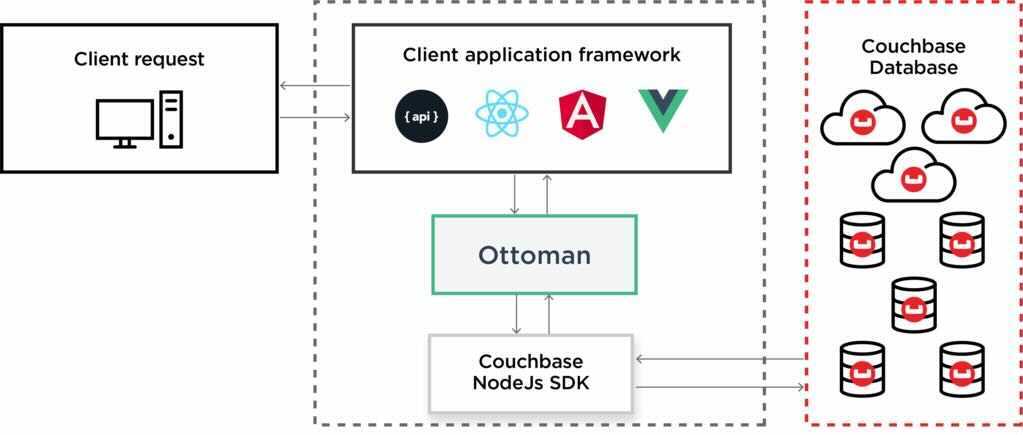
A typical web application consists of a front-end, a backend and a data store. Ottoman is a component in your backend that acts as a liaison between the client application framework and Couchbase, your data store.
Why You Need an ODM for Couchbase
Most client-server applications need some kind of abstraction that enables data access management. The term “data access” may sound trivial to some and can quickly be mistaken for basic CRUD (create, read, update and delete) operations, but that’s not entirely accurate.
Managing data in a modern application ranges from simply accessing data, to transforming, validating and modeling the data that suits the needs of the different users and systems. You may decide to choose a polyglot database and its related data access patterns, but either way, the quality of your data must be clean and legitimate.
If you’re a user coming from a relational database background, you might already be familiar with schemas and constraints that natively ship with these databases and claim to ensure data integrity. However, this can be a challenge when using a NoSQL database like Couchbase where the structure of data is fluid.
In such a case, you might feel like you have to build your own “schema manager” library that needs to define schema, build data models, validate data, ensure constraints, manage relationships, and much more. To build something like this yourself can quickly get out of hand. Not only are such systems hard to maintain and scale, but they could very well end up being error-prone and time-consuming, resulting in delayed deliverables and compromised data quality.
Finding a library that already encompasses all of the above is essential. This is where an ODM like Ottoman makes it all look easy.
How Ottoman Makes Node.js Development Easy
To understand how Ottoman helps your development teams, let’s take a closer look at the new features of Ottoman 2.0.
Examples in this blog are based on the travel-sample dataset and are for illustrative purposes only. Furthermore, this blog assumes that the user has some basic knowledge of scopes and collections in Couchbase 7.0.
Schemas & Data Models
JSON documents in Couchbase Server 7.0 can be organized into scopes and collections, giving end users the ability to build multi-tenant microservices-based applications.
In Ottoman, the data model instructs which scope and collection the document is stored within and provides numerous methods to access those documents. Schemas, on the other hand, define the shape of the document.
Let’s take a closer look at schemas and models with a simple example.
The code example below defines an airline schema that has five fields with some constraints and default values specified. For example, the country field can only have the values of United States and Canada and is required when creating a document. Capacity, on the other hand, is a number which can have a maximum value of 1000, if specified.
By default, schemas are “strict,” meaning Ottoman is instructed to ensure that the document saved in the database must conform to the schema structure defined, and any additional fields defined are ignored while saving. This strict option can be overridden using schema options.
|
1 2 3 4 5 6 7 |
const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default: 'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 } }) |
To use the airlineSchema, you have to create a model:
|
1 |
const airlineModel = model('Airline', airlineSchema, { scopeName: '_default' }) |
The first parameter is the name of the model which is also the name of the collection if not overridden using model options.
Ottoman documents represent a one-to-one mapping to documents stored in Couchbase. Each document is an instance of its model.
|
1 2 3 4 5 6 |
const airlineDocument = new airlineModel({ id: "10", type: "airline", name: "MILE-AIR", country:"United States" }) |
By calling the save method on the airlineModel, you end up creating a document within the Airline collection located under the _default scope of your Couchbase database.
Timestamps
The timestamp schema option instructs Ottoman to automatically add a createdAt and updatedAt datetime with a default value of current date and time whenever a document is created. Every time the document is updated, the updatedAt timestamp is updated as well.
The following is an example of adding a timestamp option to the airline schema:
|
1 2 3 4 5 6 7 |
const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default: 'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 } }, { timestamps: true }) |
This step (above) essentially extends the schema to implicitly add two new fields. You can also explicitly call them out if needed and override their names, as shown below:
|
1 2 3 4 5 6 7 8 9 |
const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default: 'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 } , created_at: { type: Date, default: new Date() }, updated_at: { type: Date, default: new Date() } }, { timestamps: { createdAt: 'created_at', updatedAt: 'updated_at' }}) |
Immutable
Designating a field as “Immutable” preserves the original values and prevents any mutation on the designated fields. In the timestamps definition of schema, each time the document is updated both created_at and updated_at fields are updated.
Ideally, however, you would not want your created_at field to be modified. That’s because it’s used to track when a document was created. This is where the immutable option comes in handy.
|
1 2 3 4 5 6 7 8 9 |
const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default: 'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 } , created_at: { type: Date, default: new Date(), immutable: true}, updated_at: { type: Date, default: new Date() } }, { timestamps: { createdAt: 'created_at', updatedAt: 'updated_at' } }) |
There are times when you want an immutable field to be updated. This is especially true in the case when a document is being created and the immutable field doesn’t have a default value or when for some other reason an update is unavoidable. In such a case, you can pass an additional option, new : true, on to the mutation operation.
This step assumes the airlineSchema has an immutable field contact, and you are using the model operation findOneandUpdate on airlineModel.
|
1 2 3 4 5 |
await airlineModel.findOneAndUpdate( { contact: { $like: '123456' } }, { contact: '45678' }, { new: true} ) |
Hooks
Hooks in Ottoman are middleware asynchronous functions you write and register with predefined events that you might want to act upon either before the event is triggered (pre-hooks) or after the event is triggered (post-hooks).
Hooks must be defined before models are defined, so it’s always good practice to define hooks alongside your schema definition in the workflow.
Earlier we noted that the updated_at field is updated upon mutation. Internally, this is accomplished with the help of a pre-hook listening to an update event.
|
1 2 3 4 5 6 |
airlineSchema.pre('update', (doc) => { doc[updatedAt] = typeof currentTime === 'function' ? currentTime() : currentTime return doc }) |
Typically, a hook takes in the event name as the first argument followed by a callback function that will eventually be called. Hooks can be registered to validate, save, update and remove events.
Some of the use cases you might consider for registering a hook include:
-
- Logging
- Cleanup of resources
- Sending notifications
- Updating other related documents
Plugins
One of the key benefits of using Ottoman is agile development, because you don’t need to repeat yourself. Rather, you end up building and using pluggable components that not only save time and effort but also produce code that’s easy to debug and maintain.
Plugins extend the behavior of hooks by allowing you to componentize certain capabilities such that you build them once and apply them to multiple schemas.
At this point, assume all of your schemas have a field called name, and you want to change the value to lowercase every time a document is saved. This can absolutely be achieved using a pre-hook on the save event, but you also have a requirement that this be applied to all schemas. This use case is where plugins can be used.
In this case, you’re defining a “lowercase” plugin that converts the value associated with the field name to lowercase:
|
1 2 3 4 5 6 |
const lowercase = (schema) => { schema.pre('save', (doc) => { doc['name'] = doc['name'].toLowerCase() return doc }) } |
Then, you instruct the schema to use the plugin:
|
1 |
airlineSchema.plugin(lowercase) |
You can also register plugins globally so that you can use them across projects.
Custom Schema Types
Out of the box, Ottoman provides some default schema types like string, number, boolean, date, array, etc. However, there are times where you might want to build a complex custom schema type that is reusable and well defined.
For instance, say you want to add website_url to the airlineSchema. What choices do you have? The only choice that’s available is string. There is nothing wrong with choosing a string, however, the only caveat is that there is no guarantee that the website_url is well formed. This is a typical use case where you should go with a custom schema type.
Creating a custom schema type is a three-step process:
1. Define the custom schema type:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class LinkType extends IOttomanType { constructor(name) { super(name, 'Link') } cast(value) { if(!isLink(String(value))) { throw new ValidationError(`Field ${this.name} only allows Link`) } return String(value) } } function isLink(value) { const regExp = new RegExp( /[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)?/gi ) return regExp.test(value) } |
The function isLink contains the logic to validate if a URL is well formed.
2. Register the custom schema type:
|
1 2 |
var LinkTypeFactory = (name) => new LinkType(name) registerType(LinkType.name, LinkTypeFactory) |
3. Use the custom schema type:
|
1 2 3 4 5 6 7 8 9 10 |
const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default: 'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 }, created_at: { type: Date, default: new Date(), immutable: true}, updated_at: { type: Date, default: new Date() }, website_url: { type: LinkType } }, { timestamps : { createdAt: 'created_at', updatedAt: 'updated_at' } }) |
Now, every time a document is created or updated, website_url is validated for a well-formed URL.
Custom Validators
There are times when checking for the integrity of a field goes beyond the use of basic constraints like default, min, max, or schema types. For instance, you might want to declare a field type as an array but you might also want to restrict the length of the array. This is when you should use custom validators.
Let’s extend the airlineSchema to accept an array of phone numbers but not to accept more than two phone numbers. First, you need to register the validator using the addValidators method as shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
addValidators({ phoneLength: (value) => { if(value.length > 2) { throw new Error(`Only two phone numbers are allowed at the maximum.`) } } }) const airlineSchema = new Schema({ id: { type: String }, type: { type: String, required: true, default:'airline' }, name: { type: String, required: true }, country: { type: String, required: true, enum: ['United States', 'Canada'] }, capacity: { type: Number, max: 1000 }, created_at: { type: Date, default: new Date(), immutable: true }, updated_at:{ type: Date, default: new Date() }, website_url: { type: LinkType } , phone_number: [{ type: String, validator: 'phoneLength' }] }, { timestamps : { createdAt: 'created_at', updatedAt: 'updated_at' } }) |
Reference
Data modeling – sometimes referred to as “document design” in the world of NoSQL databases – is an essential part of managing data. In a relational database, data is stored in tables and the relationships between tables are managed by referential keys also known as foreign keys.
In Couchbase, data of similar types is stored within the same collections, and they refer to other documents using a document key (or simply “key”). When documents are designed this way Ottoman not only provides the means to refer to them during schema design but also automagically populates them using the populate method.
To better understand this feature we will create a route by defining a routeSchema and a routeModel. Route has an airline field which refers to an airline model using the ref keyword.
|
1 2 3 4 5 6 7 8 9 10 |
const routeSchema = new Schema({ id: { type: String } , airline: { type: String, ref: 'Airline' }, destination_airport: { type: String }, source_airport: { type: String }, stops: { type: Number }, type: { type: String } }) const routeModel = model('Route', routeSchema, { scopeName: "_default" }) |
Below we create a route document which refers to the airline id 10.
|
1 2 3 4 5 6 7 8 |
const routeDocument = new routeModel({ id: "route1", type: "route", source_airport: "LAX", destination_airport: "DFW", stops: 0, airline: "10" }) |
By calling the save method on the routeModel you create a document within the Route collection located under the _default scope of Couchbase database.
Finally, we retrieve the document and populate the document.
|
1 2 |
const laxRouteDocument = await routeModel.findOne( { source_airport: 'LAX' } ) await laxRouteDocument._populate('airline') |
We retrieve the route document with airline data embedded within as shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "id": "route1", "type": "route", "source_airport ": "LAX", "destination_airport": "DFW", "stops": "0", "airline": { "id": "10", "type": "airline", "name": "MILE-AIR", "country": "United States" } } |
Query Builder
Ottoman has a very rich API that handles many complex operations supported by Couchbase and the SQL++ query language (formerly known as N1QL, as used below).
The Query Builder behind the scenes creates your N1QL statements for you. When using Query Builder you have three mode options:
Indexes
Indexes play an important role in accessing your documents from the Couchbase database.
Not having the right indexes in place can result in degradation of performance. Therefore, it is essential to know your document design (i.e., data model), and the queries you will use against them ahead of time. Building indexes is a crucial step when working with data. Ottoman offers three types of indexes that you can associate with your schema.
Index Type #1: NIQL
The N1QL index is the default index type used by Ottoman, and at times is also referred to as GSI or Global Secondary Indexes. During the bootstrapping process Ottoman automatically creates several secondary indexes, ensuring some of the basic operations are efficient out of the box. This is the most recommended type of index.
|
1 2 3 4 |
airlineSchema.index.findByName = { by: 'name', type: 'n1ql' } |
Index Type #2: Refdoc
The refdoc index type manages certains requirements where uniqueness needs to be guaranteed. There are a few important things that you need to be aware of before considering a refdoc index:
-
- Refdoc indexes are strictly managed by Ottoman and not by the Couchbase database. This means that any updates made to the document outside Ottoman will cause the refdoc index to go out of sync.
- Refdoc indexes create an additional binary document that holds references to the key of the document that’s being indexed. In a nutshell, you will see an additional document for each document you create that uses the refdoc index.
As an example, say you would like to ensure that website_url in airlineSchema is unique. You would create a refdoc index as shown below:
|
1 2 3 4 |
airlineSchema.index.findByUrl = { by: website_url, type: 'refdoc' } |
The general best practice for refdoc index is to use caution and handle data mutation strictly via Ottoman.
Index Type #3: Views
This index type is deprecated and will be soon removed. This index type exists for backward compatibility only. Use of this index is strongly discouraged.
Lean
Ottoman provides many model methods for retrieving documents from a collection. These methods include find, findById, findOne, etc.
The find method is by far the most popular and returns multiple documents based on the search condition specified. Retrieving a large number of documents at once from a collection comes with performance overhead that you might not see while working with a smaller set of documents. The overhead is mainly because all of the specified model methods return an instance of the Ottoman Document class which contains a lot of Ottoman-internal-state-of-change-tracking information.
Enabling the lean option tells Ottoman to skip instantiating a full Ottoman document and instead just return the plain old JavaScript object (POJO).
Although this may increase your performance, it is a tradeoff against Ottoman’s built-in features like change tracking, validations, hooks, and typical model methods like save, remove, etc. It is therefore recommended to use lean with extreme caution and awareness.
|
1 |
const result = await airlineMode.find( { name: { $like: 'american' } }, { lean: true } ) |
The result object in the above example will have all airline documents where the name is like american, but all these documents will be plain JavaScript (i.e., you lose all the magic that’s associated with an Ottoman document).
Model Methods
Ottoman’s model ships with several helper methods that serve different purposes. The following are some of the most frequently used model methods:
find: find is a generic method that uses the Query Service behind the scenes and is used to retrieve one or more documents from a Couchbase collection based on the filter condition supplied. An efficient way to use find warrants creation of appropriate secondary indexes (i.e., N1QL indexes).
The following find operation returns all airline documents where the country is the United States and ignores case sensitivity.
|
1 |
const docs = await airlineModel.find({ country: "United States" }, { ignoreCase: true }) |
findOneAndUpdate: find is a single document based on the filter condition passed to it and updates the document with new values provided. Passing an option upsert : true ensures that a new document is created in case no matching document is found.
|
1 |
await airlineModel.findOneAndUpdate({ id: "10" }}, { country: "Canada" }, { upsert: true }) |
Bulk operations: There are instances where you might want to mutate more than one document at a time. Ottoman ships with three model methods that help with this concern, and all of them use the Query Service behind the scenes:
-
- createMany: Creates multiple documents in a single call
- removeMany: Removes multiple documents in a single call
- updateMany: Updates multiple documents in a single call
The response status for all of the bulk operations will be “Success” as long as no error occurs, otherwise it will be “Failure.”
Debugging
As you have witnessed already, there are quite a few model operations that use the N1QL query language under the hood. Optimizing the N1QL query and building the right indexes is an essential part of development.
In order to accomplish this, it’s important to know what kind of N1QL query is being used by these model operations. Ottoman enables debugging which results in N1QL statements getting printed in the development console that can be effectively used by the developer to analyze and create indexes using the UI appropriately.
How Is Ottoman Different from the Node.js SDK?
Although Ottoman is powered by the Node.js SDK, it’s worth noting that there are certain features that are only available to you via Ottoman. You might want to consider the following features when choosing one over the other.
| Feature | Ottoman | Node.js SDK |
| Schema, constraints | ✅ | 🚫 |
| Validators | ✅ | 🚫 |
| Populate references | ✅ | 🚫 |
| Model methods (find, findOneAndUpdate, findOneAndRemove) |
✅ | 🚫 |
| Bootstrapping (create scopes, collections, indexes) |
✅ | 🚫 |
| Audit fields (timestamp) | ✅ | 🚫 |
| Refdoc index | ✅ | 🚫 |
| Hooks | ✅ | 🚫 |
| Plugins | ✅ | 🚫 |
| Immutable | ✅ | 🚫 |
| Query Builder | ✅ | 🚫 |
| Bulk operations | ✅ | 🚫 |
Other Benefits of Using Ottoman
I hope you’re excited and geared up to write your first application using Ottoman. The following are some of the top reasons why our customers prefer Ottoman:
Adaptability
You don’t need specialized skills, all you need is to know JavaScript or TypeScript and you are good to go.
Affordability
Enjoy all the benefits of being open source. No vendor lock-in, reduced capex, and no proprietary licenses, etc.
Supportability & Sustainability
Leave the burden of scanning and patching the software for security vulnerabilities on us. Get constant software updates to align with server releases and get full support from our support team and large developer community.
Agility
Be a leader in your space: build and deliver applications quickly and timely. There’s no need to build your data layer from scratch. Spend your time solving business problems rather than coding. Write smaller code blocks that are easy to maintain and read. Your code will look alike even after many iterations because it’s that simple.
Data Quality
Ensure quality data using schemas, validators, constraints and other available modules. Produce bug-free code with Ottoman’s plumbing which is the result of well-thought and crafted observation of repetitive design and development challenges. Ottoman solves a lot of common problems that otherwise can be difficult and error-prone if hand coded.
Get Started with Ottoman Today
Now that you have a basic understanding of why and when you should consider Ottoman for your next Node.js project, it’s time to get your hands dirty!
Here are some useful links to get you started:
Get started with a sample project here