새로운 쿼리 기능은 최신 릴리스인 Couchbase Server 5.5에서 두드러지게 나타납니다. 확인해 보세요. 발표 그리고 지금 바로 무료로 다운로드하세요..
이 글에서는 몇 가지 새로운 기능을 중점적으로 살펴보고 이를 사용하는 방법을 알려드리고자 합니다:
- ANSI JOIN - Couchbase의 N1QL에는 이미 JOIN이 있지만 이제 JOIN은 표준을 더 잘 준수하고 더 유연합니다.
- 해시 조인 - 특정 유형의 조인에서 해시 조인을 사용하면 성능을 향상시킬 수 있습니다(엔터프라이즈 에디션에서만).
- 집계 푸시다운 - GROUP BY를 인덱서로 푸시다운하여 집계 성능을 개선할 수 있습니다(엔터프라이즈 에디션에서만).
이 글의 모든 예제는 Couchbase와 함께 제공되는 "여행 샘플" 버킷을 사용합니다.
ANSI 조인
Couchbase Server 5.5까지는 조인이 가능했지만 두 가지 주의 사항이 있었습니다:
- 조인의 한쪽은 문서 키여야 합니다.
- 반드시
온키즈구문
Couchbase Server 5.5에서는 더 이상 다음을 사용할 필요가 없습니다. 온키즈를 사용하여 조인을 작성하는 것이 훨씬 더 자연스럽고 다른 SQL 방언과 일치합니다.
이전 JOIN 구문
예를 들어 이전 구문은 다음과 같습니다:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON KEYS r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
이렇게 하면 CMH 공항에서 출발하는 10개 노선이 해당 항공사 문서와 결합됩니다. 결과는 아래와 같습니다(테이블 보기로 표시하고 있지만 여전히 JSON입니다):
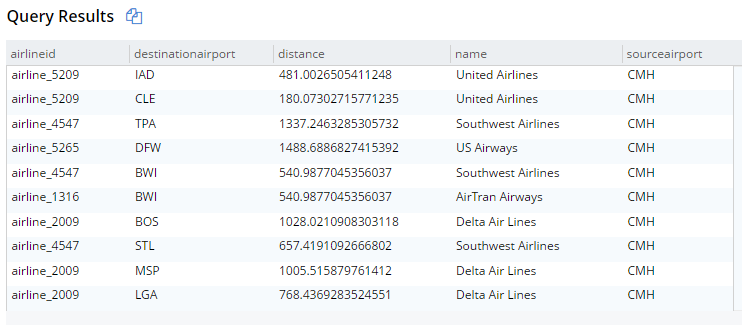
새로운 JOIN 구문
그리고 여기에 동일한 작업을 수행하는 새로운 구문이 있습니다:
|
1 2 3 4 5 6 7 |
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name FROM `travel-sample` r JOIN `travel-sample` a ON META(a).id = r.airlineid WHERE r.type = 'route' AND r.sourceairport = 'CMH' ORDER BY r.distance DESC LIMIT 10; |
유일한 차이점은 켜기. 대신 온키즈이제 켜기 =. 저처럼 관계적 배경을 가진 사람들에게는 더 자연스러운 일입니다.
하지만 그게 다가 아닙니다. 이제 더 이상 문서 키로만 가입할 수 없습니다. 다음은 JOIN 도시 필드에서
|
1 2 3 4 5 6 |
SELECT a.airportname, a.city AS airportCity, h.name AS hotelName, h.city AS hotelCity, h.address AS hotelAddress FROM `travel-sample` a INNER JOIN `travel-sample` h ON h.city = a.city WHERE a.type = 'airport' AND h.type = 'hotel' LIMIT 10; |
이 쿼리는 도시를 기준으로 공항과 일치하는 호텔을 표시합니다.
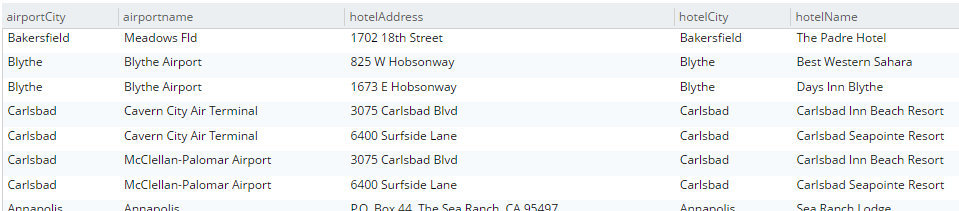
이 작업을 수행하려면 조인의 안쪽에 있는 필드에 인덱스가 생성되어 있어야 합니다. "travel-sample" 버킷에는 이미 도시 필드에 대한 미리 정의된 인덱스가 포함되어 있습니다. 다른 필드로 이 작업을 시도하면 "ANSI 조인 용어에 사용할 수 있는 인덱스가 없습니다..."와 같은 오류 메시지가 표시됩니다.
ANSI JOIN에 대한 자세한 내용은 다음을 참조하세요. N1QL JOIN 문서 전문.
참고: 이전 JOIN, ON KEYS 구문은 계속 작동하므로 기존 코드를 업데이트해야 할 걱정은 하지 않아도 됩니다.
해시 조인
그 안에는 조인을 수행할 수 있는 다양한 방법이 있습니다. 위의 쿼리를 실행하면 Couchbase에서 중첩 루프(NL) 접근 방식을 사용하여 조인을 실행합니다. 그러나 Couchbase에 조인을 실행하기 위해 해시 조인 대신 사용하세요. 때로는 해시 조인이 중첩 루프보다 성능이 더 우수할 수 있습니다. 또한 해시 조인은 인덱스에 종속되지 않습니다. 그러나 조인이 동일성 조인인지 여부에 따라 달라집니다.
예를 들어, '여행 샘플'에서는 이메일 필드에 랜드마크와 호텔을 연결할 수 있습니다. 이 방법은 호텔이 랜드마크인지 알아내는 데 가장 좋은 방법은 아니지만 이메일은 기본적으로 색인화되지 않기 때문에 요점을 잘 보여줍니다.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
위의 쿼리는 실행하는 데 매우 오랜 시간이 걸리며 시간이 초과될 수 있습니다.
구문
다음으로 명시적으로 호출해야 하는 해시 조인을 시도해 보겠습니다. 해시 사용 힌트.
|
1 2 3 4 5 |
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail FROM `travel-sample` l INNER JOIN `travel-sample` h USE HASH(BUILD) ON h.email = l.email WHERE l.type = 'landmark' AND h.type = 'hotel'; |
해시 조인에는 두 가지 측면이 있습니다. 빌드 및 PROBE. . 빌드 쪽은 인메모리 해시 테이블을 만드는 데 사용됩니다. 조인의 PROBE 쪽은 해당 테이블을 사용하여 일치하는 항목을 찾고 조인을 수행합니다. 일반적으로 이것은 빌드 쪽을 두 세트 중 더 작은 쪽에 사용하도록 설정합니다. 그러나 해시 힌트는 하나의 해시 힌트만 제공할 수 있으며 조인의 오른쪽에만 사용할 수 있습니다. 따라서 빌드 를 오른쪽에 표시하면 암시적으로 PROBE 를 왼쪽으로 이동합니다(또는 그 반대도 마찬가지).
빌드 및 프로브
그렇다면 왜 해시(빌드)?
사용해보니 INFER 및/또는 버킷 인사이트 랜드마크가 데이터의 약 101TB, 호텔이 약 31TB를 차지한다는 사실을 알게 되었습니다. 또한, 직접 사용해 본 결과 다음과 같은 사실을 알게 되었습니다. 해시(빌드) 가 약간 더 느렸습니다. 하지만 두 경우 모두 쿼리 실행 시간은 밀리초였습니다. 이메일 주소가 같은 호텔-랜드마크 쌍이 두 개 있는 것으로 나타났습니다.
해시 사용 는 카우치베이스에 시도 를 해시 조인해야 합니다. 그렇게 할 수 없는 경우(또는 Couchbase Server Community Edition을 사용하는 경우) 중첩 루프로 돌아갑니다. (참고로, 중첩 루프를 명시적으로 지정하려면 NL 사용 구문을 사용할 수 있지만 현재는 그렇게 할 이유가 없습니다).
자세한 내용은 해시 조인 영역으로 이동합니다.
총 푸시다운 집계
과거의 집계는 성능 측면에서 까다로웠습니다. Couchbase Server 5.5, 총 푸시다운 집계 이제 다음 항목이 지원됩니다. 합계, 카운트, 최소, 최대 및 평균.
이전 버전의 Couchbase에서는 다음과 같은 문에는 인덱싱이 사용되지 않았습니다. 그룹 기준. 이것은 추가적인 "그룹화" 단계가 필요하기 때문에 성능에 심각한 영향을 미칠 수 있습니다. Couchbase Server 5.5에서는 인덱스 서비스가 그룹화/집계를 수행할 수 있습니다.
예
다음은 총 호텔 수를 찾고 국가, 주 및 도시별로 그룹화하는 쿼리 예제입니다.
|
1 2 3 4 5 |
SELECT country, state, city, COUNT(1) AS total FROM `travel-sample` WHERE type = 'hotel' and country is not null GROUP BY country, state, city ORDER BY COUNT(1) DESC; |
쿼리가 실행되고 그 결과로 반환됩니다:
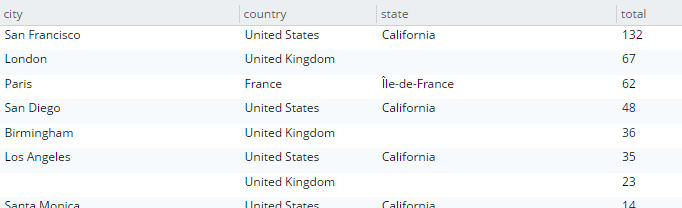
시각적 쿼리 플랜을 살펴보겠습니다(Enterprise 에디션에서만 사용할 수 있지만 커뮤니티 에디션에서는 원시 플랜 텍스트를 볼 수 있습니다).

사용 중인 유일한 인덱스는 유형 필드를 입력합니다. 그룹화 단계에서는 집계 작업을 수행합니다. 비교적 작은 여행 샘플 데이터 세트의 경우, 이 쿼리는 단일 노드 데스크톱에서 약 90ms가 소요됩니다. 하지만 그룹화할 필드에 인덱스를 추가하면 어떻게 되는지 살펴보겠습니다:
인덱싱
|
1 |
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel'; |
이제 위의 내용을 실행합니다. 선택 를 다시 쿼리합니다. 동일한 결과가 반환되어야 합니다. 하지만:
- 이제 단일 노드 데스크톱에서 약 7ms가 소요됩니다. 몇 초가 걸리긴 하지만, 보다 현실적인 대규모 데이터 세트에서는 그 차이가 엄청납니다.
- 쿼리 계획이 다릅니다.

이번에는 '그룹' 단계가 없다는 점에 유의하세요. 모든 작업은 인덱스 서비스로 푸시되고 있으며, 이 인덱스 서비스는 ix_hotelregions 인덱스입니다. 내 쿼리가 인덱스의 필드와 정확히 일치하기 때문에 이 인덱스를 사용할 수 있습니다.
인덱스 푸시다운이 항상 발생하는 것은 아니므로 쿼리가 특정 조건을 충족해야 합니다. 자세한 내용은 그룹 기준 및 집계 실적 영역으로 이동합니다.
요약
함께 카우치베이스 서버 5.5N1QL에는 훨씬 더 많은 표준을 준수하는 구문이 포함되어 있으며 그 어느 때보다 성능이 향상되었습니다.
지금 N1QL을 사용해 보세요. 다음을 수행할 수 있습니다. 엔터프라이즈 에디션 설치 또는 브라우저에서 바로 N1QL을 사용해 보세요..
질문이 있으신가요? I'm on 트위터 @mgroves. 또한 다음을 확인할 수도 있습니다. 트위터의 @N1QL. . N1QL 포럼 는 N1QL에 대한 심층적인 질문이 있는 경우 방문하기 좋은 곳입니다.
이 글을 작성해 주셔서 감사합니다.
몇 가지 사항을 이해해 주시면 감사하겠습니다:
1. 해시 조인은 항상 지시를 받아야 하나요? 즉, 옵티마이저가 스스로 해시 조인을 선택하지 않나요? 옵티마이저가 규칙 기반 옵티마이저이기 때문인가요? 그렇다면 향후 비용 기반 옵티마이저는 비용이 더 낮다고 판단되면 NL 조인보다 HASH 조인을 선택하나요?
2. HASH 조인에는 인메모리 해시 테이블을 보관하기 위한 메모리가 필요합니다. 이 메모리는 데이터 서비스, 인덱스 서비스 또는 쿼리 서비스를 실행하는 노드 중 어느 노드에서 사용되나요?
안녕하세요 푸라브,
다음에서 이러한 질문을 할 수 있습니다. https://www.couchbase.com/forums/c/sql/16 - 1) 네, 설명이 필요합니다. 옵티마이저와 HASH/NL 조인에 대해 자세히 알지 못합니다. 2) 인덱스인지 쿼리인지는 잘 모르겠지만 데이터 서비스는 아닐 것입니다.
감사합니다. 신속하게 되돌려 주셔서 감사합니다. 그럴게요.