NoSQL의 SQL Gene: N1QL 소개
NoSQL은 엄격한 스키마가 필요했던 관계형 움직임에 대한 반작용이었습니다. 관계형 데이터베이스는 이를 보완하기 위해 SQL 쿼리 언어를 번들로 제공하여 강력하게 검색하고 결과를 재구성합니다. 버전 4.0에서 Couchbase Server는 유전자 풀에 SQL 유전자와 NoSQL 유전자를 모두 포함합니다! SQL이 포함된 Couchbase Server에는 JSON 문서가 포함된 유연한 데이터 모델과 JSON 데이터를 가장 잘 표현하는 언어인 N1QL이라는 강력한 SQL 언어가 모두 포함되어 있습니다. JSON과 SQL의 조합은 새로운 디지털 경제를 뒷받침하는 간소화된 프로그래밍 기능과 강력한 새 엔터프라이즈 애플리케이션을 가능하게 하는 강력한 조합을 만들어냅니다.
Couchbase Server에 SQL Gene을 추가하는 이유는 무엇인가요?
대답하기 쉬운 질문입니다:
-
SQL은 데이터를 쿼리하는 가장 강력한 방법입니다. SQL은 40년 이상 사용되어 왔습니다. 같은 연령대의 다른 언어들은 대부분 더 이상 수요가 많지 않지만, SQL은 많은 최신 데이터 처리 플랫폼에서 여전히 선택되는 언어입니다.
-
SQL은 다양한 데이터 도구와 플랫폼 간에 데이터를 쿼리하기 위한 사실상의 표준입니다. SQL은 데이터 시각화 도구, 엔터프라이즈 보고 환경, 분석 앱, ETL 플랫폼에 이르기까지 다양한 도구의 중심에 자리 잡고 있습니다.
-
또한 수명이 길다는 점도 도움이 됩니다, SQL은 이미 많은 개발자의 도구 상자에 있는 도구입니다. 여러분과 컴퓨터 과학자 부모님의 유일한 공통점일지도 모릅니다.
| 카우치베이스 서버 4.0 릴리스 후보 다운로드 |
|---|
N1QL 살펴보기
Couchbase Server의 새로운 SQL 유전자를 통해 표현형 쿼리 언어 및 쿼리 엔진인 N1QL과 새롭고 강력한 인덱싱 메커니즘인 새로운 글로벌 보조 인덱스가 결합됩니다.
많은 분들께 익숙하실 겁니다. 이것이 바로 N1QL입니다:
|
1 2 3 |
<strong><em>SELECT * FROM bucket WHERE bucket.quantity>100 OR bucket.price < 9.95</em></strong> |
알고 있는 관계형 SQL과 Couchbase N1QL의 차이점을 구분할 수 없으신가요? 걱정하지 마세요... 둘은 매우 가까운 사촌입니다. 그러나 그 밑에는 N1QL만의 고유한 특징이 많이 있습니다.
-
N1QL은 SQL+JSON입니다: Couchbase Server는 JSON 기반에 구축된 유연한 스키마를 갖춘 문서 데이터베이스입니다. N1QL + JSON을 사용하면 개발이 간소화됩니다. N1QL은 JSON과 함께 작동하지만 JOIN과 같은 교차 문서 작업이나 NEST 및 UNNEST와 같은 JSON 데이터를 피벗할 수 있는 절을 지원함으로써 SQL 언어의 완전성을 손상시키지 않습니다.
-
N1QL은 새롭고 강력한 인덱서인 GSI로 성능을 제공합니다: 글로벌 보조 인덱스는 타의 추종을 불허하는 짧은 레이턴시와 확장성을 제공합니다. 글로벌 보조 인덱스는 까다로운 최신 빅 데이터 애플리케이션을 위한 최고의 스캔 지연 시간과 처리량을 제공하도록 구축되었습니다.
-
새로운 다차원 스케일링 모델로 N1QL을 확장합니다: N1QL 쿼리 환경과 새로운 글로벌 보조 인덱스는 핵심 데이터 작업과 독립적으로 확장되도록 설계되어 핵심 데이터 작업에서 인덱싱, 쿼리에 이르기까지 모든 워크로드에 대해 통합된 확장 모델을 선택해야 하는 다른 NoSQL 및 관계형 데이터베이스의 일반적인 단점을 제거했습니다.
N1QL의 3가지 고유 속성에 대해 자세히 살펴보겠습니다.
N1QL: SQL+JSON
관계형 SQL은 테이블과 열에 대해 작동하며 엄격한 스키마가 필요합니다. N1QL을 사용하면 모든 쿼리가 Couchbase Server의 JSON 데이터를 통해 실행됩니다. 엄격한 테이블과 열 구조를 다루거나 데이터 모델이 발전함에 따라 스키마를 변경하는 것에 대해 걱정할 필요가 없습니다.
N1QL은 JSON 문서가 Couchbase Server 버킷에서 생성 및 업데이트될 때 그 문서가 제시하는 스키마에 맞게 조정됩니다. 관계형 데이터베이스의 SQL과 달리 위에서 참조한 수량이나 가격과 같은 속성이 누락될 수 있습니다. 쿼리를 표현하여 해당 속성이 포함되지 않은 문서를 제외하거나 해당 속성이 있는 경우에만 쿼리할 수 있습니다.
|
1 2 3 |
<strong><em>SELECT * FROM bucket b1 WHERE b1.quantity>100 OR (b1.price IS NOT MISSING AND b1.price < 9.95)</em></strong> |
또 다른 중요한 차이점은 N1QL은 JSON 결과 집합을 제공하고 JOIN NEST 및 UNNEST와 같은 강력한 연산자를 사용하여 JSON을 변형할 수 있다는 점입니다.
|
1 2 3 4 5 6 7 8 9 10 11 |
<em><strong>"results": [ { "beer_name": "Benchwarmer Porter", "brewery_name": "Cooperstown Brewing Company", "country": "United States" }, { "beer_name": "Old Jubilation Ale", "brewery_name": "Avery Brewing Company", "country": "United States" }, ...</strong></em> |
기존 보고, 데이터 시각화 또는 ETL(추출-변환-로드) 도구를 사용하시는 분들에게 좋은 소식은 N1QL의 '행과 열' 스타일 결과 집합과 원활하게 통합할 수 있는 고충실도 ODBC 및 JDBC 드라이버를 사용할 수 있다는 점입니다. 덕분에 Simba ODBC 및 JDBC 드라이버를 사용하면 Tableau, Excel 또는 PowerBI 도구와 같은 자주 사용하는 도구와 ODBC/JDBC 드라이버를 함께 사용하여 전체 데이터 수명 주기 스토리를 통합할 수 있습니다.
새로운 글로벌 보조 인덱싱(GSI)을 사용한 고성능 쿼리
GSI는 카우치베이스 서버 4.0의 증분 맵 축소 기능을 갖춘 뷰 및 공간 인덱서에 더해 새롭고 강력한 인덱서를 제공합니다. GSI 기능은 N1QL과 쿼리 속도가 빠른 빅 데이터 애플리케이션을 위해 특별히 설계되었습니다. GSI는 쿼리 처리를 위한 광범위한 분산 수집의 영향을 최소화하는 고유한 아키텍처로 뛰어난 성능 향상을 달성합니다.
GSI는 독립적인 파티셔닝과 다차원 확장을 통한 확장성을 제공합니다(나중에 MDS에 대해 자세히 설명합니다). 또한 GSI는 ForestDB라는 강력한 스토리지 및 캐싱 엔진의 토대 위에 구축됩니다.
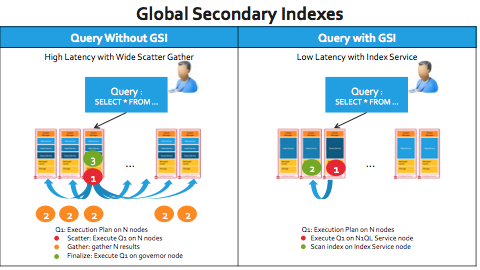
아래 그림에서 왼쪽과 오른쪽은 일반적인 쿼리의 대략적인 실행 단계를 보여줍니다.
-
GSI 없이 쿼리하기: 왼쪽의 사례는 분산 환경에서 쿼리를 실행하기 위해 얼마나 많은 기존 제품이 작동하는지를 보여줍니다. GSI가 없는 경우, 인덱스는 데이터 파티셔닝 체계에 따라 다음과 같이 분산됩니다. N 노드를 사용합니다. 일반적인 쿼리의 실행 계획에는 광범위한 흩어지다 N 노드, a N 노드에서 수집 를 사용하여 각 노드에서 결과를 캡처하고 최종 실행 쿼리의 최종 결과를 컴파일하는 함수입니다.
-
GSI로 쿼리하기: GSI를 사용한 실행 단계는 분산 수집할 필요가 없습니다. 쿼리는 단일 노드에 존재하는 인덱스에 도달하여 결과를 반환할 수 있습니다.
이전에 관계형 인덱스로 작업해 본 적이 있다면 GSI를 관리하는 방법이 매우 익숙할 것입니다.
|
1 2 3 4 |
<strong><em>CREATE INDEX friends_index ON user_profiles(friends.id) WHERE type=”user profile” USING GSI;</em></strong> |
새로운 확장성 모델: 다차원 확장
다차원 확장을 설명하기 위해 높은 수준의 서버 아키텍처부터 시작하겠습니다: Couchbase Server 4.0에서는 각 노드에 클러스터 관리자, 데이터, 인덱스 및 쿼리 서비스 구성 요소와 스토리지 엔진 및 관리형 캐시가 포함되어 있습니다.
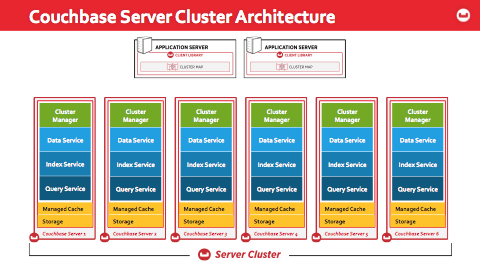
각 구성 요소에 대한 자세한 내용은 다음과 같습니다:
-
클러스터 관리자는 클러스터 운영을 관리합니다. 클러스터에 가입 및 탈퇴하는 노드 또는 리밸런싱과 같은 작업은 클러스터 관리자가 수행합니다.
-
데이터 서비스는 주어진 키와 상호 작용할 수 있는 get/set API를 통해 핵심 데이터 작업을 담당합니다. 데이터 서비스에는 이전 버전에 존재했던 증분 맵 축소 엔진인 보기 엔진도 포함되어 있습니다.
-
인덱스 서비스는 N1QL 쿼리를 위해 특별히 구축된 새로운 인덱스를 관리합니다. 새로운 글로벌 보조 인덱스는 유지 관리되며 인덱스 서비스를 통해 쿼리할 수 있습니다.
-
쿼리 서비스는 N1QL 쿼리 상호 작용을 관리합니다. 쿼리를 수신하고 실행하여 애플리케이션에 대한 최종 결과를 생성합니다.
-
모든 서비스에는 스토리지 및 캐싱 요구 사항을 관리하는 핵심 서비스가 함께 제공됩니다.
-
모든 스마트 클라이언트와 ODBC 및 JDBC 드라이버에는 주어진 API 호출을 가장 효율적으로 실행하기 위해 어떤 노드로 이동해야 하는지 설명하는 '클러스터 맵'이 함께 제공됩니다.
모든 노드에 동일한 구성 요소 집합이 포함되어 있어도 새로운 확장성 모델을 사용하면 각 노드에서 파란색으로 표시된 서비스를 탄력적으로 켜고 끌 수 있으며 데이터, 인덱스, 쿼리 작업 등의 서비스를 독립적으로 확장하는 '영역'을 생성하고 워크로드에 따라 영역별로 최적의 HW 설계를 선택할 수 있습니다.
모든 노드에 대해 단일 HW 설정을 선택하고, 모든 노드에서 모든 서비스를 활성화하고, 모든 노드에 부하를 분산하는 등 현재와 같은 방식으로 Couchbase Server 3.0을 사용하여 클러스터를 배포할 수 있습니다. 이것이 바로 기존의 균일한 수평적 스케일아웃입니다. 그러나 빠른 GET/SET과 같은 핵심 데이터 작업을 수행하기 위해 노드에서 수행해야 하는 작업과 GSI 인덱스 유지 관리, N1QL 쿼리 처리 등은 모두 경쟁적인 요구 사항을 가지고 있습니다. 작업의 지연 시간에 민감한 경우 동일한 노드를 공유하는 것이 항상 합리적이라고 할 수는 없습니다.
다차원 확장성 모델이 추가되어 클러스터를 개별 서비스(데이터, 쿼리, 인덱스)를 실행하는 '영역'으로 나누고, 각 영역별로 HW를 독립적으로 선택할 수 있습니다. 원하는 인덱싱 및 쿼리 유형에 맞는 최적의 HW를 선택하면서도 핵심 GET/SET 작업의 지연 시간을 낮게 유지할 수 있습니다.
아래 그림에서 클러스터에는 데이터, 인덱스, 쿼리 서비스를 구분하는 3개의 영역이 있습니다. 회색 상자는 특정 노드에서 비활성화된 서비스를 나타냅니다.
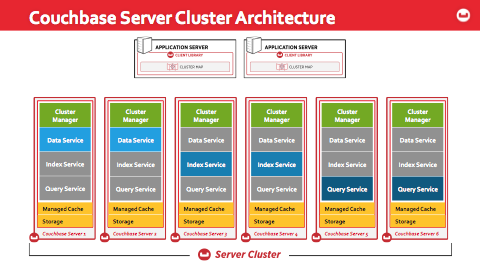
그 외에도... 훨씬 더 많은...
N1QL의 표면적인 부분만 살펴봤으며, 더 자세히 알아보려면 Couchbase Server 4.0의 릴리스 후보 버전을 다운로드하여 플레이해 보세요.
Couchbase Server 4.0을 다운로드하려면 여기를 방문하세요: 다운로드 페이지 N1QL을 시작하려면 다음을 방문하세요. N1QL 시작 가이드.
오늘 읽은 글 중 가장 냉정한 글에 감사드립니다. 이렇게 사려 깊은 글을 읽게 되어 반갑습니다! 인생에서 적어도 한 번은 양식을 작성해야한다고 확신합니다. 저는 간단한 서비스를 사용합니다.
https://goo.gl/qeKtu2을 사용하여 양식을 작성할 수 있습니다. 확실히 제 삶이 더 편해졌어요![...] 이러한 애플리케이션에서는 관리가 중요하므로 Couchbase 4.6에서는 Couchbase의 SQL [...]인 N1QL에 이를 위한 기능을 추가하고 있습니다.
[...] N1QL을 사용해 보시면 마음에 드실 거예요! N1QL에 대해 자세히 알아보려면 N1QL 소개 포스팅을 참조하세요. N1QL을 시작하려면 시작하기 튜토리얼 [...]을 참조하세요.