컴퓨팅의 목적은 숫자가 아니라 인사이트입니다. - 리처드 해밍
비즈니스를 운영하고, 무엇을 바꾸고 무엇을 바꿀지 분석한 다음, 비즈니스를 바꾸는 순환의 고리는 영원합니다. 올바른 분석을 수행하면 나선이 더 커질 것입니다. 그렇지 않으면 나선이 내려갈 것입니다.
카우치베이스는 다른 NoSQL 시스템의 선구자들과 마찬가지로 웹 2.0 세계의 극단적인 확장성, 성능 및 가용성 요구 사항을 해결하기 위해 만들어졌습니다. 단순한 키-값에서 출발한 Couchbase는 다음을 처리하도록 발전해 왔습니다. 쿼리, 검색 그리고 분석 - 대규모로 지원합니다. 각 엔진은 Couchbase의 다차원 아키텍처를 사용합니다. 쿼리 및 분석 서비스는 모두 N1QL을 사용합니다. 같은 언어를 사용하는 두 개의 서로 다른 엔진을 구축하는 이유는 무엇일까요? 왜냐하면...
모든 사람에게 적합한 한 가지 사이즈: 시대가 지나간 아이디어. - 마이클 스톤브레이커
쿼리 엔진은 운영 워크로드를 위해, 분석 엔진은 분석 워크로드를 위해 구축되었습니다. 우리는 비교 두 개의 엔진과 안내. 몽고DB는 단순한 워크로드를 처리하는 클러스터형 데이터베이스에서 데이터 레이크의 분석 및 쿼리를 위한 복잡한 워크로드에 이르기까지 비슷한 경로를 밟아왔습니다.
작년에 MongoDB는 분석 처리를 위한 클러스터의 분석 노드를 발표했습니다. 이 블로그에서는 분석 사용 사례에 대해 두 엔진을 비교하고 대조합니다.
카우치베이스: 상위 수준 아키텍처
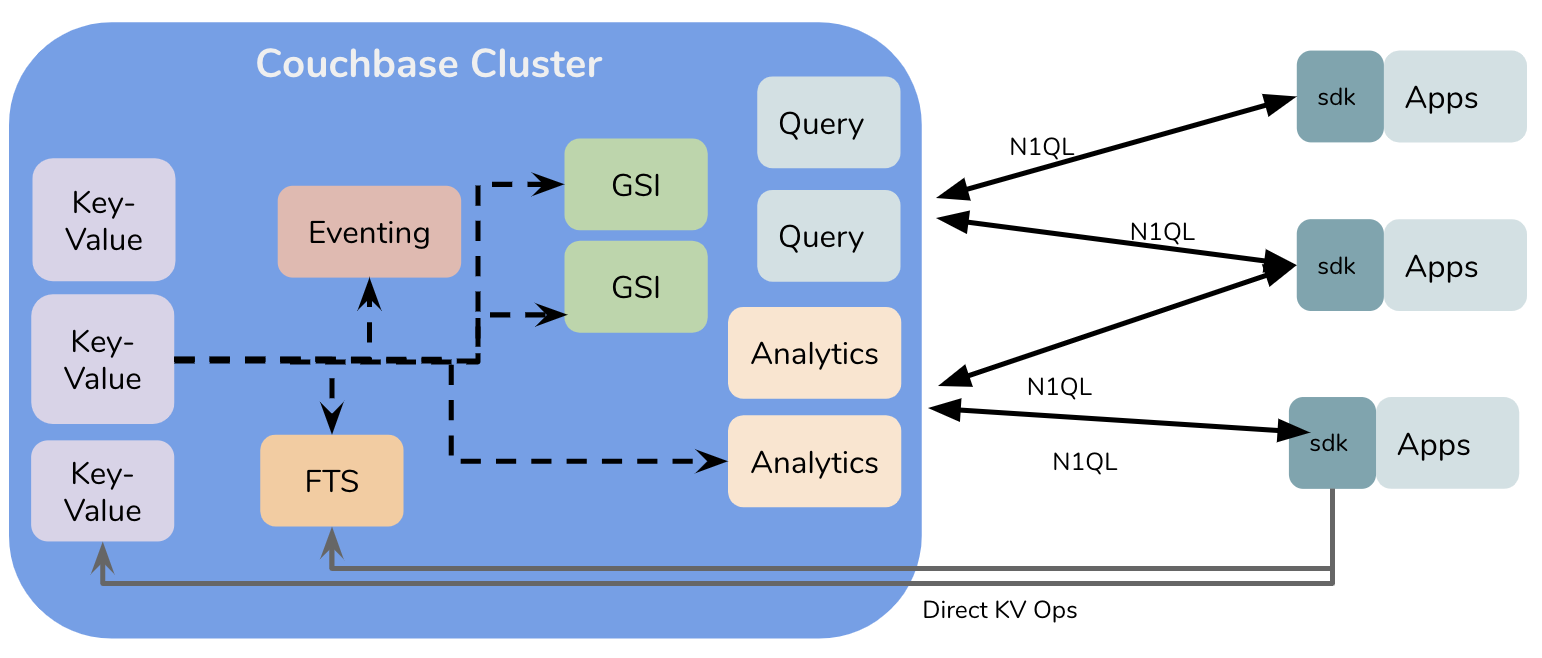
카우치베이스 애널리틱스 내부: 상위 수준 아키텍처
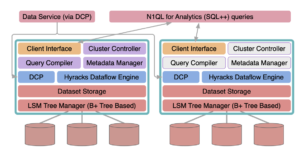
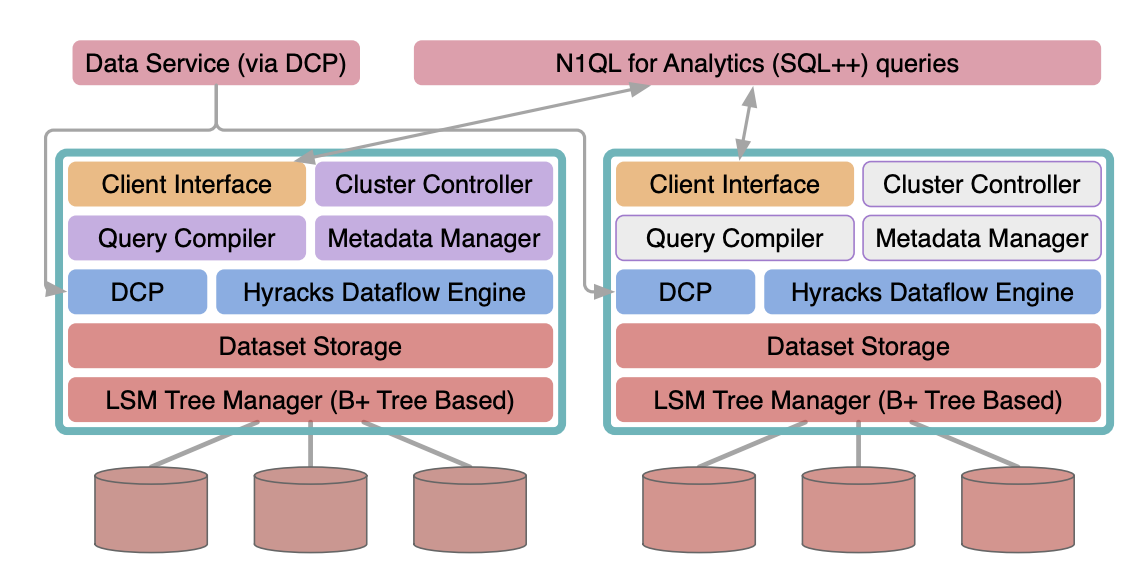
MongoDB 분석 노드: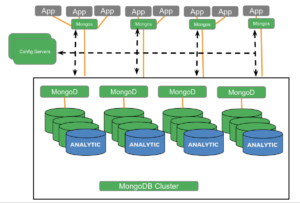
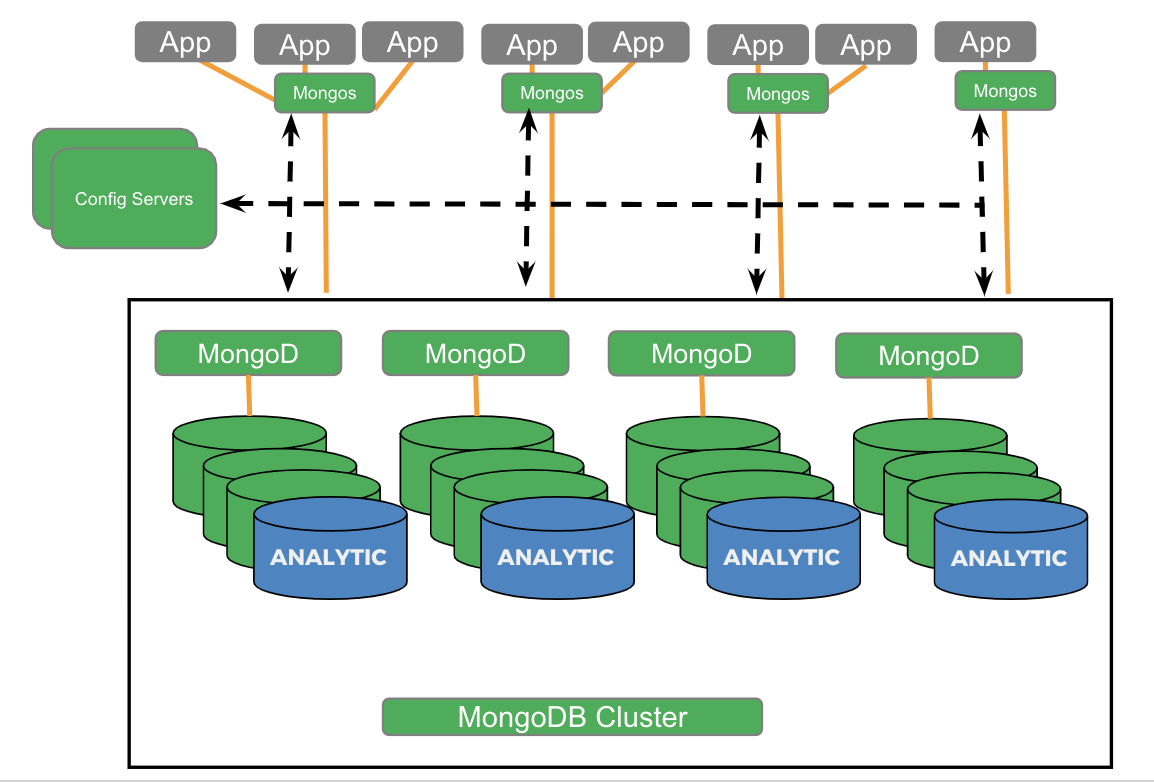
몽고DB 애널리틱스 노드와 카우치베이스 애널리틱스의 분석 지원 기능을 비교하고 대조해 보겠습니다.
| MongoDB 분석 노드 | 카우치베이스 애널리틱스 | |
| 문서 | https://docs.atlas.mongodb.com/reference/replica-set-tags/ | https://docs.couchbase.com/server/6.5/analytics/introduction.html |
| 아키텍처 | 운영 데이터의 전체 복사본이 있는 보조 복제 노드 세트를 사용합니다. 쿼리 언어가 동일하고(MQL), 쿼리 처리가 운영 워크로드와 동일합니다. | 운영 데이터의 사용자 정의 하위 집합을 가진 고유한 분석 노드. 쿼리 언어는 동일하며(N1QL), 쿼리 처리는 더 큰 데이터 집합을 위해 설계되었습니다(아래 참조). |
| 아키텍처 세부 정보 | Atlas 매핑된 분석 노드 | 카우치베이스 분석: 확장 가능한 NoSQL 데이터 분석을 위한 NoETL |
| 데이터 모델 | BSON | JSON |
| 쿼리 언어 | MQL - MongoDB 쿼리 언어 | N1QL - 일반 형식이 아닌 쿼리 언어, JSON용 SQL |
| 쿼리 페이지 | MongoDB 쿼리 | 애널리틱스 쿼리 |
| 쿼리 처리 | 분산 쿼리 처리를 위해 몽고와 몽고드를 사용하는 운영 쿼리 처리와 동일합니다. | 데이터의 대규모 병렬 처리(MPP)를 위해 설계된 분석 엔진입니다. 각 N1QL |
| 쿼리 최적화 도구 | 모양 기반 최적화 도구; 필요 계획 관리. | 규칙 기반 최적화 도구. 계획 관리가 필요하지 않습니다. |
| 설명 | 텍스트 및 그래픽. | 텍스트 및 그래픽. |
| 인덱싱 | 작업에서 인덱스를 생성하고 복사해야 합니다. | 애널리틱스 전용 인덱싱 |
| 병렬 처리 | 각 몽고드 노드는 기본 작업을 실행하고 몽고드는 이를 결합합니다(예: 최종 그룹 및 집계). | 복잡한 분석 쿼리를 효율적으로 처리하고 다음을 제공합니다.
원하는 확장 및 속도 향상 속성, 애널리틱스 서비스 는 동일한 종류의 최첨단 공유 무공유 MPP를 사용합니다. (대규모 병렬 처리) 기반 쿼리 처리 전략 [VLDB 논문에서 발췌] |
| 인덱싱 | 로컬 인덱싱 | 로컬 인덱싱 |
| 조인 - 언어 | $조회 연산자는 두 컬렉션 간의 단순 동일성 조인을 지원하며, 단순 스칼라 필드만 허용됩니다. 조인하기 전에 배열을 언와인드해야 합니다.
|
INNER JOIN, LEFT OUTER JOIN, NEST 및 UNNEST 작업.
|
| 쿼리 처리: 데이터 크기 | 집계() 파이프라인의 중간 단계는 다음을 초과할 수 없습니다. 100 MiB 크기입니다. 쿼리 작성자/사용자는 이를 허용하려면 특수 플래그를 사용해야 합니다. | 제한 없음; 중간 데이터(예: 해시 테이블, 정렬 데이터)가 커지면 디스크에 넘겨집니다. |
| 쿼리 처리: 조인 유형 | (대략) 왼쪽 외부 조인 | 내부 가입
왼쪽 외부 조인 |
| 검색 | 쿼리 내 검색을 지원합니다. 클라우드에서 Atlas 검색을 사용하고 온프레미스에서 기본 B-tree 기반 검색을 사용합니다. | 애널리틱스 서비스에는 검색 기능이 내장되어 있지 않습니다. 쿼리 내에서 검색을 결합하려면 FTS와 함께 쿼리 서비스를 사용해야 합니다. |
| 지원되는 쿼리 | find() 및 aggregate() | SELECT 문(SQL 및 SQL++에서) |
| 조인 유형(언어) | $lookup - 이것은 대략 다음을 통해 왼쪽 외부 조인입니다. | 내부 가입
왼쪽 외부 조인 |
| 조인 유형(구현) |
|
|
| 집계 | aggregate() 메서드를 통해 일반적인 그룹화 및 집계를 지원합니다. | GROUP BY 및 각 집계를 통한 공통 그룹화 및 집계를 지원합니다. 창형 집계에 대해서는 아래를 참조하세요. |
| 윈도우 집계 함수: 아마도 가장 멋진 SQL 기능일 것입니다. | 사용할 수 없습니다. | 완전히 지원.
RANK() PERCENT_RANK() DENSERANK() ROW_NUMBER() CUME_DIST() FIRST_VALUE() LAST_VALUE() NTH_VALUE() LEAD() NTILE() ratio_to_report() |
| 멀티 클러스터의 데이터 분석 | 분석된 모든 데이터는 단일 MongoDB 클러스터에서 가져온 것입니다. | 6.5: 분석된 모든 데이터는 단일 Couchbase 클러스터에서 가져온 것입니다.
6.6: 여러 Couchbase 클러스터에서 데이터를 수집하고 분석할 수 있습니다. |
| 외부 데이터 | S3 데이터에 대한 쿼리 처리를 지원합니다. BSON, CSV, TSV, Avro 및 Parquet 형식을 지원합니다. | 6.6: S3에서 외부 JSON, CSV 및 TSV 데이터 지원 |
| 외부 데이터 소스 | JDBC 드라이버를 통해 추가 데이터 소스를 지원합니다. 집계 파이프라인을 통해 집계 파이프라인과 통합되어 있으므로 기다려야 합니다, $sql 연산자. | 위에서 언급한 것을 제외하고는 없습니다. |
| 하위 쿼리 | 집계 파이프라인을 통한 하위 쿼리. | 표준 SQL 하위 쿼리. |
| 쿼리 계획 | 1TP4설명 | 설명 |
| 데이터 시각화 | 내장된 몽고DB 차트 | 기본 제공 데이터 시각화 없음 |
| 비즈니스 인텔리전스 | Knowi
Tableau 및 기타 ODBC, JDBC 호환 BI 엔진. |
Knowi
Tableau 및 기타 ODBC, JDBC 호환 BI 엔진. |
참조:
- JSON 쿼리를 위한 두 가지 SQL 기반 접근 방식 비교: SQL++와 SQL:2016
- SQL과 NoSQL - 쿼리 언어 비교를 위한 7가지 메트릭
- 카우치베이스 분석: 확장 가능한 NoSQL 데이터 분석을 위한 NoETL