




Vertrauen in AI

Beschleunigung der Inferenz
RAG automatisieren

Kosten kontrollieren



Vertrauenswürdige KI und Agenten
Um Bedenken hinsichtlich der Datensicherheit und der KI-Genauigkeit auszuräumen, ermöglicht Couchbase seinen Kunden, Daten und KI-Modelle sicher in ihrer Umgebung zu platzieren. Eingebaute Leitplanken und fortschrittliche Kontrollen schützen Anwendungen, während unser Agentenkatalog das Verhalten von Agenten in der Nähe kritischer Grenzen überwacht und sichtbar macht.

Geschwindigkeit im Maßstab
Agenten und KI-Anwendungen benötigen einen schnellen Zugriff auf verschiedene Daten, um optimale Nutzererfahrungen zu ermöglichen. Die Architektur von Couchbase liefert Antworten im Millisekundenbereich über verschiedene Datentypen und Anwendungsfälle hinweg und eliminiert die Ineffizienzen von Silo-Datenbanken. Um die Geschwindigkeit weiter zu erhöhen, minimiert das semantische Caching nicht benötigte LLM-Aufrufe, was sowohl die Inferenzzeit als auch die Kosten reduziert.
Leistungsstarke Vektorsuche
Die fortschrittliche Vektorsuche von Couchbase bietet Speicherung und Suche in Milliardengröße mit außergewöhnlicher Leistung und Genauigkeit. Sie ermöglicht reichhaltigen Kontext über Text, Bilder und mehr, während sie Skalierbarkeit, Sicherheit und nahtlose KI-Tool-Integration für kostengünstige LLM-Interaktionen gewährleistet. Mit einer Kapazität im Milliardenbereich und drei Indizierungsoptionen, die auf jeden Anwendungsfall zugeschnitten sind, können Sie mühelos vom Prototyp zur Produktion übergehen.

RAG-Pipelines automatisieren
Unternehmen übersehen oft unstrukturierte Daten, die KI-Modelle verbessern können. RAG macht die Antworten der Modelle besser. Couchbase automatisiert die Datenaufnahme, Vektorisierung und Indizierung, rationalisiert die Arbeitsabläufe und verbessert die Modellreaktionen. Es konvertiert unstrukturierte Daten (z.B. Text, PDFs, Bilder) in JSON und Vektoren und vektorisiert sie bei Aktualisierungen automatisch neu, um den Modellen mehr Kontext zu geben.

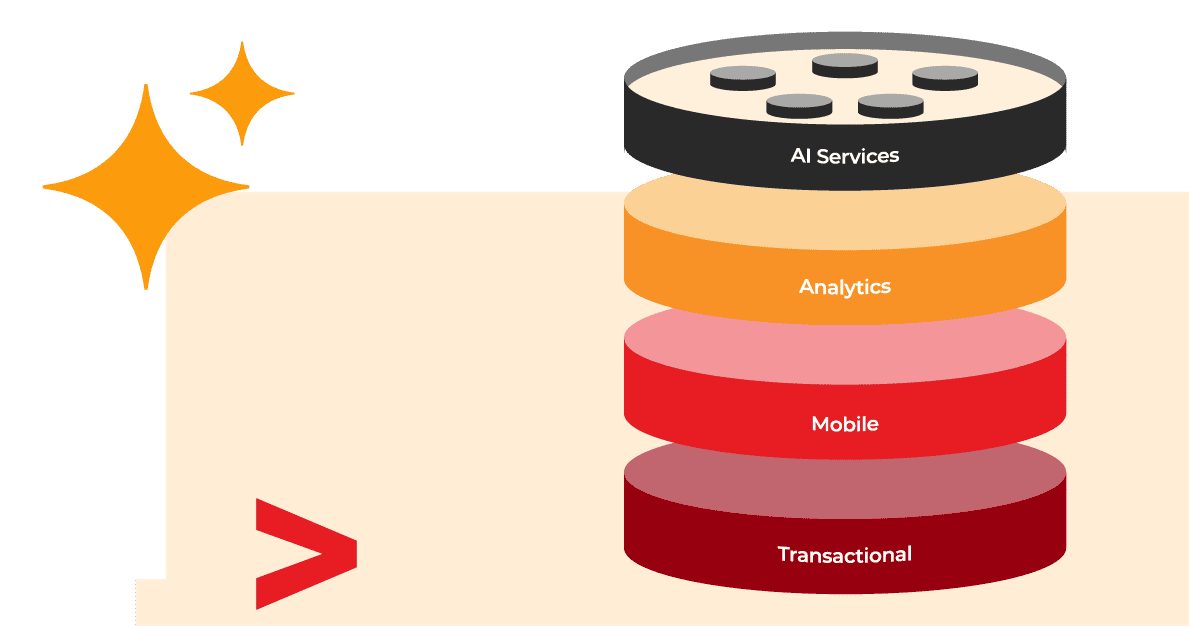
AI-Datenbank-Plattform
Capella ist die Grundlage für Ihre wichtigen KI-Anwendungen und Agenten. Capella hilft Ihnen:
- Speichern und verarbeiten Sie die Eingaben und Ausgaben der Agenten für jede LLM-Interaktion.
- Erstellen Sie Leitplanken und verwalten Sie das Kontextgedächtnis, damit die Agenten bei der Sache bleiben, ohne zu halluzinieren.
- Senken Sie Ihre Kosten für den KI-Austausch, indem Sie Capellas Content Caching, leistungsstarkes Vector Retrieval, semantisches Caching und Performance Tuning nutzen.
- Bringen Sie KI-Interaktionen näher an den mobilen Benutzer heran, um außergewöhnliche Erlebnisse zu schaffen.
Mit Capella gibt es keine Kompromisse bei Leistung, Umfang, Vielseitigkeit, Kosten oder globaler Reichweite.
Was die Kunden sagen


"Couchbase Echtzeit-Kommunikationsdaten und Abfragen mit hoher Gleichzeitigkeit verbessern die Leistung und Stabilität der KI-Assistenten-Anwendung erheblich."


"Die Skalierung mit MySQL hätte viel mehr Konfiguration erfordert und zu einer Datenfragmentierung geführt. Couchbase ermöglicht eine viel schnellere Implementierung."


"Die Möglichkeit, Abfragen einfach auszuführen, hat uns geholfen, die KI-Algorithmen für maschinelles Lernen zu verbessern, die wir heute einsetzen. Couchbase war die richtige Datenbank für uns".


"Wir haben festgestellt, dass die Replikationstechnologie für Couchbase über die Rechenzentren hinweg überlegen ist, insbesondere bei großen Workloads."
Reibungslose Integration mit unserem KI-Ökosystem von Partnern
Einfache Bereitstellung und Verwaltung Ihrer agentenbasierten Anwendungen mit führenden KI-Technologiepartnern.











Mit dem Bau beginnen
Besuchen Sie unser Entwicklerportal, um NoSQL zu erkunden, Ressourcen zu durchsuchen und mit Tutorials zu beginnen.
Capella kostenlos nutzen
Mit nur wenigen Klicks können Sie Couchbase in die Praxis umsetzen. Capella DBaaS ist der einfachste und schnellste Weg, um loszulegen.
Kontakt aufnehmen
Möchten Sie mehr über das Angebot von Couchbase erfahren? Wir helfen Ihnen gerne.