
Überblick: NoSQL-Struktur und Schlüsselkonzepte
Um besser zu verstehen, wie NoSQL-Datenbanken funktionieren, wird auf dieser Seite beschrieben, wie sie funktionieren:
Was ist eine NoSQL-Datenbank?
Eine NoSQL-Datenbank, kurz für "not only SQL (Structured Query Language)", ist eine nicht-relationale Datenbank, die für den Umgang mit unterschiedlichen und flexiblen Datenstrukturen konzipiert ist. Die NoSQL-Definition bezieht sich auf Datenbanken, die mehrere Modelle unterstützen, darunter Dokument-, Graph-, Key-Value-, Wide-Column- und Vektorspeicher, die im Vergleich zu herkömmlichen SQL-Datenbanken, die auf strukturierten Tabellen und festen Schemata basieren, eine größere Skalierbarkeit und Anpassungsfähigkeit bieten.
Die Bedeutung von NoSQL hat sich mit den Fortschritten bei CPUs, RAM, Cloud Computing und KI-Interaktionen weiterentwickelt, so dass moderne Datenbanken große Echtzeit-Datensätze effizient verwalten können. Durch Priorisierung horizontale Skalierung und Leistung sorgen NoSQL-Datenbanken für eine nahtlose Datenverteilung über mehrere Knoten hinweg, was sie zur bevorzugten Wahl für KI, Big Data und Echtzeitanalysen macht, wo herkömmliche Datenbanken oft nicht mithalten können.
NoSQL bezieht sich auf Datenbanken, die Daten in flexiblen Formaten speichern und dabei Modelle wie Dokumente, Key-Value-Stores und Vektorspeicher verwenden. Aufgrund ihrer Skalierbarkeit und Leistung sind sie ideal für moderne Anwendungen, die Echtzeitzugriff erfordern und große dynamische Arbeitslasten bewältigen.
Was ist der Unterschied zwischen SQL und NoSQL?
SQL- und NoSQL-Datenbanken sich darin unterscheiden, wie sie Daten speichern und abfragen. SQL-Datenbanken basieren auf Tabellen mit Spalten und Zeilen zum Abrufen und Schreiben strukturierter Daten, während NoSQL-Datenbanken flexible Datenmodelle verwenden, die besser für unstrukturierte und halbstrukturierte Daten geeignet sind.
SQLwurde erstmals in den 1970er Jahren eingeführt und wird heute von Entwicklern und Datenanalysten auf der ganzen Welt verwendet, um in relationalen Systemen gespeicherte Daten zu finden und darüber zu berichten. SQL-Datenbanken sind ideal für Anwendungen, die Datenintegrität erfordern und strukturierte Beziehungen und standardisierte Abfragen verwenden (z. B. Software für die Unternehmensressourcenplanung). Obwohl NoSQL gibt es bereits seit den 1960er Jahren, aber der Begriff wurde erst Anfang der 2000er Jahre geprägt, als es für Entwickler wichtig wurde, Datenbanken zu verwenden, die Daten für Echtzeitanwendungen speichern und abrufen können.
Es ist erwähnenswert, dass SQL erweitert wurde, um NoSQL-Zugriffsmuster zu unterstützen. Zum Beispiel unterstützen viele relationale Datenbanken jetzt JSON (JavaScript Object Notation) als Datentyp. Einige Datenbanken haben SQL sogar so erweitert, dass sie JSON-Strukturen direkt abfragen können, darunter Couchbase, das SQL++ (SQL für JSON) unterstützt.
Der Unterschied zwischen SQL- und NoSQL-Datenbanken liegt in ihrer Struktur und ihren Anwendungsfällen. SQL-Datenbanken verwenden Tabellen und sind daher ideal für Anwendungen, die eine starre Struktur und normalisierte Daten erfordern. Im Gegensatz dazu verwenden NoSQL-Datenbanken flexible Modelle, wodurch sie sich besser für die Verarbeitung unstrukturierter und halbstrukturierter Daten eignen und gleichzeitig einen Zugriff in Echtzeit ermöglichen.
Arten von NoSQL-Datenbanken
Dies sind die gängigsten Zugriffsmuster für NoSQL-Datenbanken:
- Schlüssel-Wert-Speicher gruppieren zugehörige Daten in unabhängigen Tabellen, in denen die Datensätze durch eindeutige Schlüssel identifiziert werden, um den Abruf zu erleichtern. Sie haben gerade genug Struktur, um den Wert relationaler Datenbanken widerzuspiegeln und gleichzeitig die Leistungs- und Zugriffsvorteile einer NoSQL-Datenzugriffsstruktur zu bieten. Schlüsselwertdaten lassen sich leicht in einem Cache speichern, in dem Daten, auf die häufig zugegriffen wird, für schnelles Lesen im Speicher gehalten werden. Schreibvorgänge, Aktualisierungen und neue Leseanforderungen werden programmgesteuert an den persistenten Speicher weitergeleitet. Bei Schlüsselwertspeichern haben atomare Zugriffsgeschwindigkeiten Vorrang vor Konsistenz, Isolierung und Dauerhaftigkeit.
- Dokumentendatenbanken speichern Informationen in erster Linie als logische Dokumente, einschließlich JSON-Dokumente. Diese Systeme können zum Beispiel auch XML-Dokumente oder binäre Objekte speichern. Aufgrund der Flexibilität des Formats und des Maßes an Kontrolle, das es Entwicklern bietet, werden Dokumentendatenbanken bei der Erstellung datengesteuerter Anwendungen bevorzugt.
- Breitspaltige und spaltenförmige Datenbanken Daten speichern nach Spalten anstelle von Zeilendie die Abfrageleistung für analytische Workloads und die Verarbeitung großer Datenmengen optimiert. Wie Key-Value-Stores weisen Wide-Column-Datenbanken einige grundlegende NoSQL-Strukturen auf, wobei Flexibilität, Datenverarbeitung und Aggregationsmöglichkeiten erhalten bleiben.
- Datenbanken durchsuchen ermöglichen Benutzern die Abfrage halbstrukturierter und unstrukturierter Daten wie Webseiten, Dokumente, Karten, JSON- und XML-Dokumente. Sie verwenden spezialisierte invertierte Indizes, um Schlüsselwörter innerhalb von Textkörpern zu finden, um relevante Daten zu finden, ähnlich wie beim "Googeln" von etwas im Internet.
- Graph-Datenbanken verwenden Graphstrukturen wie Knoten, Kanten und Eigenschaften, um die Beziehungen zwischen gespeicherten Datenelementen zu definieren. Graphdatenbanken sind nützlich für die Identifizierung von Beziehungsmustern in unstrukturiert und Halbstrukturierte Informationen, die Erstellung sozialer Netzwerke, die Zusammenstellung von Teilen, Organisationsstrukturen und Ontologien. Graphdatenbanken werden häufig in Empfehlungsmaschinen, bei der Erkennung von Betrugsmustern, bei prädiktiven KI-Funktionen und bei der Verknüpfung sozialer Netzwerke eingesetzt.
- Zeitreihen-Datenbanken ermöglichen es den Benutzern, Datenänderungen im Laufe der Zeit zu verfolgen und Anomalien in Aktienkursdiagrammen, Maschinenprotokollen, Gesundheitsmonitoren und Warnsystemen zu erkennen. Da sich Zeitreihendaten schnell ändern, erzeugen diese Datenbanken riesige Mengen an Informationen, was zu Skalierungsproblemen führen kann.
- Vektorielle Datenbanken die Genauigkeit von generativen KI-Modellen zu verbessern, indem sie Hinweise (Vektoren) liefern, die ihnen helfen, die "richtigen" Antworten zu finden innerhalb ihrer Trainingsdaten. Vektordatenbanken werden im Rahmen von RAG-Prozessen (Retrieval-Augmented Generation) eingesetzt, um Vektoreinbettungen zu speichern, die dazu beitragen, generative KI-Halluzinationen zu reduzieren und den Modellfortschritt zu erhalten.
Zu den beliebten NoSQL-Datenzugriffsmustern gehören Key-Value-Stores, Dokumentendatenbanken, spaltenübergreifende Datenbanken, Suchdatenbanken, Graphdatenbanken, Zeitreihendatenbanken und Vektordatenbanken. Diese NoSQL-Typen haben jeweils einzigartige Eigenschaften, wie Skalierbarkeit, Schema-Flexibilität und Abfrageeffizienz. Sie sollten sich eingehend mit ihnen befassen, um zu entscheiden, welche NoSQL-Datenbank Sie verwenden möchten.
Warum NoSQL verwenden?
Unternehmen bevorzugen NoSQL-Datenbanken aufgrund ihrer Fähigkeit, große Mengen an unterschiedlichen und wachsenden Daten zu verarbeiten. Zu den spezifischen Vorteilen von NoSQL-Datenbanken gehören:
- Skalierbarkeit: NoSQL-Datenbanken skalieren horizontal, indem sie die Daten auf mehrere Server verteilen, was sie ideal für große Arbeitslasten macht.
- Flexibilität: Im Gegensatz zu relationalen Datenbanken ermöglicht NoSQL eine schemalose Datenspeicherung, was die Speicherung und Verwaltung unstrukturierter oder halbstrukturierter Daten erleichtert.
- Hohe Leistung: NoSQL-Datenbanken, die für schnelle Lese- und Schreibvorgänge optimiert sind, reduzieren die Komplexität von Abfragen und verbessern die Reaktionszeiten von Echtzeitanwendungen.
- Verschiedene Datenmodelle: NoSQL-Datenbanken bevorzugen Key-Value-, Dokument-, Wide-Column-, Such- und Zeitserien-Datenmodelle und eignen sich daher ideal für zahlreiche Anwendungsfälle.
- Big Data und Echtzeitverarbeitung: NoSQL ist darauf ausgelegt, große Datenmengen zu verarbeiten, was es ideal macht für Big-Data-Analytik, IoT, Caching und Sitzungsmanagement.
- Cloud und verteiltes Rechnen: NoSQL-Datenbanken eignen sich gut für Cloud-Umgebungen, da sie eine hohe Verfügbarkeit und Fehlertoleranz über verteilte Systeme hinweg gewährleisten.
- Leichtere Entwicklung und Iteration: Mit NoSQL können Entwickler ihre vorhandenen SQL-Kenntnisse nutzen und eine Datenbank verwenden, die sich in bekannte Tools integrieren lässt, integrierte Entwicklungsumgebungen (IDEs)und Rahmenwerke.
Die vielseitige NoSQL-Datenbank von Couchbase ist besonders gut für KI-Anwendungen geeignet, da sie Folgendes bietet
1. Hohe Leistung und geringe Latenzzeit
- Speichererste Architektur: Verwendet ein verteiltes Memory-First-Design für schnelle Lese- und Schreibvorgänge, wodurch die Latenzzeit für KI-Modellinferenzen reduziert wird.
- Reaktionszeiten im Bereich von weniger als einer Millisekunde: Sicherstellung des Datenzugriffs in Echtzeit, was für folgende Anwendungsfälle entscheidend ist EmpfehlungsmaschinenBetrugserkennung und prädiktive Analytik.
2. Skalierbarkeit und verteilte Architektur
- Mehrdimensionale Skalierung: Kann horizontal oder vertikal skaliert werden, um massive KI-Datensätze und wachsende Arbeitslasten zu bewältigen.
- Rechenzentrumsübergreifende Replikation (XDCR): Unterstützt AI-Implementierungen in mehreren Regionen und mehreren Clouds mit hoher Verfügbarkeit.
3. Multimodell und flexible Datenspeicherung
- JSON-basierte NoSQL-Datenbank: Speichert unstrukturierte und halbstrukturierte Daten, was für KI-Anwendungen, die verschiedene Datensätze verarbeiten, unerlässlich ist.
- Unterstützung für die Vektorsuche: Hilft Entwicklern bei der Erstellung von Anwendungen mit Vektorsuche und integriert sich mit LangChain und LlamaIndex.
4. Integrierte KI- und Analysefunktionen
- SQL für JSON (SQL++): SQL-ähnliche Abfragen mit Indizierung, Volltextsuche und Analysen für das Training und die Inferenzierung von KI-Modellen.
- Eventing und Stream Processing: Ermöglicht KI-Einsichten in Echtzeit mit integrierten Funktionen und ereignisgesteuerter Architektur.
- Integration mit KI/ML-Frameworks: Arbeitet mit TensorFlow, PyTorch und Apache Spark für das Training und die Bereitstellung von KI-Modellen.
5. Multicloud- und Edge-KI-Einsatz
- Multicloud-Umgebung: Läuft auf Amazon Web Services (AWS), Microsoft Azure und Google Cloud, sodass Entwickler KI-Anwendungen in der Cloud ihrer Wahl entwickeln und bereitstellen können.
- Unterstützung von Edge Computing: Ideal für Echtzeit-KI-Anwendungen auf mobilen und IoT-Geräten, die die Abhängigkeit von der Cloud verringern und die Reaktionszeiten verbessern.
6. Sicherheit und Einhaltung der Vorschriften
- Sicherheit auf Unternehmensniveau: Bietet integrierte Verschlüsselung, rollenbasierte Zugriffskontrolle (RBAC) und die Einhaltung von Vorschriften wie GDPR, HIPAA und SOC 2.
- Datenisolierung und -verwaltung: Unterstützt KI-gesteuerte Compliance-Überwachung und Betrugserkennung.
7. Kosteneffizienz
- Hohe Leistung zu niedrigeren Kosten: Reduziert die Kosten für die Cloud-Infrastruktur durch effiziente Verwaltung von Ressourcen und Minimierung der Datenübertragung.
- Multimodale Datenbank: Ermöglicht Entwicklern die Speicherung und Abfrage mehrerer Datentypen, wodurch der Bedarf an zusätzlichen Datenbanken reduziert und potenzielle Integrationskosten, Lizenzgebühren und Cloud-Ausgaben eingespart werden.
Spezifische Anwendungsfälle für KI-Anwendungen mit Couchbase sind unter anderem:
- Personalisierte Empfehlungen: Elektronischer Handel und Streaming-Dienste
- Betrugsaufdeckung und Risikoanalyse: Bankwesen und Cybersicherheit
- Chatbots und agentenbasierte KI: Kundenbetreuung und virtuelle Assistenten
- IoT und KI: Intelligente Geräte und autonome Systeme
Unternehmen bevorzugen NoSQL-Datenbanken wegen ihrer Flexibilität, Skalierbarkeit und hohen Leistung bei der Verarbeitung großer Mengen unterschiedlicher und wachsender Daten. Darüber hinaus nutzen NoSQL-Datenbanken die horizontale Skalierung, d. h. die Verteilung von Daten auf mehrere Server, um die Leistung bei wachsenden Arbeitslasten aufrechtzuerhalten. Dank dieser Fähigkeiten eignen sie sich gut für KI-Anwendungen, IoT-Systeme, adaptive Felddienste sowie Caching und Sitzungsmanagement.
Global-2000-Unternehmen setzen zunehmend auf NoSQL-Datenbanken, um ihre geschäftskritischen Anwendungen zu betreiben:


"Wir haben festgestellt, dass die Replikationstechnologie für Couchbase über die Rechenzentren hinweg überlegen ist, insbesondere bei großen Workloads."


"Mit weniger als der Hälfte der Server können wir die Leistung steigern und erhalten eine wesentlich besser skalierbare Architektur."


"Couchbase ist ein hochskalierbarer verteilter Datenspeicher, der eine entscheidende Rolle in unseren Caching-Systemen spielt."


"Boxen der Enterprise-Klasse kosten eine Menge Geld. Wir können mit handelsüblicher Hardware skalieren und hochverfügbar sein."
NoSQL-Tutorial
Wie ist NoSQL im Vergleich zu relationalen Datenbanken? Schauen wir uns das einmal genauer an. Das folgende Tutorial veranschaulicht eine NoSQL-Anwendung zur Verwaltung von Lebensläufen. Sie interagiert mit Lebensläufen als Objekt (d. h. als Benutzerobjekt), enthält ein Array für Fähigkeiten und eine Sammlung für Positionen. Um einen Lebenslauf in eine relationale Datenbank zu schreiben, muss die Anwendung alternativ das Benutzerobjekt "schreddern" (normalisieren).
Um diesen Lebenslauf zu speichern, müsste die Anwendung sechs Zeilen in drei Tabellen einfügen, wie in Abbildung 1.
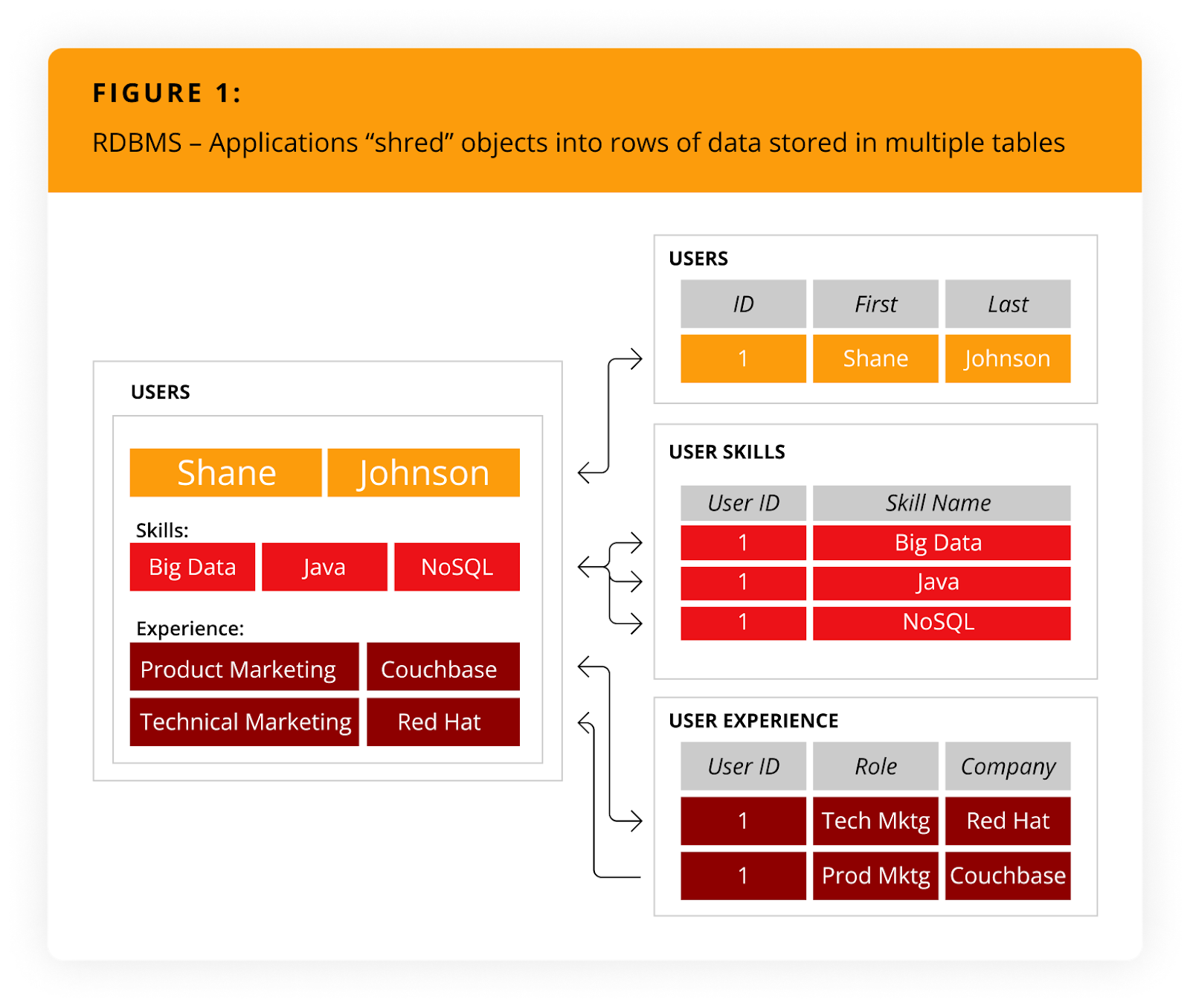
Klicken zum Erweitern
Um dieses Profil zu lesen, müsste die Anwendung sechs Zeilen aus drei Tabellen lesen, wie in Abbildung 2.

Klicken zum Erweitern
JSON beseitigt nicht nur den objektrelationalen Impedanzunterschied, sondern auch den Overhead von objektrelationalen Mapping-Frameworks (ORM). Es vereinfacht die Anwendungsentwicklung, da Objekte gelesen und geschrieben werden können, ohne sie zu normalisieren (d. h. ein einzelnes Objekt kann als einzelnes Dokument gelesen oder geschrieben werden), wie in Abbildung 3.
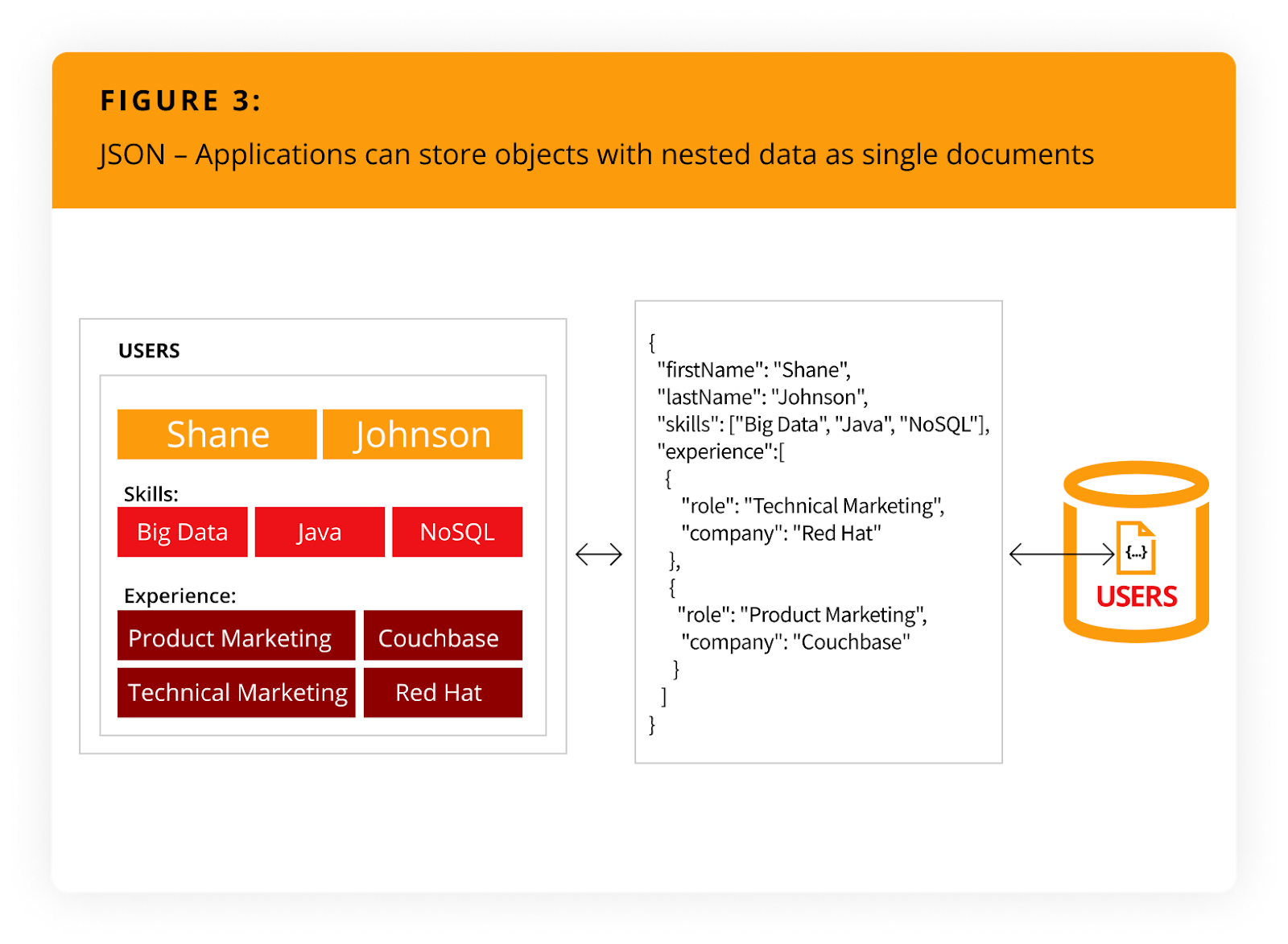
Klicken zum Erweitern
Was ist mit Abfragen und SQL?
Manche mögen argumentieren, dass die Abfrage von NoSQL-Datenbanken schwieriger ist, aber das ist ein weit verbreiteter Irrglaube. Die inhärente Flexibilität dokumentenorientierter NoSQL-Datenbanken ermöglicht es ihnen, strukturierte und unstrukturierte Daten gleichermaßen gut zu verarbeiten, und neue Tools ermöglichen eine schnellere Abfrage als je zuvor.
Couchbase unterstützt SQL++die es Entwicklern ermöglicht, die Leistungsfähigkeit von SQL und die Flexibilität von JSON zu nutzen. Es unterstützt nicht nur standardmäßige SELECT / FROM / WHERE-Anweisungen, sondern auch Aggregation (GROUP BY), Sortierung (SORT BY), Joins (LEFT OUTER / INNER) und die Abfrage verschachtelter Arrays und Sammlungen. Außerdem kann die Abfrageleistung mit zusammengesetzten, partiellen und abdeckenden Indizes verbessert werden.
SELECT RTRIM(p.FirstName) + ' ' + LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
SELECT RTRIM(p.FirstName) || ' ' || LTRIM(p.LastName) AS Name, d.City
FROM AdventureWorks2025.Person.Person AS p
INNER JOIN AdventureWorks2025.HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
INNER JOIN
(SELECT bea.BusinessEntityID, a.City
FROM AdventureWorks2025.Person.Address AS a
INNER JOIN AdventureWorks2025.Person.BusinessEntityAddress AS bea
ON a.AddressID = bea.AddressID) AS d
ON p.BusinessEntityID = d.BusinessEntityID
ORDER BY p.LastName, p.FirstName;
NoSQL-Datenbanken speichern Daten in flexiblen JSON-Dokumenten. Dadurch entfällt die Notwendigkeit eines komplexen objektrelationalen Mappings (ORM) und die Verwaltung strukturierter und unstrukturierter Daten wird erleichtert. Dieser Ansatz vereinfacht die Anwendungsentwicklung, da Objekte in einem einzigen Dokument gespeichert und abgerufen werden, anstatt sie in mehrere Tabellen aufzuteilen. Couchbase erweitert die Abfragemöglichkeiten mit SQL++, das die vertraute SQL-Syntax unterstützt.
Warum relationale Datenbanken unzureichend sind
Relationale Datenbankmanagementsysteme wurden in der Ära der Großrechner und Geschäftsanwendungen entwickelt - lange vor dem Internet, der Cloud, Big Data, mobilen Anwendungen, künstlicher Intelligenz und den heutigen massiv interaktiven Unternehmen. Diese Datenbanken wurden für die Ausführung auf einem einzigen Server entwickelt - je größer, desto besser, und ihr Design war darauf ausgerichtet, die Nutzung knapper Ressourcen für Speicher, RAM und Verarbeitung zu optimieren. Die einzige Möglichkeit, die Kapazität dieser Datenbanken zu erhöhen, bestand darin, die Server (Prozessoren, Arbeitsspeicher und Speicher) aufzurüsten, um sie zu vergrößern. Im Laufe der Jahrzehnte wurden die meisten der ursprünglichen Designbeschränkungen, einschließlich Normalisierung, starker Datentypisierung und referenzieller Integrität, gelockert oder beseitigt.
NoSQL-Datenbankverwaltungssysteme sind aufgrund des exponentiellen Wachstums des Internets und der Zunahme von Webanwendungen entstanden. Google veröffentlichte die Bigtable Forschungspapier im Jahr 2006, und Amazon veröffentlichte die Dynamo-Forschungspapier im Jahr 2007 - in diesen Papieren wurde detailliert beschrieben, wie die beiden Unternehmen ihre Datenbanken konzipierten, um die sich entwickelnden Anforderungen von Unternehmen zu erfüllen. Letztendlich konzentrierten sich moderne Datenbanken auf Entwicklung mit Agilität, Erfüllung der sich ändernden Anforderungenund Beseitigung der Datentransformation.
Relationale Datenbanken wurden ursprünglich für Umgebungen mit nur einem Server entwickelt, um begrenzte Ressourcen zu optimieren, doch mit zunehmendem Datenbedarf stießen sie auf Probleme bei der Skalierbarkeit. Mit dem Aufkommen des Internets und der Webanwendungen wurden NoSQL-Datenbanken entwickelt, um diese Beschränkungen zu überwinden, wobei der Schwerpunkt auf Flexibilität, Skalierbarkeit und der Reduzierung der Komplexität der Datentransformation lag.
Schlussfolgerung
Wofür werden NoSQL-Datenbanken also verwendet und warum sind sie wichtig? Da Unternehmen auf künstliche Intelligenz umsteigen - ermöglicht durch Cloud, Mobile, Social Media, maschinelles Lernen und GenAI-Technologien - Entwickler und Betriebsteams müssen Web-, Mobil- und IoT-Anwendungen schneller und in größerem Umfang erstellen und pflegen. Flexible, hochleistungsfähige NoSQL-Datenbanken sind zunehmend die Datenbanktechnologie ihrer Wahl.
Tausende von Global 2000 Unternehmen Entwickler und Millionen von Entwicklern, die in kleineren Unternehmen und Startups arbeiten, haben NoSQL übernommen. Für viele begann der Einsatz von NoSQL mit einem Cache, einem Proof of Concept oder einer kleinen Anwendung und wurde dann auf gezielte unternehmenskritische Anwendungen ausgeweitet, bevor er zur Grundlage für die gesamte Anwendungsentwicklung wurde.
Mit NoSQL-Datenbanken können Unternehmen flexibler entwickeln, in beliebigem Umfang arbeiten und die Leistung und Verfügbarkeit bereitstellen, die erforderlich sind, um die Anforderungen der digitalen Wirtschaft zu erfüllen.



Mit dem Bau beginnen
Besuchen Sie unser Entwicklerportal, um NoSQL zu erkunden, Ressourcen zu durchsuchen und mit Tutorials zu beginnen.
Capella kostenlos nutzen
Mit nur wenigen Klicks können Sie Couchbase in die Praxis umsetzen. Capella DBaaS ist der einfachste und schnellste Weg, um loszulegen.
Kontakt aufnehmen
Möchten Sie mehr über das Angebot von Couchbase erfahren? Wir helfen Ihnen gerne.