
Was ist eine Schlüssel-Wert-Datenbank?
Eine Schlüssel-Wert-Datenbank ist ein Typ von NoSQL Datenbank, die Daten als eine Sammlung von Schlüssel-Wert-Paaren speichert, wobei jeder eindeutige Schlüssel mit einem bestimmten Datenwert verknüpft ist. Die Geschwindigkeit und Effizienz von Key-Value-Datenbanken machen sie zu einer guten Wahl für einfache Datenspeicher- und -abrufanforderungen, wenn der Schwerpunkt auf hoher Leistung liegt. Ihre schemafreie Struktur ermöglicht eine flexible Datendarstellung, so dass sie sich für eine Vielzahl von Anwendungen eignen, von Caching-Systemen bis hin zu Echtzeit-Analysen.
Diese Seite umfasst:
- Wie Schlüssel-Wert-Datenbanken funktionieren
- Merkmale von Schlüssel-Wert-Datenbanken
- Anwendungsfälle für Key-Value-Datenbanken
- Vor- und Nachteile von Key-Value-Datenbanken
- Beispiele für Key-Value-Datenbanken
- Couchbase und Schlüsselwertspeicher
- Schlussfolgerung
Wie Schlüssel-Wert-Datenbanken funktionieren
Um zu veranschaulichen, wie eine Key-Value-Datenbank funktioniert, werden wir ein einfaches Beispiel aus der Couchbase Key-Value-Datenbank verwenden. Couchbase speichert Daten in Form von Dokumenten wie dem untenstehenden JSON-Dokument. JSON ist ein beliebtes Datenformat, weil es sowohl für Menschen als auch für Maschinen einfach zu lesen und zu schreiben ist, es ist leichtgewichtig und es ist bekannt und wird breit unterstützt.
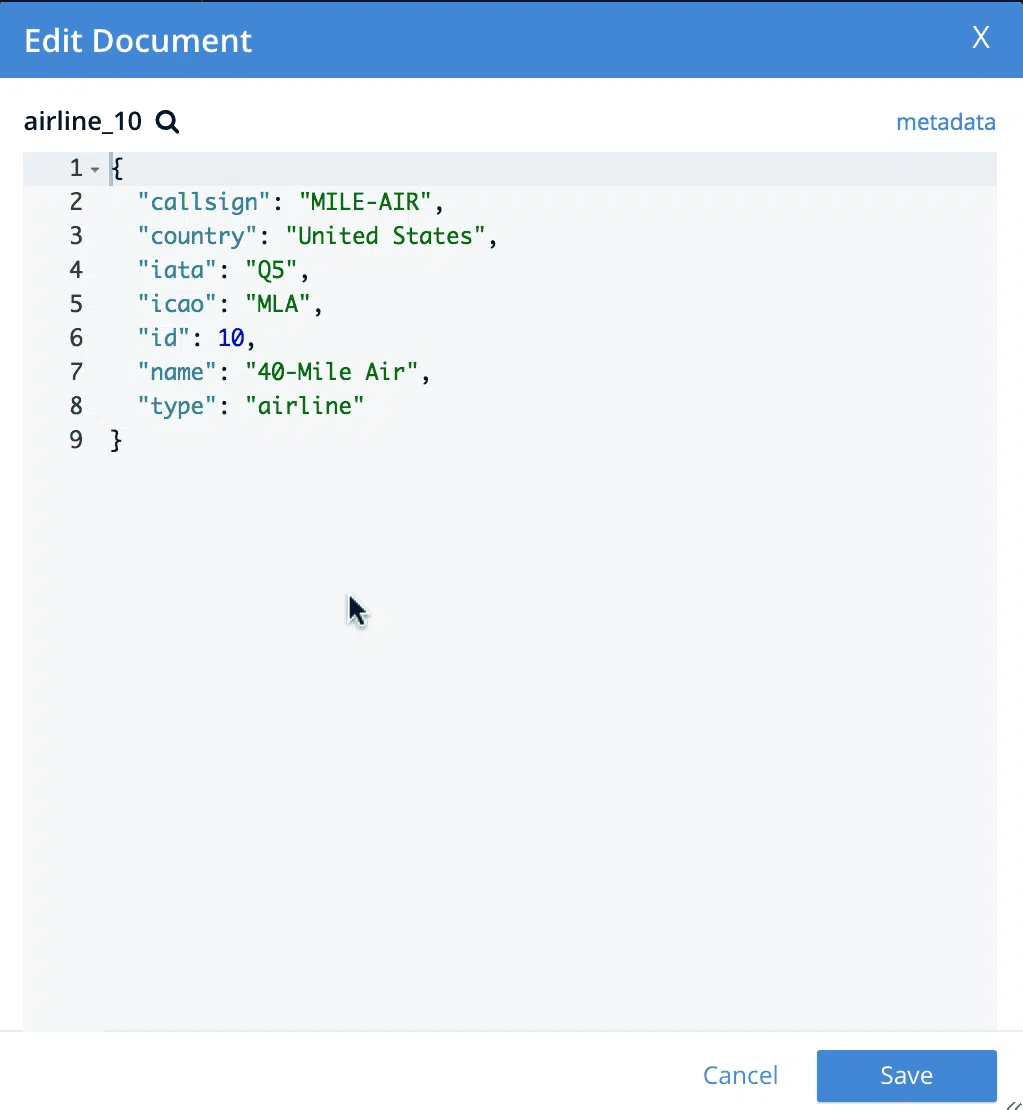
In einer Schlüssel-Wert-Datenbank ist jedes Dokument in seiner Gesamtheit ein Wert und hat einen Schlüssel. Dieses Speichersystem macht eine Datenbank zu einer Schlüssel-Wert-Datenbank. In diesem Beispiel ist airline_10 der Schlüssel, und JSON ist der Wert. Die Daten in einem Dokument können die Form von Schlüssel-Wert-Paaren haben (wie in diesem Beispiel), müssen es aber nicht. Bei den Daten kann es sich beispielsweise um XML, Binärdaten oder viele andere Formen von strukturierten, halbstrukturierten oder unstrukturierten Daten handeln.
Merkmale von Schlüssel-Wert-Datenbanken
Zwar ist jede Key-Value-Datenbank einzigartig, doch haben sie zahlreiche Merkmale gemeinsam, die sie für viele moderne Anwendungsfälle zu einer überzeugenden Wahl machen. Einige der wichtigsten Merkmale sind:
Schema-freier Entwurf - Das Fehlen eines festen Schemas ermöglicht eine flexible Datendarstellung. Key-Value-Datenbanken bieten Platz für unterschiedliche Datenstrukturen innerhalb einer Datenbank, so dass Sie Ihre Datenstrukturen im Laufe der Zeit problemlos weiterentwickeln können.
Einfaches Datenmodell - Ein einfaches Datenmodell macht Key-Value-Datenbanken benutzerfreundlich für grundlegende Anforderungen. Auch die Datenzugriffsmethoden sind recht einfach (z. B. get, replace, remove).
Unterstützung für komplexe Datentypen - Sie können komplizierte und verschachtelte Datenstrukturen als Werte speichern. Mit dieser Funktion können Sie verschiedene Datentypen innerhalb eines einzigen Schlüssel-Wert-Paares für eine umfassende Datenmodellierung darstellen.
Unterstützung von Sekundärschlüsseln - Sekundärschlüssel ermöglichen Ihnen den Zugriff auf Werte mit mehr als einem Schlüssel. Diese Funktion erhöht die Flexibilität beim Datenabruf, indem sie die Abfragemöglichkeiten Ihrer Anwendung erweitert und vielfältigere Zugriffsmuster ermöglicht.
Partitionierung und Sharding - Die Unterstützung von Datenpartitionierung und Sharding kann die parallele Verarbeitung, den Lastausgleich und die Skalierbarkeit verbessern. Die fortschrittlichsten Key-Value-Datenbanken unterstützen die automatische Verteilung Ihrer Datenbank über mehrere Rechenzentren. Couchbase's verteilte Datenbankzum Beispiel bietet diese Unterstützung durch automatische Aufteilung.
Replikation - Die Replikation von Daten über mehrere Knoten gewährleistet Redundanz, hohe Verfügbarkeit und Fehlertoleranz, um das Risiko von Datenverlusten oder Serviceunterbrechungen zu verringern.
ACID-Unterstützung - ACID (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) für Transaktionen ist ein Grundpfeiler relationaler Datenbanken, der Datenintegrität und Zuverlässigkeit auch bei Systemausfällen oder Fehlern gewährleistet. Historisch gesehen hat sich ACID in NoSQL-Datenbanken nur langsam durchgesetzt, weil es den Vorteil der höheren Geschwindigkeit konterkariert, aber es wird immer häufiger eingesetzt. Couchbase, zum Beispiel, unterstützt verteilte ACID-Transaktionen mit mehreren Dokumenten ohne Abstriche bei der Flexibilität oder Hochverfügbarkeit.
Anwendungsfälle für Key-Value-Datenbanken
Die Vielseitigkeit von Key-Value-Datenbanken macht sie zu einer idealen Option, um eine Vielzahl moderner Anwendungsanforderungen mit Einfachheit, Geschwindigkeit und Skalierbarkeit zu erfüllen. Key-Value-Datenbanken werden oft gewählt für:
Caching
Key-Value-Datenbanken eignen sich hervorragend für Caching-Szenarien, in denen der schnelle Zugriff auf häufig verwendete Daten für die Leistungsoptimierung entscheidend ist.
Benutzerprofile
Key-Value-Datenbanken sind gut geeignet, um eine schnelle und skalierbare Lösung für die Speicherung und Verwaltung von benutzerbezogenen Informationen wie Benutzernamen, E-Mail und Benutzereinstellungen zu bieten.
Speicherung von Sitzungen
Key-Value-Datenbanken eignen sich gut für die Verwaltung von Sitzungsdaten, da sie einen schnellen Zugriff und Aktualisierungen für Anmeldungen, Authentifizierungen und Interaktionen gewährleisten.
Echtzeit-Analytik
Dank des schnellen Datenzugriffs eignen sich Key-Value-Datenbanken für Analyseszenarien, bei denen ein schneller Datenabruf erforderlich ist. Beispiele hierfür sind dynamische Preisgestaltung, personalisierte Marketingangebote und Kreditbewertungen in Echtzeit.
Produktkataloge
Key-Value-Datenbanken bieten eine einfache und effiziente Möglichkeit zur Verwaltung von Produktkatalogen, insbesondere in Szenarien, in denen Produkte eine Vielzahl unterschiedlicher Attribute aufweisen. Die Darstellung von Produktdetails über Schlüssel-Wert-Paare ermöglicht flexible Aktualisierungen und einen schnellen Abruf für E-Commerce-Anwendungen.
Vor- und Nachteile von Key-Value-Datenbanken
Traditionelle relationale Datenbanken sind die am weitesten verbreiteten Datenbanken und verwenden die beliebteste Abfragesprache, SQL. Die folgenden Vor- und Nachteile von Key-Value-Datenbanken werden daher in Vergleich mit relationalen Datenbanken und SQL.
Vorteile
Vereinfachung - Key-Value-Datenbanken haben ein einfaches Datenmodell, das die Komplexität des Datenbankdesigns und der Abfrageoperationen reduziert. Diese Einfachheit verbessert die Benutzerfreundlichkeit und die Entwicklung.
Hohe Leistung - Key-Value-Datenbanken sind für schnelle Lese- und Schreibvorgänge optimiert, was einen schnellen Zugriff auf gespeicherte Daten ermöglicht. Diese Optimierung ist ein Schlüsselfaktor bei der Bereitstellung einer hohen Gesamtleistung für Anwendungen mit hohen Geschwindigkeitsanforderungen.
Skalierbarkeit - Key-Value-Datenbanken bieten horizontale Skalierbarkeit indem sie das Hinzufügen von Knoten zur Bewältigung des wachsenden Datenvolumens und -verkehrs ermöglichen. Diese horizontale Skalierbarkeit macht es einfacher und erschwinglicher für ein System zu wachsen, um den sich ändernden Anforderungen gerecht zu werden. Couchbase verwendet automatisches, schlüsselbasiertes Sharding, um die Daten gleichmäßig in einem Cluster zu verteilen, so dass sich die Entwickler nicht um die Konfiguration von Shard Keys, Partitionierung oder Hot Spots kümmern müssen.
Flexibilität - Ein schemaloses Design unterstützt verschiedene Datenstrukturen in einer einzigen Datenbank und ermöglicht die problemlose Anpassung an sich entwickelnde Datenstrukturen. Diese Fähigkeiten sind besonders vorteilhaft, wenn sich Datenmodelle im Laufe der Zeit ändern müssen.
Effiziente Zwischenspeicherung - Schlüsselwert-Datenbanken sind sehr effizient bei Caching weil ihre einfache Struktur einen schnellen und direkten Zugriff auf Daten ohne komplexe relationale Strukturen ermöglicht. Die Gesamtleistung des Systems wird dadurch verbessert, dass die gleichen Daten nicht wiederholt von langsameren Speichersystemen abgerufen werden müssen.
Benachteiligungen
Begrenzte Abfragemöglichkeiten - Key-Value-Datenbanken verfügen im Vergleich zu relationalen Datenbanken über keine erweiterten Abfragefunktionen und eignen sich daher weniger für komplexe Abfrage- und Analyseszenarien, die mehrere Joins und Beziehungen beinhalten. Couchbase löst dieses Problem durch die Verwendung von SQL++ zur Unterstützung anspruchsvoller Syntaxen wie JOINs und Unterabfragen und bietet außerdem innovativen Zugriff auf JSON-Funktionen wie verschachtelte Objekte und Arrays.
Herausforderungen für die Datenintegrität - Die Gewährleistung der Datenintegrität kann in Key-Value-Datenbanken eine Herausforderung darstellen, insbesondere in verteilten Umgebungen. Viele setzen nicht dasselbe Maß an Konsistenz und referenzieller Integrität durch wie herkömmliche relationale Datenbanken. Ein anderer Ansatz für die Datenmodellierung, wie z. B. die JSON-Datenmodellierung, kann die Herausforderungen abmildern. Siehe auch unsere Diskussion über die ACID-Unterstützung im obigen Abschnitt über die Funktionen.
Lernkurve für NoSQL-Paradigma - Die Umstellung auf NoSQL kann für Entwickler, die an SQL und relationale Datenbankmodelle gewöhnt sind, eine einschüchternde Lernkurve darstellen. Couchbase verwendet SQL++ so dass Entwickler ihre vorhandenen SQL-Kenntnisse nutzen können, um moderne Anwendungen mit allen Vorteilen von JSON zu erstellen.
Beispiele für Key-Value-Datenbanken
- Redis ist eine quelloffene In-Memory-Schlüsselwert-Datenbank, die für ihre Geschwindigkeit und Vielseitigkeit bekannt ist. Sie unterstützt verschiedene Datenstrukturen wie Strings, Hashes, Listen und Sets. Als vollständige In-Memory-Datenbank wird Redis oft als Cache neben einer anderen Datenbank verwendet.
- Amazon DynamoDB ist ein vollständig verwalteter Datenbankdienst für Schlüsselwerte und Dokumente, der von Amazon Web Services (AWS) bereitgestellt wird. Er wird häufig für Anwendungen mit dynamischen Arbeitslasten verwendet und ist in das AWS-Ökosystem integriert, wodurch er für Cloud-basierte Anwendungen geeignet ist.
- Couchbase bietet eine flexible JSON-Dokumentenstruktur, die das Speichern und Abrufen komplexer Daten erleichtert. Es ist bekannt für seine einfache Skalierbarkeit und effiziente Datenverteilung. Zu den einzigartigen Merkmalen gehören die SQL++-Abfragesprache und die Fähigkeit, als Dokumentendatenbank, Key-Value-Speicher und Cache zu fungieren.
Couchbase und Schlüsselwertspeicher
Couchbase ist eine NoSQL-Datenbank, die sowohl als Key-Value-Store als auch als dokumentenorientierte Datenbank arbeitet. Die SQL-basierte Abfragesprache SQL++ macht es Entwicklern leicht, von traditionellen Datenbanken auf die Flexibilität von JSON umzusteigen und die modernen Anwendungen ihres Unternehmens zu nutzen.
Für die Datenspeicherung organisiert Couchbase die Daten als Key-Value-Paare, und das dokumentenorientierte Modell von Couchbase erlaubt es, dass die Werte komplexe JSON-Dokumente sind. Dokumente im JSON-Format können in sekundären Indizes indiziert werden, die auf jeden Schlüsselwert oder Dokumentschlüssel verweisen. Diese Flexibilität ermöglicht es, strukturierte, halbstrukturierte und unstrukturierte Daten zu speichern.
Couchbase ist optimiert für hohe Lese- und Schreibleistungund eignet sich daher für Szenarien, in denen ein schneller Datenzugriff entscheidend ist. Sie unterstützt horizontale Skalierbarkeit und bewältigt effizient die Zunahme des Datenvolumens und des Datenverkehrs, indem sie die Daten auf mehrere Knoten verteilt.
Diese Blog-Beitrag führt Sie durch einen Beispieldatensatz, um Ihnen zu zeigen, wie der Couchbase Key-Value Store funktioniert.
Schlussfolgerung
Key-Value-Datenbanken sind eine moderne Alternative zu herkömmlichen relationalen Datenbanken, die für viele Anwendungsfälle eine bessere Leistung, Skalierbarkeit und Flexibilität bieten. Ihr schemafreies Design ermöglicht vielfältige Datenstrukturen und eine einfache Entwicklung dieser Strukturen im Laufe der Zeit. Ein einfaches Datenmodell macht sie benutzerfreundlich, während erweiterte Funktionen sie für anspruchsvolle Unternehmensanforderungen geeignet machen.
Obwohl Key-Value-Datenbanken im Vergleich zu relationalen Datenbanken einige Nachteile haben, werden die fortschrittlichsten Lösungen immer ausgereifter und bieten zusätzliche Funktionen, um frühere Einschränkungen zu beseitigen. Couchbase ist ein Beispiel für eine führende verteilte NoSQL-Cloud-Datenbank und einen Key-Value-Store, der Vielseitigkeit, Leistung, Skalierbarkeit und Wert für Cloud-, mobile, KI- und Edge-Anwendungen bietet.
Wenn Sie mehr über Key-Value-Datenbanken und verwandte Technologien erfahren möchten, lesen Sie diese resources:
Arten von Datenbanken
6 Arten von Datenmodellen
Was ist Couchbase?
Wie Couchbase Daten speichert
Den Couchbase Data Service verstehen
Schlüssel-Wert-Operationen in Couchbase
Schlüssel-Wert-Operationen mit Python
Schlüssel-Wert-Operationen mit PHP
CRUD Schlüssel-Wert-Operationen in Couchbase
Erfahren Sie mehr über den Couchbase Key-Value-Store

