
Agenten Gedächtnis geben
Kurz- und Langzeitgedächtnis über Sitzungen, Neustarts, Benutzer und Frameworks hinweg beibehalten.
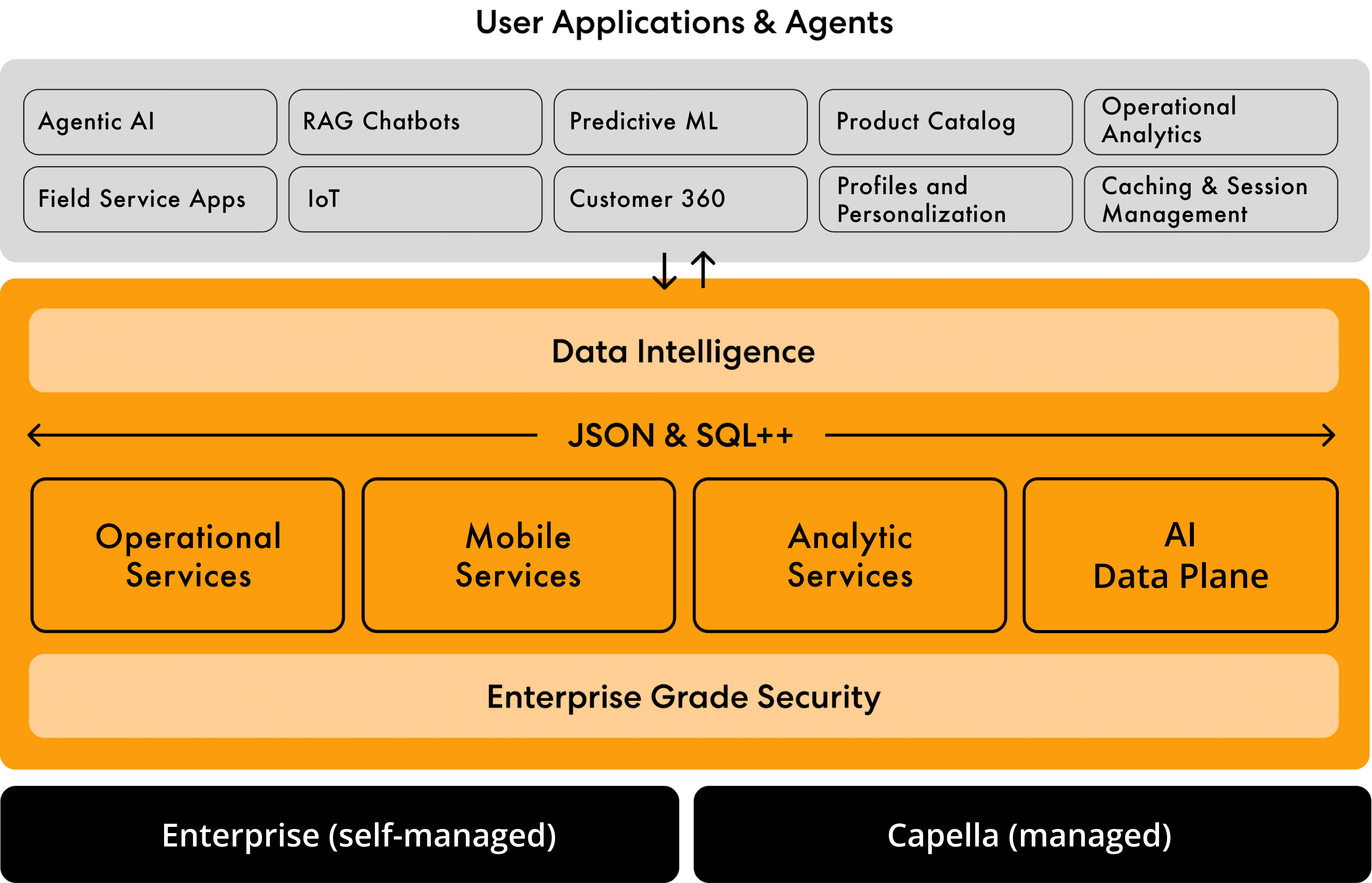
Die Couchbase AI Data Plane gibt Produktions-KI-Agenten persistenten Speicher, gesteuerten Datenzugriff, Einblick in Tools und Prompts sowie schnelle Kontextabfrage über Cloud-, selbstverwaltete, hybride, Edge- und Air-Gapped-Umgebungen. Sie vereint Agent Memory, MCP Server und Agent Catalog auf Couchbase.
Kurz- und Langzeitgedächtnis über Sitzungen, Neustarts, Benutzer und Frameworks hinweg beibehalten.

Halten Sie Prompts, Tools, Spuren und Speicher in einer einzigen gesteuerten Schicht, die Teams mit SQL++ inspizieren.

Gewähren Sie Agenten standardisierten Zugriff auf operative Daten, Vektoren, Dokumente und Werkzeuge.

Reduzieren Sie Token-Kosten um Größenordnungen mit persistentem, kumulativem Agenten-Gedächtnis.
Effiziente Bereitstellung von KI-Agenten von der Pilotphase bis zur Produktion mit persistentem Agenten-Speicher, Apache Iceberg Lakehouse-Föderation und Rust-Unterstützung. Und für Mobilgeräte: Bluetooth Peer-to-Peer-Synchronisierung und React Native-Unterstützung.

Persistente kurz-/langfristige Erinnerung über Sitzungen hinweg, getestet auf LangGraph, CrewAI & LlamaIndex.

Iceberg Lakehouse-Tabellen direkt aus Enterprise Analytics 2.2 abfragen, ohne ETL oder Datenverdopplung.

Couchbase Lite 4.1 synchronisiert Daten über Bluetooth in vollständig getrennten Edge-Umgebungen ohne Netzwerk.

Couchbase Lite React Native SDK 1.1 für leistungsstarke plattformübergreifende Apps.

Asynchroner nativer Zugriff auf Schlüssel-Wert, Abfragen, Volltextsuche und Vektorindizierung.

Führe föderierte SQL-Abfragen gegen deine Couchbase-Datenbank mit Trinos verteilter Abfrage-Engine aus. (Kommt bald)
Fortschritte bei den wichtigsten Funktionen der Couchbase Operational Data Platform.
Wählen Sie AWS Bedrock oder OpenAI, gemäß den Richtlinien des übergeordneten Anbieters.
Jetzt eine unternehmensgestützte Komponente für auffindbare, verwaltete Agenten-Tools.
Rolling Upgrades, schnellerer Abgleich großer Datensätze und Isolierung von Systemmetadaten.
Client-seitige Zugriffskontrolle, CORS, Anmeldeinformationsrotation und Windows/ARM-Unterstützung.
Cross-Data-Center-Replikation über private Konnektivität, außerhalb des öffentlichen Internets.
Unternehmensgestützter, selbstverwalteter MCP-Server für die standardisierte Integration von Model Context Protocol.

Produktionsagenten benötigen Speicher, Werkzeuge, Prompts, operative Daten, Traces und Kontext, aber diese Assets befinden sich oft in verstreuten Systemen. Couchbase bewahrt sie in einer zentralen, gesteuerten Datenschicht auf und gibt Teams Einblick, was ein Agent verwendet hat, welche Prompt-Version beteiligt war und welche Daten die Antwort beeinflusst haben.
Halten Sie Prompts, Tools, Spuren, Speicher und Betriebsdaten zusammen und fragen Sie sie mit SQL++ ab, um genau zu sehen, was ein Agent verwendet hat und warum er geantwortet hat.
Der Couchbase MCP Server ermöglicht Agenten standardisierten Zugriff auf operative Daten, Dokumente und Caches ohne eine separate Integrationsschicht.
Agent Catalog macht Prompts, Tools und End-to-End-Traces auffindbar, damit Teams das Verhalten von Agenten über Anwendungen hinweg überprüfen, wiederverwenden und steuern können.
Agent Memory funktioniert über LangGraph, CrewAI und LlamaIndex hinweg, sodass Teams Frameworks wechseln oder kombinieren können, ohne die Speicherinfrastruktur neu aufbauen zu müssen.


“Als wir zu agentenbasierter Arbeit übergingen, war dies eine natürliche Weiterentwicklung unserer Partnerschaft.”

“Was Couchbase mit SQL++ gemacht hat, ist eines der innovativsten Dinge, die seit Jahrzehnten im Datenbankbereich gemacht wurden.”

“Couchbase ist ein hochskalierbarer, verteilter Datenspeicher, der eine entscheidende Rolle in den Systemen von LinkedIn spielt.”
In diesem Webcast und dieser Demo zeigen wir Ihnen, wie Sie sicherstellen, dass Ihr KI-Agent nicht zu dem Friedhof der Piloten gehört, die nie ausgeliefert werden.
Sie lernen, wie:
Erfahren Sie, warum unternehmensweite KI-Initiativen aufgrund grundlegender Datenprobleme routinemäßig in der Pilotphase ins Stocken geraten.
Probieren Sie Agent Memory aus und sehen Sie, wie KI-Agenten über Sitzungen, Benutzer und Frameworks hinweg Kontext beibehalten können, während benutzerdefinierte Speicher-, Abruf- und Zugriffskontrolllogik reduziert wird.

Erkunden Sie Dokumentationen, Tutorials und Beispiele für die Erstellung von Produktions-KI-Agenten mit Couchbase.
Machen Sie sich mit Couchbase vertraut und beginnen Sie mit wenigen Klicks mit der Erstellung von agentenfreundlichen Anwendungen.
Sprechen Sie mit Couchbase über die Verlagerung von KI-Agenten von der Pilotphase in die Produktion.