
Pesquisa de IA escalável
Índice vetorial em hiperescala para dados em escala de bilhões e é ideal para aplicativos RAG, agentes e recomendações.
Couchbase 8.0 unifies on-premises and cloud data management with massive vector scalability, built-in AI query intelligence, and new enterprise-grade operational controls. It’s the only data platform supporting transactional, analytical, and AI workloads together optimized for both developers and DevOps.
Índice vetorial em hiperescala para dados em escala de bilhões e é ideal para aplicativos RAG, agentes e recomendações.

Índice vetorial composto para aplicativos de pesquisa em que é necessária a pré-filtragem de dados maciços.

O índice de vetor de pesquisa combina vários métodos - lexical (palavra-chave) com semântico (vetor) para recuperação rica em contexto.

Opere no local, no DBaaS, no Kubernetes e incorporado em aplicativos móveis.
O Couchbase 8.0 apresenta grandes avanços para o desenvolvimento e o gerenciamento de IA e outros aplicativos essenciais em escala. Desde a indexação vetorial em escala de bilhões até a nova lógica de failover e a criptografia em repouso, todos os serviços estão mais rápidos, mais inteligentes e mais fáceis de gerenciar.

Vetores em escala de bilhões para precisão, velocidades e latência excepcionais. Outros tipos para corresponder ao seu caso de uso.

8.0 oferece criptografia em repouso pronta para uso.

O 8.0 facilita a consulta de dados com novos recursos de linguagem natural para o SQL++.

Resolução aprimorada de conflitos de replicação e integração de sincronização móvel.

Recursos aprimorados de failover, insights de consulta e visibilidade de métricas do SDK.
O Couchbase 8.0 permite que os desenvolvedores passem do conceito à IA de produção mais rápido do que nunca. Eles podem criar aplicativos rápidos com tecnologia de IA com enormes conjuntos de dados com baixo TCO, começar rapidamente com consultas em linguagem natural e garantir consultas rápidas com novas ferramentas de solução de problemas.
Use a linguagem natural para fazer consultas com as extensões do SQL++.
Pesquise com sinônimos definidos pelo desenvolvedor para ter uma pesquisa mais inteligente.
Repositório integrado de cargas de trabalho e insights de desempenho.
Compatível com estruturas populares de IA.
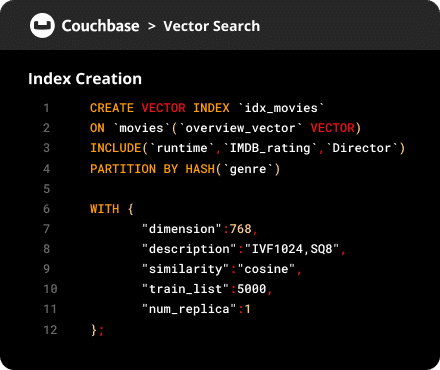
Aprimoramento da excelência operacional com gerenciamento de cluster mais inteligente, recursos avançados de segurança, reequilíbrio dinâmico e failover mais rápido para disponibilidade contínua do serviço.
A criptografia nativa pronta para uso em repouso torna os dados mais seguros e a vida mais simples.
Ajuste dinamicamente os serviços não-KV sem adicionar ou remover nós, eliminando atrasos no rebalanceamento.
Agregue informações da telemetria do seu cliente SDK para melhorar o monitoramento de ponta a ponta e agilizar a solução de problemas.
Failover automático de nós de dados que não respondem para melhorar o tempo de atividade do aplicativo. Atenda às solicitações enquanto os caches se aquecem.


“Os novos recursos de pesquisa vetorial do Couchbase 8.0 transformam a forma como fornecemos descoberta de vídeo com reconhecimento de contexto para empresas.”

“O que a Couchbase fez com o SQL++ foi uma das coisas mais inovadoras feitas no espaço do banco de dados em décadas.”

“O Couchbase é um armazenamento de dados distribuído e altamente escalável que desempenha um papel fundamental nos sistemas do LinkedIn.”
Obtenha respostas rápidas para os tópicos mais comuns relacionados à nossa versão mais recente do servidor.
It supports billions of vectors with millisecond retrieval speeds using a DiskANN-based design.
A criptografia em repouso, o gerenciamento de chaves KMIP e o monitoramento de eventos garantem a integridade e a conformidade dos dados.
Sim. Use o índice do vetor de pesquisa para consultas híbridas de vetor + léxico.
Automatic failover, rebalancing, and faster startup ensure continuous operations.
Ao revisar a versão 8.0 do Couchbase blog de anúncios.
O Hyperscale ajuda nos casos de uso no estilo RAG quando não é possível prever o que um prompt perguntará a um LLM, enquanto os índices de vetor composto usam parâmetros de pré-filtragem para restringir os vetores a serem incluídos em um prompt. Ambos oferecem resposta em milissegundos para que os fluxos de trabalho do RAG não fiquem lentos.
Obtenha alto desempenho e precisão em vetores de escala de bilhões para agentes de IA, fluxos de trabalho RAG, memória contextual e sistemas de recomendação - no local ou em Capella.

Confira nosso portal do desenvolvedor para explorar o NoSQL, procurar recursos e começar a usar os tutoriais.
Comece a trabalhar com o Couchbase em apenas alguns cliques. O Capella DBaaS é a maneira mais fácil e rápida de começar.
Deseja saber mais sobre as ofertas do Couchbase? Deixe-nos ajudar.