




Confiar na IA

Acelerar a inferência
Automatizar o RAG

Controle de custos



IA e agentes confiáveis
Para atender às preocupações com a segurança dos dados e a precisão da IA, o Couchbase permite que os clientes co-localizem com segurança os dados e os modelos de IA em seu ambiente. Os guardrails integrados e os controles avançados protegem os aplicativos, enquanto nosso catálogo de agentes monitora e expõe o comportamento do agente próximo aos limites críticos.

Velocidade em escala
Os agentes e os aplicativos de IA exigem acesso rápido a diversos dados para otimizar as experiências do usuário. A arquitetura do Couchbase oferece respostas em milissegundos em vários tipos de dados e casos de uso, eliminando as ineficiências de bancos de dados em silos. Para aumentar ainda mais a velocidade, o cache semântico minimiza as chamadas LLM desnecessárias, reduzindo o tempo e os custos de inferência.
Pesquisa avançada de vetores
A pesquisa vetorial avançada do Couchbase oferece armazenamento e pesquisa em escala de bilhões com desempenho e precisão excepcionais. Ela permite um contexto avançado em textos, imagens e muito mais, garantindo escalabilidade, segurança e integração perfeita de ferramentas de IA para interações econômicas de LLM. Passe do protótipo à produção sem esforço, com capacidade em escala de bilhões e três opções de indexação adaptadas a qualquer caso de uso.

Automatização de pipelines RAG
As organizações geralmente ignoram os dados não estruturados que podem aprimorar os modelos de IA. O RAG melhora as respostas do modelo. O Couchbase automatiza a ingestão, a vetorização e a indexação de dados, simplificando os fluxos de trabalho e melhorando as respostas do modelo. Ele converte dados não estruturados (por exemplo, texto, PDFs, imagens) em JSON e vetores, re-vetoriza automaticamente com atualizações para dar mais contexto aos modelos.

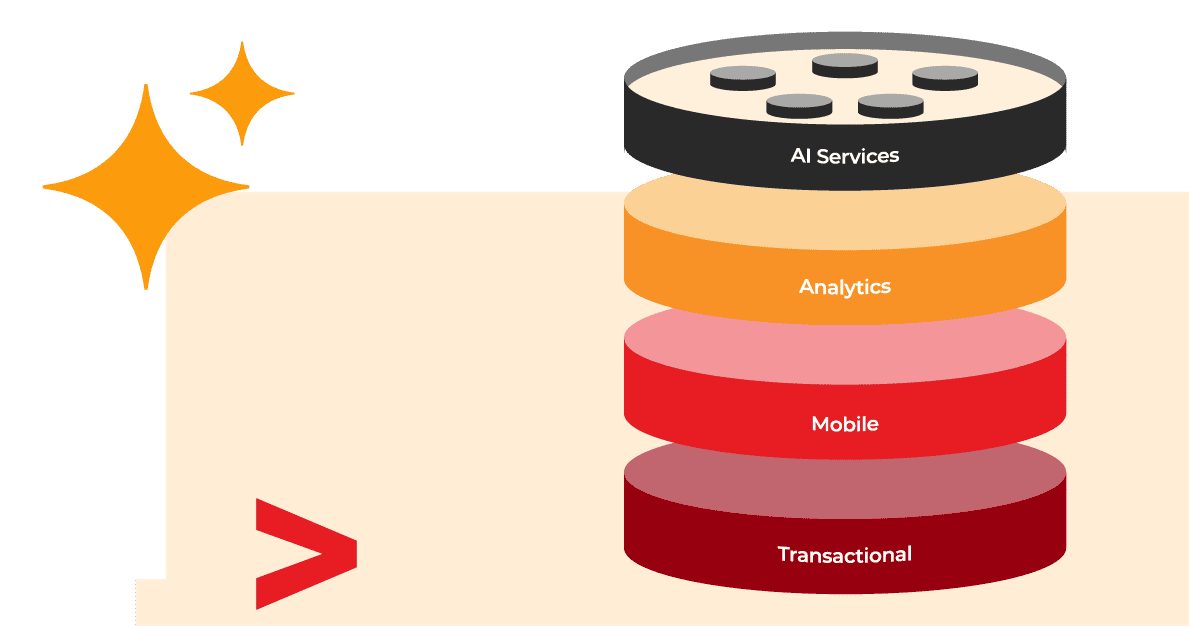
Plataforma de banco de dados de IA
O Capella é a base para seus aplicativos e agentes de IA essenciais. O Capella ajuda você:
- Armazenar e processar entradas e saídas de agentes para cada interação com o LLM.
- Crie barreiras de proteção e gerencie a memória contextual para ajudar os agentes a permanecerem na tarefa sem alucinações.
- Reduza seus custos de trocas de IA usando o cache de conteúdo da Capella, a recuperação de vetores de alto desempenho, o cache semântico e o ajuste de desempenho.
- Aproxime as interações de IA do usuário móvel para obter experiências excepcionais.
Com a Capella, não há compromissos de desempenho, escala, versatilidade, custos ou alcance global.
O que os clientes estão dizendo


"Os dados de comunicação em tempo real e a consulta de alta simultaneidade do Couchbase melhoram muito o desempenho e a estabilidade do aplicativo AI Assistant."


"O dimensionamento com o MySQL exigiria muito mais configuração e levaria à fragmentação dos dados. O Couchbase permite uma implementação muito mais rápida."


"A capacidade de executar consultas facilmente nos ajudou a impulsionar os algoritmos de IA de aprendizado de máquina que estamos executando hoje. O Couchbase era o banco de dados ideal para nós."


"Descobrimos que a tecnologia de replicação entre data centers para o Couchbase era superior, especialmente para grandes cargas de trabalho."
Integra-se perfeitamente ao ecossistema de IA de nossos parceiros
Implante e gerencie facilmente seus aplicativos agênticos com os principais parceiros de tecnologia de IA.











Iniciar a construção
Confira nosso portal do desenvolvedor para explorar o NoSQL, procurar recursos e começar a usar os tutoriais.
Use o Capella gratuitamente
Comece a trabalhar com o Couchbase em apenas alguns cliques. O Capella DBaaS é a maneira mais fácil e rápida de começar.
Entre em contato
Deseja saber mais sobre as ofertas do Couchbase? Deixe-nos ajudar.