
ZUSAMMENFASSUNG
Bei der Datenintegration werden Daten aus verschiedenen Quellen in einem Zielsystem kombiniert. Sie umfasst mehrere Schritte, darunter Datenextraktion, -umwandlung, -laden, -synchronisierung und -verwaltung, die jeweils sicherstellen, dass die Daten korrekt, konsistent und verwertbar sind. Zu den Arten der Datenintegration gehören Anwendungsintegration, Data Warehousing und Virtualisierung. Tools wie Amazon Aurora Zero-ETL mit Amazon Redshift und Daten-Streaming-Tools wie Apache Kafka werden verwendet, um den Integrationsprozess zu beschleunigen. Die Integration bietet zwar große Vorteile wie verbesserte Datenqualität, schnellere Einblicke und bessere Zusammenarbeit, bringt aber auch Herausforderungen wie Datensilos, Implementierungskosten und Governance-Probleme mit sich. Um den Nutzen für Ihr Unternehmen zu maximieren, müssen Sie sich vor Beginn des Datenintegrationsprozesses über mögliche Rückschläge im Klaren sein.
Was ist Datenintegration?
Datenintegration ist der Prozess der Kombination von Daten aus verschiedenen Quellen zu einer einheitlichen Ansicht. Dabei werden Daten aus mehreren Systemen (z. B. Datenbanken, Anwendungen oder Data Warehouses) extrahiert, in ein kompatibles Format umgewandelt und in ein zentrales System geladen. Die Datenintegration verbessert die Zugänglichkeit, Konsistenz und Zuverlässigkeit, was zu einer besseren Analyse, Berichterstattung und Entscheidungsfindung führt.
Lesen Sie diese Ressource weiter, um mehr über die Datenintegration, ihre Vorteile und Grenzen sowie die Tools zu erfahren, mit denen Sie sie erleichtern können.
- Wie funktioniert die Datenintegration?
- Arten der Datenintegration
- Beispiele für die Datenintegration
- Vorteile der Datenintegration
- Herausforderungen bei der Datenintegration
- Werkzeuge zur Datenintegration
- Eine vollständige Aufschlüsselung des Datenintegrationsprozesses
- Die wichtigsten Erkenntnisse
Wie funktioniert die Datenintegration?
Bei der Datenintegration werden Daten aus verschiedenen Quellen zu einer ganzheitlichen Ansicht kombiniert, um die Analyse, Berichterstattung und Entscheidungsfindung zu erleichtern. Sie beruht auf einem Prozess, der Datenextraktion, -umwandlung, -laden, -synchronisation und -verwaltung umfasst und den wir im Folgenden näher erläutern.
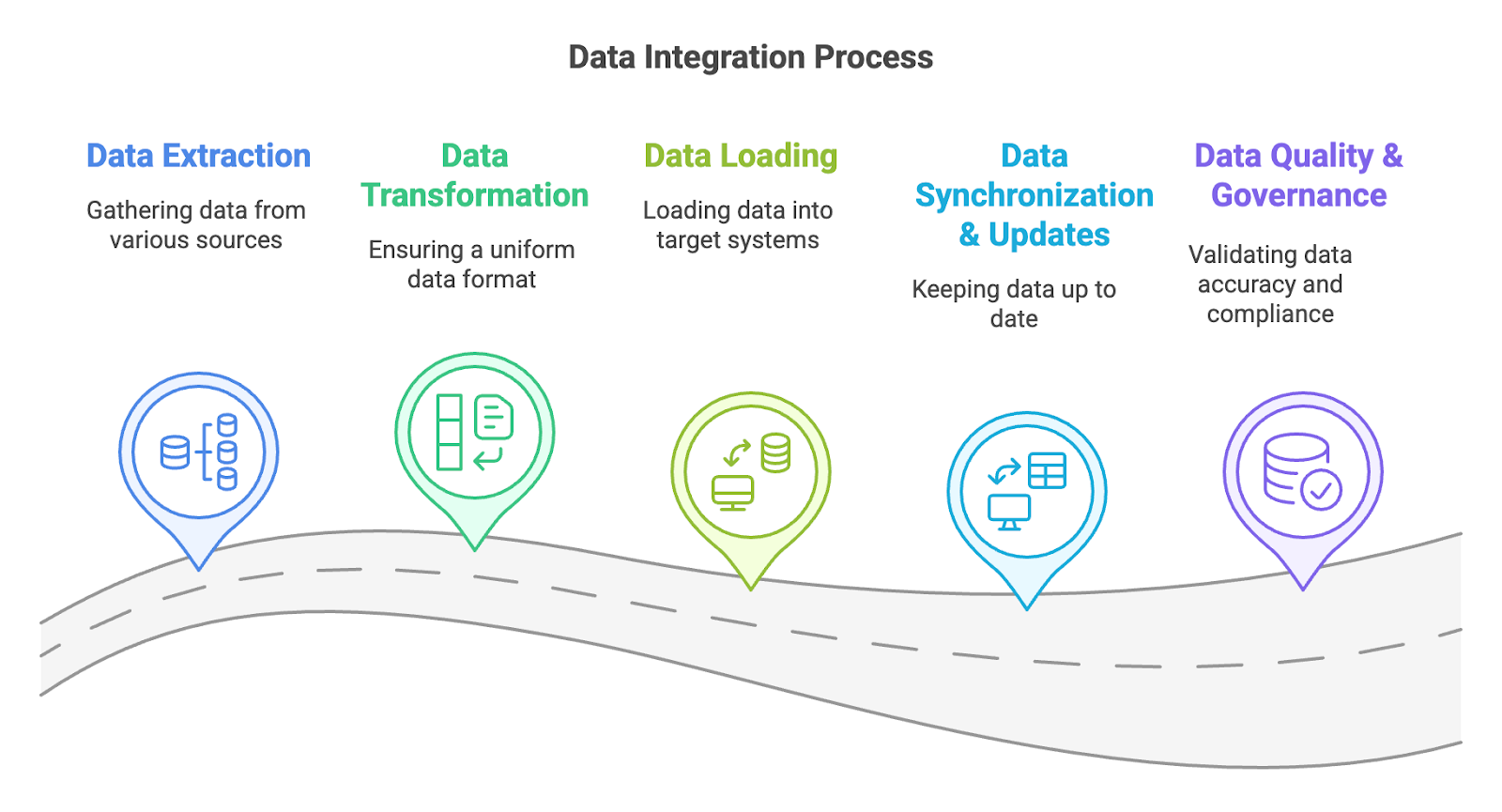
Datenextraktion
Die Phase der Datenextraktion umfasst das Abrufen von Daten aus Datenbanken, Cloud-DiensteAPIs, flache Dateien (wie CSV oder Excel) und ältere Plattformen. Dieser Schritt konzentriert sich auf die Erfassung der relevanten Daten, ohne die ursprünglichen Quellen zu verändern. Zunächst wird ermittelt, wo sich die Daten befinden, dann wird eine geeignete Extraktionsmethode ausgewählt - entweder die vollständige Extraktion, bei der alle Daten auf einmal abgerufen werden, oder die inkrementelle Extraktion, bei der nur neue oder aktualisierte Daten seit der letzten Integration abgerufen werden. Die Wahrung der Datenintegrität während dieses Prozesses ist entscheidend, um Genauigkeit und Konsistenz zu gewährleisten. Häufig werden automatisierte Tools oder benutzerdefinierte Skripte verwendet, um eine Verbindung zu den Quellen herzustellen und die erforderlichen Daten zu extrahieren, wodurch die Grundlage für die anschließenden Transformations- und Ladephasen geschaffen wird.
Umwandlung von Daten
In der Datenumwandlungsphase werden die extrahierten Daten in ein einheitliches, für das Zentralsystem nutzbares Format umgewandelt. Dazu gehört die Bereinigung der Daten durch das Entfernen von Duplikaten, die Korrektur von Fehlern, die Behandlung fehlender Werte und die Standardisierung von Formaten wie Datum und Uhrzeit, Währung oder Maßeinheiten. Sie kann auch eine Datenanreicherung beinhalten, bei der zusätzlicher Kontext oder abgeleitete Werte hinzugefügt werden, sowie ein Datenmapping, bei dem Felder aus verschiedenen Quellen an ein einheitliches Schema angepasst werden. In dieser Phase wird sichergestellt, dass die integrierten Daten genau und kompatibel sind, so dass sie für Analysen, Berichte oder die weitere Verarbeitung im zentralen System bereit sind.
Laden von Daten
In der Datenladephase werden die transformierten Daten in ein zentrales System übertragen, z. B. in ein DatenlagerData Lake, oder Analytikplattform. Durch diesen Schritt wird sichergestellt, dass die bereinigten und standardisierten Daten an einem zentralen Ort gespeichert werden, damit sie für Berichte, Analysen oder andere Vorgänge abgerufen und verwendet werden können. Je nach System und Anforderungen können die Daten in geplanten Intervallen stapelweise oder kontinuierlich in Echtzeit (Streaming) geladen werden. Der Prozess umfasst auch die Validierung der geladenen Daten, um sicherzustellen, dass sie korrekt übertragen wurden. Durch effizientes und zuverlässiges Laden der Daten wird sichergestellt, dass der endgültige integrierte Datensatz genau, aktuell und einsatzbereit ist.
Datensynchronisierung und -aktualisierung
Die Phase der Datensynchronisierung und -aktualisierung stellt sicher, dass das zentrale System mit den in den Quellsystemen vorgenommenen Änderungen konsistent bleibt. Dabei wird regelmäßig geprüft, ob neue, geänderte oder gelöschte Daten vorliegen, und die integrierten Daten werden entsprechend aktualisiert, um die Konsistenz in allen Systemen zu gewährleisten. Die Synchronisierung kann in Echtzeit oder in geplanten Intervallen erfolgen, je nach den geschäftlichen Anforderungen und den technischen Gegebenheiten. Sie kann Mechanismen zur Konfliktlösung, Versionskontrolle und Prüfpfade umfassen, um Änderungen zu verfolgen und die Datengenauigkeit sicherzustellen. Diese Phase ist für die Aufrechterhaltung der Zuverlässigkeit integrierter Daten unerlässlich, insbesondere in dynamischen Umgebungen, in denen sich Daten häufig ändern.
Datenqualität und -verwaltung
In der Phase der Datenqualität und -verwaltung wird sichergestellt, dass die integrierten Daten korrekt sind und mit den Unternehmensrichtlinien und externen Vorschriften übereinstimmen. Sie umfasst die Implementierung von Regeln und Prüfungen zur Validierung der Datenintegrität, zur Erkennung und Korrektur von Fehlern und zur Beibehaltung standardisierter Formate für alle Datensätze. Zur Data Governance gehört auch die Definition von Rollen, Zuständigkeiten und Verfahren für die Verwaltung des Datenzugriffs, der Sicherheit und der Nutzung. Diese Phase kann die Pflege von Metadaten, die Dokumentation der Datenabfolge und die Einhaltung von Datenschutzgesetzen wie GDPR oder HIPAA umfassen. Letztendlich wird dadurch sichergestellt, dass die integrierten Daten vertrauenswürdig bleiben und mit den Geschäftszielen und rechtlichen Anforderungen übereinstimmen.
Arten der Datenintegration
Es gibt verschiedene Arten der Datenintegration, die jeweils für bestimmte Geschäftsanforderungen und technische Umgebungen konzipiert sind. Diese Integrationsarten dienen unterschiedlichen Zwecken, und oft verwenden Unternehmen eine Kombination aus ihnen, um komplexe Datenanforderungen zu erfüllen.
Manuelle Datenintegration
Die einfachste Form der Datenintegration besteht darin, dass die Benutzer Daten manuell sammeln und zusammenführen. Dieser Prozess ist zwar einfach, aber zeitaufwändig und anfällig für menschliche Fehler, weshalb er sich nur für kleine oder einmalige Projekte eignet.
Middleware-Datenintegration
Middleware fungiert als Brücke zwischen Systemen und ermöglicht ihnen die Kommunikation und den Austausch von Daten in Echtzeit. Sie wird häufig in Unternehmensumgebungen eingesetzt, in denen verschiedene Anwendungen nahtlos zusammenarbeiten müssen.
Integration von Anwendungen
Bei dieser Methode werden Softwareanwendungen mit integrierten Konnektoren oder APIs zur Übertragung und Synchronisierung von Daten mit anderen Systemen. Sie ist flexibel und wird häufig zur Integration von Cloud-basierten Plattformen oder SaaS-Lösungen verwendet.
Einheitliche Integration des Datenzugriffs
Dieser Ansatz bietet eine einheitliche Sicht auf die Daten, ohne sie physisch zu bewegen. Stattdessen werden Daten in Echtzeit über mehrere Systeme hinweg abgerufen und abgefragt, was für Unternehmen nützlich ist, die schnelle Einblicke ohne Datenduplikation benötigen.
Gemeinsame Speicherintegration (Data Warehousing)
Bei der gemeinsamen Speicherintegration werden Daten aus verschiedenen Quellen extrahiert, umgewandelt und in ein zentrales Repository, häufig ein Data Warehouse, geladen. Dieser Prozess ist ideal für Business Intelligence, historische Analysen und Berichte.
Virtualisierung von Daten
Die Datenvirtualisierung schafft eine abstrakte Ebene, die es den Nutzern ermöglicht, auf Daten aus verschiedenen Quellen so zuzugreifen und sie zu analysieren, als befänden sie sich an einem einzigen Ort. Sie minimiert die physische Bewegung von Daten und verbessert die Agilität und Geschwindigkeit beim Zugriff auf Erkenntnisse in Echtzeit.
Beispiele für die Datenintegration
Die Datenintegration wird branchenübergreifend eingesetzt, um Abläufe zu verbessern, Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen. Hier einige Beispiele für die Verbesserung der Kundenbindung, des E-Commerce, des Gesundheitswesens, der Finanzdienstleistungen und des Lieferkettenmanagements.
Kunde 360
Ein Unternehmen integriert Daten aus seinen CRM-, Website-Analyse-, Social-Media-Plattformen und E-Mail-Marketing-Tools, um eine einheitliches Kundenprofil. Die Integration ermöglicht personalisierte Marketingkampagnen und eine bessere Kundenbindung auf der Grundlage von Echtzeitverhalten und -präferenzen.
Verwaltung der Aufträge
Ein Online-Händler integriert Daten von seiner Website, seiner Bestandsdatenbank, seinem Versanddienstleister und seinem Zahlungsgateway, um Auftragsabwicklung rationalisieren. Die Integration gewährleistet eine genaue Bestandsverfolgung, einen schnelleren Versand und einen besseren Kundenservice.
Patientenakten
Ein Krankenhaus integriert Patientendaten aus verschiedenen Abteilungen, wie Laborergebnisse, Bildgebungssysteme und elektronische Gesundheitsakten (EHR), in ein zentrales System. Auf diese Weise erhalten Ärzte einen vollständigen Überblick über die Krankengeschichte eines Patienten, was die Diagnose- und Behandlungsentscheidungen verbessert.
Finanzielle Berichterstattung
Eine Finanzabteilung kombiniert Daten aus verschiedenen Buchhaltungsplattformen, Tools zur Kostenverfolgung und Lohnabrechnungssystemen in einem zentralen Data Warehouse. Die Integration dieser Daten ermöglicht konsistente Finanzberichterstattung, Überprüfung der Einhaltung der Vorschriften und genauere Prognosen.
Management der Lieferkette (SCM)
Ein Fertigungsunternehmen integriert Daten von Lieferanten, Produktionsanlagen und Logistikpartnern, um Überwachung der gesamten Lieferkette in Echtzeit. Dies hilft, Engpässe zu erkennen, Verzögerungen zu verringern und die Bestandsverwaltung zu optimieren.
Vorteile der Datenintegration
Die Datenintegration hilft Unternehmen, Abläufe zu rationalisieren, die Zusammenarbeit zu verbessern und Daten besser zu analysieren. Durch die Zusammenführung von Informationen können Unternehmen mehr Erkenntnisse gewinnen und die betriebliche Effizienz verbessern. Im Folgenden finden Sie einige der spezifischen Vorteile der Integration:
- Verbesserte Zugänglichkeit der Daten: Integrierte Systeme bieten eine zentrale Sicht auf die Daten und erleichtern den Benutzern den Zugriff auf die benötigten Informationen, ohne dass sie zwischen verschiedenen Tools oder Datenbanken hin- und herspringen müssen.
- Besser informierte Entscheidungsfindung: Mit Sicherheit, Echtzeitdatenkönnen Teams vertrauensvoll Geschäftsentscheidungen treffen und schnell auf Veränderungen und neue Möglichkeiten reagieren.
- Gesteigerte betriebliche Effizienz: Die Automatisierung des Datenflusses verringert die Notwendigkeit der manuellen Dateneingabe, erspart den Teams sich wiederholende, eintönige Aufgaben und spart Ressourcen für strategische Initiativen.
- Verbesserte Datenqualität: Durch die Datenintegration werden Daten aus verschiedenen Quellen standardisiert und bereinigt, wodurch Fehler, Duplikate und Inkonsistenzen in verschiedenen Systemen reduziert werden.
- Bessere Zusammenarbeit zwischen Teams: Wenn alle Abteilungen mit denselben Daten arbeiten, verbessern sich die Abstimmung und die Kommunikation, was zu einer besseren Zusammenarbeit und einem produktiveren Umfeld führt.
- Verbesserte Skalierbarkeit: Integrierte Systeme lassen sich leichter skalieren, wenn die geschäftlichen Anforderungen wachsen, und machen es einfacher, neue Tools, Plattformen oder Datenquellen zu integrieren.
- Unterstützung für Analytik und KI: Saubere, einheitliche Datensätze sind für präzise Business Intelligence, prädiktive Analysen und maschinelles Lernen unerlässlich.
- Verbesserte Compliance und Sicherheit: Eine zentralisierte Datenverwaltung erleichtert die Durchsetzung von Data-Governance-Richtlinien, die Verfolgung der Datenherkunft und die Einhaltung von Datenschutzbestimmungen.
Herausforderungen bei der Datenintegration
So vorteilhaft die Datenintegration auch sein mag, so schwierig kann ihre Umsetzung sein, insbesondere wenn die Systeme, Datenquellen und Geschäftsanforderungen komplex sind. Aus diesem Grund ist es für den Integrationsprozess von entscheidender Bedeutung, die Herausforderungen im Voraus zu planen. Worauf Sie sich vorbereiten sollten, erfahren Sie hier:
- Datensilos und Inkompatibilität: Die Integration von Daten aus unverbundenen Systemen oder älteren Plattformen kann aufgrund unterschiedlicher Formate, Strukturen und Technologien schwierig sein.
- Probleme mit der Datenqualität: Inkonsistente, unvollständige oder doppelte Daten können zu ungenauen Ergebnissen führen, wenn sie bei der Integration nicht ordnungsgemäß bereinigt und validiert werden.
- Komplexität der Echtzeit-Integration: Die Synchronisierung von Daten in Echtzeit oder nahezu in Echtzeit erfordert eine fortschrittlichere Infrastruktur und fortschrittlichere Tools, was häufig die Kosten und die Komplexität der Integration erhöht.
- Hohe Implementierungskosten: Je nach Größe und Umfang können Integrationsprojekte ressourcenintensiv sein und Investitionen in Tools, Berater und laufende Wartung erfordern.
- Bedenken hinsichtlich der Skalierbarkeit: Die Aufrechterhaltung der Leistungsqualität und die Sicherstellung der Skalierbarkeit Ihres zentralen Systems kann mit zunehmendem Datenvolumen zu einer Herausforderung werden.
- Sicherheits- und Compliance-Risiken: Das Verschieben und Kombinieren von Daten aus mehreren Systemen kann zu Schwachstellen führen, wenn keine angemessenen Zugriffskontrollen, Verschlüsselungs- und Konformitätsmaßnahmen vorhanden sind.
- Fragen der Governance: Die Ausrichtung von Teams, Prozessen und Richtlinien auf integrierte Daten-Workflows kann ohne einen klaren Governance-Rahmen und organisatorische Unterstützung schwierig sein.
- Auswahl der Werkzeuge: Die Wahl der richtigen Datenintegrationsplattform oder des richtigen Tools erfordert eine sorgfältige Evaluierung, um sicherzustellen, dass es zur technischen Umgebung und den Geschäftszielen des Unternehmens passt.
Werkzeuge zur Datenintegration
Diese Tools extrahieren Daten aus verschiedenen Quellen, wandeln sie in ein standardisiertes Format um und laden sie in ein zentrales System.
- ELT (Extrahieren, Laden, Transformieren): Google Cloud Dataflow, AWS Glue und Fivetran sind ideal für Umgebungen, in denen Daten in ein Data Warehouse oder einen Data Lake geladen und dann nach Bedarf transformiert werden. Diese Tools sind besonders nützlich für die Cloud-basierte Datenintegration.
- Null-ETL (Extrahieren, Transformieren, Laden): Amazon Aurora Zero-ETL mit Amazon Redshift und Google BigQuery Data Transfer Service vereinfacht die Datenpipeline, indem es traditionelle ETL-Prozesse überflüssig macht. Er ermöglicht eine nahezu sofortige Datenübertragung zwischen Systemen und reduziert Latenzzeiten und Wartungsaufwand.
- API-basierte Integration: Unternehmen können Tools wie MuleSoft Anypoint Platform, Dell Boomi und Zapier verwenden, um Workflows zu automatisieren und verschiedene Anwendungen über APIs zu integrieren.
- Datenintegration in Echtzeit: Apache Kafka, AWS Kinesis und Google Cloud Pub/Sub sind Daten-Streaming-Tools, die für die Verarbeitung eines kontinuierlichen Datenflusses konzipiert sind und sich daher perfekt für Szenarien eignen, die eine Datenverarbeitung in Echtzeit erfordern.
- Hybride Datenintegration: Unternehmen können Talend Cloud, Oracle Data Integrator (ODI) und Microsoft Azure Data Factory nutzen, um Wolke integrieren und Vor-Ort-Systemen und gewährleistet einen nahtlosen Datenaustausch über verschiedene Umgebungen hinweg.
Eine vollständige Aufschlüsselung des Datenintegrationsprozesses
Planung für die Datenintegration
Legen Sie Ihre Datenziele klar fest, bestimmen Sie die Datenquellen (z. B. Datenbanken, APIs) und ermitteln Sie andere relevante Tools. In dieser Phase sollten Sie auch ein Data Governance Framework für Sicherheit, Compliance und Datenqualität einrichten.
Umwandlung von Daten mithilfe von KI-Technologien
Sie können KI nutzen, um Muster zu erkennen, Inkonsistenzen zu bereinigen und Daten zu verbessern, indem fehlende Werte ergänzt oder Standardformate vorgeschlagen werden. Sie kann auch Felder zwischen verschiedenen Datenquellen zuordnen, wodurch der Umwandlungsprozess schneller und genauer wird und sich an Änderungen im Laufe der Zeit anpassen lässt.
Verlassen Sie sich auf die Erfassung von Daten in Echtzeit
Verwenden Sie Echtzeit-Dateneingabe um Daten aus verschiedenen Quellen zu sammeln, zu verarbeiten und zu integrieren, sobald sie generiert werden. Dieser Ansatz ermöglicht minutengenaue Einblicke und Entscheidungsfindung und unterstützt dynamische Umgebungen wie Finanzen, E-Commerce und IoT, indem Daten kontinuierlich synchronisiert werden, ohne auf Batch-Updates zu warten.
Nutzung der Cloud-Native-Integration
Nutzen Sie Cloud-native Infrastrukturen wie Data Lakes oder Warehouses, um Daten über verteilte Systeme hinweg zu verbinden, zu transformieren und zu verwalten. Dies ermöglicht eine nahtlose Integration zwischen Cloud-Anwendungen, On-Premise-Systemen und Datenquellen, oft mit reduziertem Infrastruktur-Overhead und integrierter Unterstützung für moderne Workflows.
Sicherstellung der Genauigkeit durch Analyse und Überwachung
Verfolgen Sie nach der Integration die Analysen und überwachen Sie kontinuierlich die Datenleistung, um die Genauigkeit und Konsistenz des Systems sicherzustellen. Die Nachverfolgung Ihrer Daten hilft bei der Erkennung von Anomalien, der Überwachung der Effizienz des Datenflusses und bietet Einblicke in den Systemzustand, was eine schnelle Problemlösung und kontinuierliche Verbesserungen ermöglicht.
Die wichtigsten Erkenntnisse
- Die Datenintegration ist entscheidend für einheitliche Erkenntnisse: Die Kombination von Daten aus verschiedenen Quellen gewährleistet, dass Unternehmen einen vollständigen und genauen Überblick für ihre Geschäftsentscheidungen erhalten.
- Die strategische Planung ist die Grundlage: Der Schlüssel zum Erfolg ist eine gut definierte Strategie, die eine frühzeitige Vorbereitung auf Hindernisse, die Ermittlung von Datenquellen, die Auswahl von Integrationstools und die Festlegung von Governance-Richtlinien umfasst.
- KI und Automatisierung steigern die Effizienz: Das maschinelle Lernen rationalisiert die Zuordnung, Umwandlung und Erkennung von Anomalien von Daten, reduziert manuelle Fehler und beschleunigt Prozesse.
- Die Verarbeitung in Echtzeit ermöglicht eine schnellere Entscheidungsfindung: Daten-Streaming-Tools wie Apache Kafka und AWS Kinesis ermöglichen es Unternehmen, sofort auf neue Daten zu reagieren.
- Cloud-native Lösungen bieten Skalierbarkeit: Cloud Data Warehouses (Snowflake, BigQuery) und Data Lakes bieten flexible, kosteneffiziente Möglichkeiten zur Verwaltung umfangreicher Datenintegration.
- Datenqualität und Governance sind entscheidend: Laufende Überwachung, Einhaltung von Vorschriften (GDPR, HIPAA) und Sicherheitsmaßnahmen gewährleisten, dass die Daten zuverlässig und sicher bleiben.
- Eine wirksame Integration schafft geschäftlichen Mehrwert: Integrierte Daten ermöglichen Business Intelligence, prädiktive Analysen und KI-gesteuerte Erkenntnisse.
Mit dem Bau beginnen
Besuchen Sie unser Entwicklerportal, um NoSQL zu erkunden, Ressourcen zu durchsuchen und mit Tutorials zu beginnen.

Capella kostenlos nutzen
Mit nur wenigen Klicks können Sie Couchbase in die Praxis umsetzen. Capella DBaaS ist der einfachste und schnellste Weg, um loszulegen.

Kontakt aufnehmen
Möchten Sie mehr über das Angebot von Couchbase erfahren? Wir helfen Ihnen gerne.