
概要
データ統合は、異なるソースからのデータをターゲットシステムに統合する。データ統合には、データの抽出、変換、ロード、同期、ガバナンスなどいくつかの段階があり、それぞれがデータの正確性、一貫性、実用性を保証します。データ統合の種類には、アプリケーション統合、データウェアハウス、仮想化などがある。Amazon AuroraのようなAmazon RedshiftとのゼロETLやApache Kafkaのようなデータストリーミングツールは、統合プロセスを迅速化するために使用されます。統合は、データ品質の向上、洞察の迅速化、コラボレーションの改善といった大きなメリットをもたらす一方で、データのサイロ化、導入コスト、ガバナンスの問題といった課題も伴う。組織の価値を最大化するためには、データ統合プロセスを開始する前に、潜在的な欠点を理解しておくことが極めて重要です。
データ統合とは何か?
データ統合とは、異なるソースからのデータを統合ビューにまとめるプロセスである。複数のシステム(データベース、アプリケーション、データウェアハウスなど)からデータを抽出し、互換性のある形式に変換し、中央システムにロードします。データ統合は、アクセシビリティ、一貫性、信頼性を向上させ、より良い分析、報告、意思決定につながります。
データ統合、その利点と限界、データ統合を促進するために使用できるツールについて、このリソースをお読みください。
データ統合はどのように機能するのか?
データ統合は、さまざまなソースからのデータを全体的なビューに統合し、分析、レポーティング、意思決定を容易にします。データ統合は、データの抽出、変換、ロード、同期、ガバナンスを含むプロセスに依存しています。
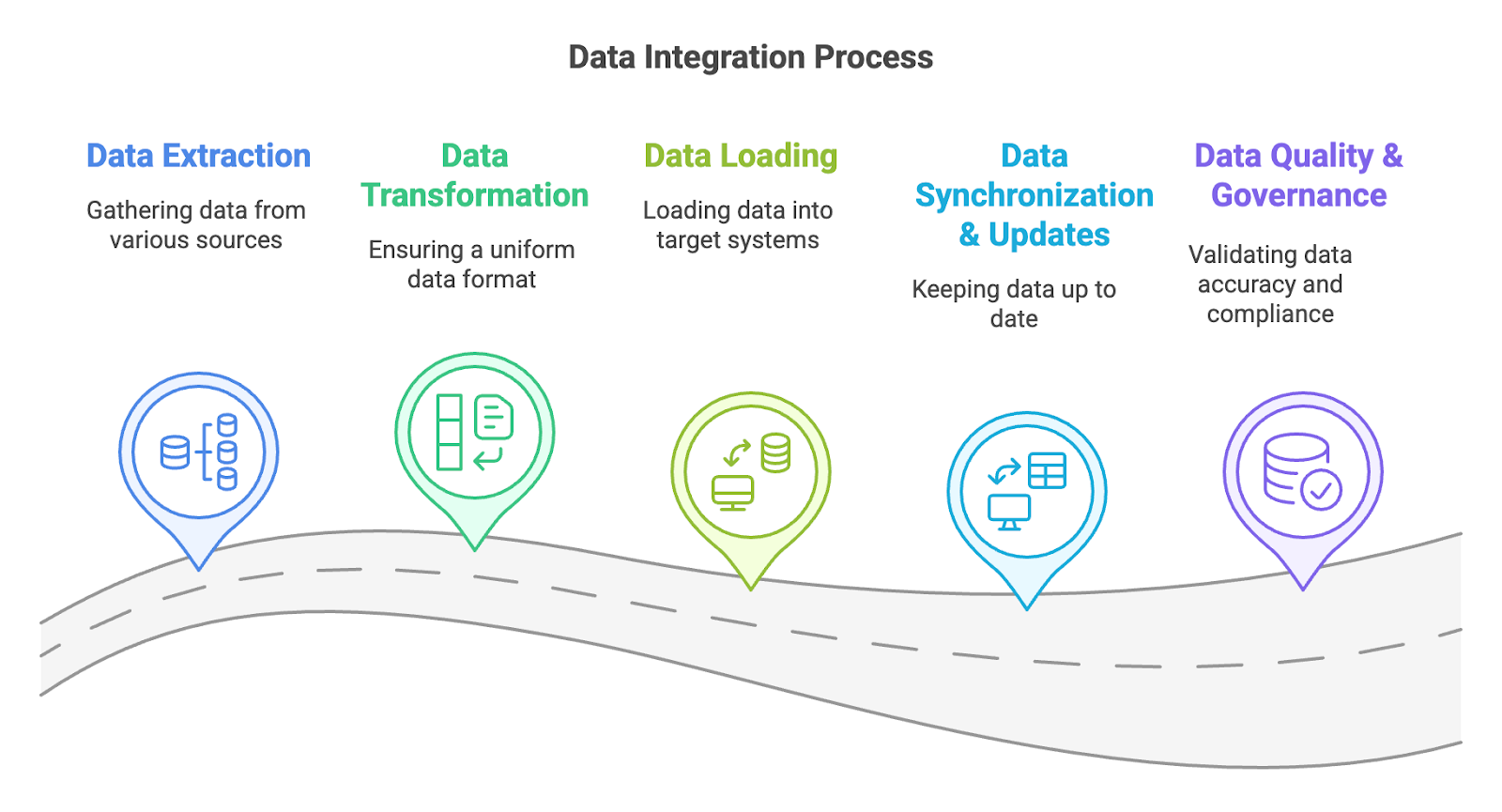
データ抽出
データ抽出の段階では、以下のデータからデータを取り出す。 データベース, クラウドサービスAPI、フラットファイル(CSVやExcelなど)、レガシープラットフォームなど。このステップでは、元のソースを変更せずに関連データを収集することに重点を置きます。まずデータが存在する場所を特定し、次に適切な抽出方法(すべてのデータを一度に取得する完全抽出、または前回の統合以降に新規または更新されたデータのみを取得する増分抽出)を選択します。このプロセスにおいてデータの整合性を維持することは、正確性と一貫性を確保するために極めて重要です。自動化ツールやカスタムスクリプトを使用してソースに接続し、必要なデータを抽出することで、後続の変換およびロードフェーズの土台を築くことがよくあります。
データ変換
データ変換の段階では、抽出されたデータを中央システムで一貫性のある使用可能な形式に変換する。これには、重複の除去、エラーの修正、欠損値の処理、日付と時刻、通貨、測定単位などのフォーマットの標準化など、データのクリーニングが含まれる。また、コンテキストや派生値を追加するデータエンリッチメントや、異なるソースのフィールドを統一スキーマに整合させるデータマッピングも含まれる。このフェーズでは、統合されたデータが正確で互換性があることを確認し、分析、報告、または中央システムでのさらなる処理に対応できるようにします。
データロード
データローディングフェーズでは、変換されたデータを次のような中央システムに転送する。 データウェアハウスデータレイク 分析プラットフォーム.このステップにより、クリーニングされ標準化されたデータが一元化された場所に保存され、レポート作成、分析、その他の操作にアクセスして使用できるようになります。システムと要件に応じて、データはスケジュールされた間隔でバッチ的に、またはリアルタイム(ストリーミング)で連続的にロードすることができる。このプロセスには、ロードされたデータが正しく転送されたかどうかの検証も含まれます。効率的で信頼性の高いデータロードにより、最終的な統合データセットの正確性、最新性、使用可能性が保証されます。
データの同期と更新
データの同期と更新の段階では、ソース・システムで行われた変更と中央システムの整合性が保たれるようにします。定期的に新しいデータ、変更されたデータ、削除されたデータをチェックし、それに応じて統合データを更新することで、すべてのシステムで一貫性を維持します。同期化は、ビジネスニーズや技術的な設定に応じて、リアルタイムまたはスケジュールされた間隔で行うことができます。同期には、競合の解決、バージョン管理、変更を追跡してデータの正確性を保証する監査証跡などのメカニズムが含まれます。このフェーズは、特にデータが頻繁に変更されるダイナミックな環境において、統合データの信頼性を維持するために不可欠です。
データ品質とガバナンス
データ品質とガバナンスの段階では、統合されたデータが正確であり、組織のポリシーや外部規制に準拠していることを保証する。これには、データの整合性を検証し、エラーを検出して修正し、データセット間で標準化された形式を維持するためのルールとチェックの実施が含まれる。データガバナンスには、データへのアクセス、セキュリティ、利用を管理するための役割、責任、手順の定義も含まれる。この段階には、メタデータの管理、データのリネージの文書化、GDPRやHIPAAなどのデータプライバシー法へのコンプライアンスの実施などが含まれる。最終的には、統合されたデータの信頼性を維持し、ビジネス目標や法的要件に沿うようにします。
データ統合の種類
データ統合にはいくつかの種類があり、それぞれが特定のビジネスニーズや技術環境に対応するように設計されている。これらの統合タイプはそれぞれ目的が異なり、多くの場合、組織は複雑なデータ要件を満たすためにこれらを組み合わせて使用します。
手動によるデータ統合
データ統合の最も基本的な形態は、ユーザーが手作業でデータを収集し、統合することである。単純ではあるが、このプロセスは時間がかかり、人為的なミスが発生しやすいため、小規模なプロジェクトや1回限りのプロジェクトにのみ適している。
ミドルウェアのデータ統合
ミドルウェアはシステム間の橋渡し役として機能し、リアルタイムでの通信やデータ共有を可能にする。ミドルウェアは、異なるアプリケーションがシームレスに連携しなければならない企業環境で一般的に使用されている。
アプリケーションの統合
この方法では、内蔵の コネクタまたはAPI 他のシステムとのデータ転送や同期を行う。柔軟性があり、クラウドベースのプラットフォームやSaaSソリューションの統合によく使われる。
統一されたデータアクセスの統合
このアプローチは、データを物理的に移動させることなく、統一されたビューを提供する。その代わり、複数のシステムにまたがるデータにリアルタイムでアクセスし、クエリーを実行するため、データを重複させることなく、迅速な洞察を必要とする組織にとって有用である。
共通ストレージ統合(データウェアハウス)
一般的なストレージ統合では、様々なソースからのデータが抽出、変換され、中央リポジトリ(多くの場合データウェアハウス)にロードされる。このプロセスは、ビジネスインテリジェンス、履歴分析、レポーティングに最適です。
データ仮想化
データの仮想化によって抽象的なレイヤーが形成され、ユーザーは複数のソースからあたかも1つの場所にあるかのようにデータにアクセスし、分析することができる。データの物理的な移動を最小限に抑え、リアルタイムの洞察へのアクセスにおける俊敏性とスピードを向上させます。
データ統合の例
データ統合は、業務の改善、洞察の獲得、十分な情報に基づいた意思決定のために、あらゆる業界で活用されています。ここでは、データ統合が顧客エンゲージメント、eコマース、ヘルスケア、金融サービス、サプライチェーンマネジメントをどのように改善するのか、いくつかの例をご紹介します。
カスタマー360
ある企業は、CRM、ウェブサイト分析、ソーシャルメディアプラットフォーム、Eメールマーケティングツールのデータを統合して、次のようなものを作成した。 統一顧客プロファイル.統合により、リアルタイムの行動や嗜好に基づいてパーソナライズされたマーケティングキャンペーンや、より良い顧客エンゲージメントが可能になる。
注文管理
オンライン小売業者は、ウェブサイト、在庫データベース、配送業者、および決済ゲートウェイからのデータを統合して、次のことを行います。 注文処理の合理化.統合により、正確な在庫追跡、より迅速な出荷、より良いカスタマーサービスが実現します。
患者記録
A病院 患者データを統合 検査結果、画像システム、電子カルテ(EHR)のような複数の部門から、1つの集中システムに統合する。こうすることで、医師は患者の病歴を完全に把握できるようになり、診断や治療方針の決定が向上する。
財務報告
財務部門は、複数の会計プラットフォーム、経費追跡ツール、給与システムから中央データウェアハウスにデータを統合する。このデータを統合することで、次のことが可能になります。 一貫した財務報告コンプライアンス・チェック、より正確な予測。
サプライチェーンマネジメント(SCM)
製造会社は、サプライヤー、生産施設、物流パートナーからのデータを統合して、次のことを行う。 サプライチェーン全体を監視する をリアルタイムで表示します。こうすることで、ボトルネックを特定し、遅延を減らし、在庫管理を最適化することができる。
データ統合のメリット
データ統合は、組織が業務を合理化し、コラボレーションを改善し、データをより良く分析するのに役立ちます。情報を一元化することで、企業はより多くの洞察を引き出し、業務効率を向上させることができる。以下は、統合がもたらす具体的な利点の一部です:
- データアクセシビリティの向上: 統合されたシステムは、データの一元的なビューを提供し、ユーザーが複数のツールやデータベースを飛び越えることなく、必要な情報にアクセスすることを容易にします。
- より良い情報に基づいた意思決定: 信頼できる、 リアルタイムデータチームは自信を持ってビジネス上の意思決定を行い、変化や新たな機会に迅速に対応することができる。
- 業務効率の向上: データフローを自動化することで、手作業によるデータ入力の必要性が減り、チームは反復的で単調な作業に従事する必要がなくなり、戦略的イニシアチブのためのリソースを節約できる。
- データ品質の向上: データ統合は、様々なソースからのデータを標準化、クレンジングし、システム間のエラー、重複、不整合を減らします。
- チーム間のより良いコラボレーション: すべての部門が同じデータを扱うことで、連携とコミュニケーションが改善され、より協力的で生産的な環境が育まれる。
- スケーラビリティの向上: 統合されたシステムは、ビジネスニーズの成長に合わせて拡張しやすく、新しいツール、プラットフォーム、データソースの導入がより簡単になる。
- アナリティクスとAIのサポート: クリーンで統一されたデータセットは、正確なビジネスインテリジェンス、予測分析、機械学習に不可欠です。
- コンプライアンスとセキュリティの向上 データの一元管理により、データガバナンスポリシーの実施、データのリネージの追跡、プライバシー規制の遵守が容易になります。
データ統合の課題
システム、データソース、ビジネスニーズが複雑な場合は特にそうです。このため、事前に課題を計画することは、統合プロセスにとって非常に重要です。ここでは、準備すべきことを説明します:
- データのサイロ化と非互換性: 分離されたシステムやレガシー・プラットフォームからのデータ統合は、フォーマット、構造、テクノロジーが異なるために困難な場合がある。
- データの質の問題: 一貫性のない、不完全な、または重複したデータは、統合時に適切にクリーニングおよび検証されない場合、不正確な結果につながる可能性があります。
- リアルタイム統合の複雑さ: リアルタイムまたはほぼリアルタイムのデータ同期を可能にするには、より高度なインフラとツールが必要であり、多くの場合、コストと統合の複雑さを増大させる。
- 高い導入コスト: 規模や範囲にもよるが、統合プロジェクトは、ツール、コンサルタント、継続的なメンテナンスへの投資を必要とし、リソースを集約することができる。
- スケーラビリティへの懸念: パフォーマンス品質を維持し、中央システムの拡張性を確保することは、データ量が増加するにつれて難しくなります。
- セキュリティとコンプライアンスのリスク: 適切なアクセス制御、暗号化、コンプライアンス対策が施されていなければ、複数のシステムからデータを移動させたり組み合わせたりすることで脆弱性が生じる可能性がある。
- ガバナンスの問題 統合されたデータワークフローを中心に、チーム、プロセス、ポリシーを調整することは、明確なガバナンスフレームワークと組織のサポートがなければ難しい。
- ツール選択: 適切なデータ統合プラットフォームやツールを選択するには、それが組織の技術環境やビジネス目標に適合しているかどうかを慎重に評価する必要がある。
データ統合ツール
これらのツールは、様々なソースからデータを抽出し、標準化されたフォーマットに変換し、中央システムにロードする。
- ELT(抽出、負荷、変換): Google Cloud Dataflow、AWS Glue、Fivetranは、データがデータウェアハウスやデータレイクにロードされ、必要に応じて変換される環境に最適である。これらのツールは、クラウドベースのデータ統合に特に有効だ。
- ゼロETL(抽出、変換、ロード): Amazon Aurora ゼロETL with Amazon Redshift and Google BigQuery Data Transfer Service は、従来のETLプロセスを不要にし、データパイプラインを簡素化します。システム間のほぼ瞬時のデータ移動を可能にし、レイテンシーとメンテナンスを削減します。
- APIベースの統合: 企業は、MuleSoft Anypoint Platform、Dell Boomi、Zapierなどのツールを使用して、ワークフローを自動化し、APIを通じてさまざまなアプリケーションを統合できる。
- リアルタイムのデータ統合: Apache Kafka、AWS Kinesis、Google Cloud Pub/Subは、継続的なデータフローを処理するように設計されたデータストリーミングツールであり、リアルタイムのデータ処理を必要とするシナリオに最適である。
- ハイブリッドデータ統合: 組織は、Talend Cloud、Oracle Data Integrator(ODI)、Microsoft Azure Data Factoryを使用して、以下を行うことができます。 インテグレートクラウド とオンプレミスのシステムで、異なる環境間でのシームレスなデータ交換を保証する。
データ統合プロセスの完全な内訳
データ統合の計画
データ目的を明確に定義し、データソース(データベース、APIなど)を特定し、その他の関連ツールを特定する。このフェーズでは、セキュリティ、コンプライアンス、データ品質に関するデータガバナンスのフレームワークも確立する必要があります。
AI技術によるデータ変換
AIを使ってパターンを検出し、矛盾を取り除き、欠落値を埋めたり標準フォーマットを提案したりしてデータを改善することができる。また、異なるデータ・ソース間のフィールドをマッピングし、変換プロセスをより迅速かつ正確にし、時間の経過に伴う変化に適応させることもできる。
リアルタイムのデータ取り込みに頼る
用途 リアルタイムデータ取り込み は、さまざまなソースからデータが生成されると、それを収集、処理、統合します。このアプローチにより、分刻みの洞察と意思決定が可能になり、バッチ更新を待つことなく継続的にデータを同期することで、金融、eコマース、IoTなどのダイナミックな環境をサポートします。
クラウドネイティブ統合の活用
データレイクやウェアハウスのようなクラウドネイティブなインフラを活用して、分散システム全体のデータを接続、変換、管理する。これにより、クラウドアプリケーション、オンプレミスシステム、データソース間のシームレスな統合が可能になり、多くの場合、インフラストラクチャーのオーバーヘッドが削減され、最新のワークフローがビルトインでサポートされます。
分析とモニタリングによる正確性の確保
統合後は、分析結果を追跡し、データパフォーマンスを継続的に監視して、システムの正確性と一貫性を確保します。データを追跡することで、異常を検出し、データフローの効率を監視し、システムの健全性に関する洞察を提供し、迅速な問題解決と継続的な改善を可能にします。
要点
- データの統合は、統一された洞察のために極めて重要である: 複数のソースからのデータを組み合わせることで、ビジネス上の意思決定を行うための完全で正確なビューが確保される。
- 戦略的計画は基礎である: 成功の鍵は、事前に障害に備えること、データソースを特定すること、統合ツールを選択すること、ガバナンスポリシーを設定することなど、明確に定義された戦略である。
- AIと自動化は効率を向上させる: 機械学習はデータマッピング、変換、異常検知を合理化し、手作業によるミスを減らし、プロセスをスピードアップします。
- リアルタイム処理は、より迅速な意思決定を可能にする: Apache KafkaやAWS Kinesisのようなデータ・ストリーミング・ツールによって、企業は新しいデータに即座に対応することができる。
- クラウドネイティブ・ソリューションはスケーラビリティを提供する: クラウドデータウェアハウス(Snowflake、BigQuery)とデータレイクは、大規模なデータ統合を管理するための柔軟でコスト効率の高い方法を提供する。
- データの品質とガバナンスは非常に重要である: 継続的なモニタリング、規制(GDPR、HIPAA)へのコンプライアンス、セキュリティ対策により、データの信頼性と安全性を維持します。
- 効果的な統合はビジネス価値を提供する: 統合されたデータは、ビジネスインテリジェンス、予測分析、AI主導の洞察力を強化します。

